本文提出了 VideoAtlas 框架,这是一种将长视频理解重构为在递归层级网格(Hierarchical Grid)中导航的任务无关环境。通过配合并行的 Master-Worker 代理架构 Video-RLM,该方法在处理长达 10 小时的视频时,实现了计算量随视频长度对数增长(Logarithmic Growth),并保持了极高的精度稳定性。
TL;DR
传统的长视频 AI 就像是在读一本没有索引、只能一页页翻的巨型书,要么翻得太快(采样过稀)丢了细节,要么翻得太慢(处理过久)耗尽内存。VideoAtlas 颠覆了这一逻辑,它将长视频转换成了一张可以无限缩放的“数字地图”。通过递归网格技术,它让 AI 能够以 的极低复杂度,在 10 小时视频中精准“空降”关键帧。相比传统方法,其计算成本降低了近 10 倍,且视觉保真度毫无损失。
1. 痛点深挖:采样与保真度的“生死权衡”
当前处理长视频的业界方案主要面临三个困境:
- 覆盖率 vs. 分辨率的死结:在固定的 Context Window 下,如果你想看清每一秒(高采样率),图像质量就必须降到模糊;如果你想看清细节(高分辨率),就只能每隔几分钟抽一张图,导致短时关键事件被系统性遗漏。
- “丢失在翻译中”:许多 Agent 架构先将视频转成 Caption(文本摘要),但文本无法承载所有视觉细节。一旦第一步 Caption 没写好,后面的推理再强也无法溯源。
- 线性成本爆炸:1 小时视频的 Preprocessing(预处理)往往需要数百 GB 内存,处理 10 小时视频的成本几乎是不可接受的线性增长。
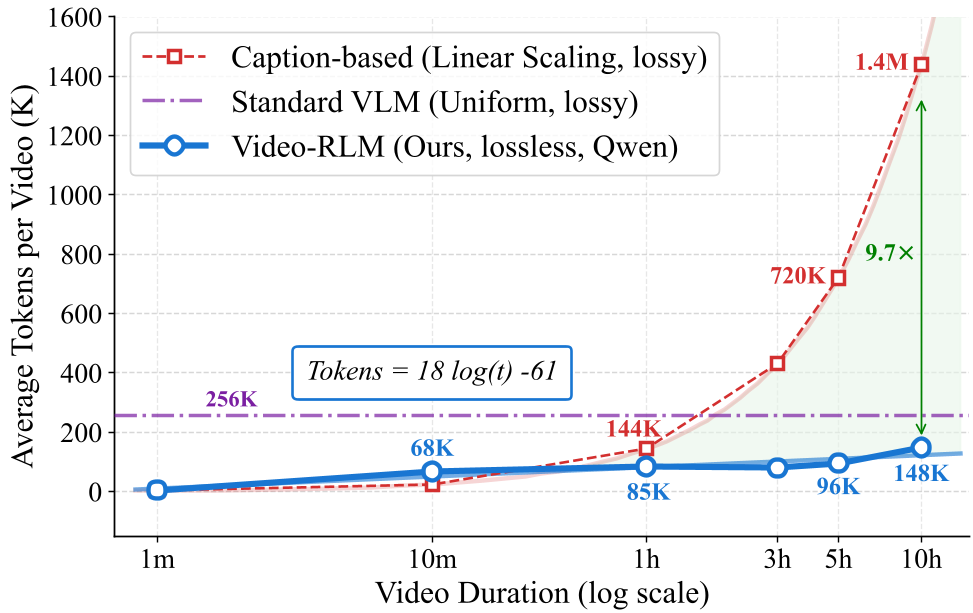 图 1:Video-RLM 的计算量随视频长度呈对数增长(红线),远低于基线的线性增长。
图 1:Video-RLM 的计算量随视频长度呈对数增长(红线),远低于基线的线性增长。
2. Methodology:VideoAtlas 的视觉导航哲学
VideoAtlas 的核心直觉源于电影剪辑师:先看一张缩略图总览(Contact Sheet),发现感兴趣的部分再点进去看高清。
核心架构:Hierarchical Grid
论文将视频建模为一个 的递归图像网格(默认 )。
- 根节点 (Root Grid):覆盖全片 64 个关键采样点。
- 动作空间 (Action Space):智能体可以执行
EXPAND(ci)动作,对特定网格单元进行“递归下钻”。 - 性能优势:对于 10 小时的视频,由于是指数级细分,仅需 2-3 层深度即可达到亚秒级的时间精度。
智能体协作:Master-Worker 架构
为了高效利用计算资源,作者引入了 Video-RLM:
- Master (大脑):分析根网格,基于不确定性分析判断哪里值得探索,并指派任务。
- Workers (触手):并行对子网格进行深度探测,负责采集视觉证据并存入 Visual Scratchpad。
- Visual Scratchpad (草稿本):这是一个无损的“视觉记忆体”,存储的是带时间戳的高清帧和感知描述,彻底抛弃了中间文本。
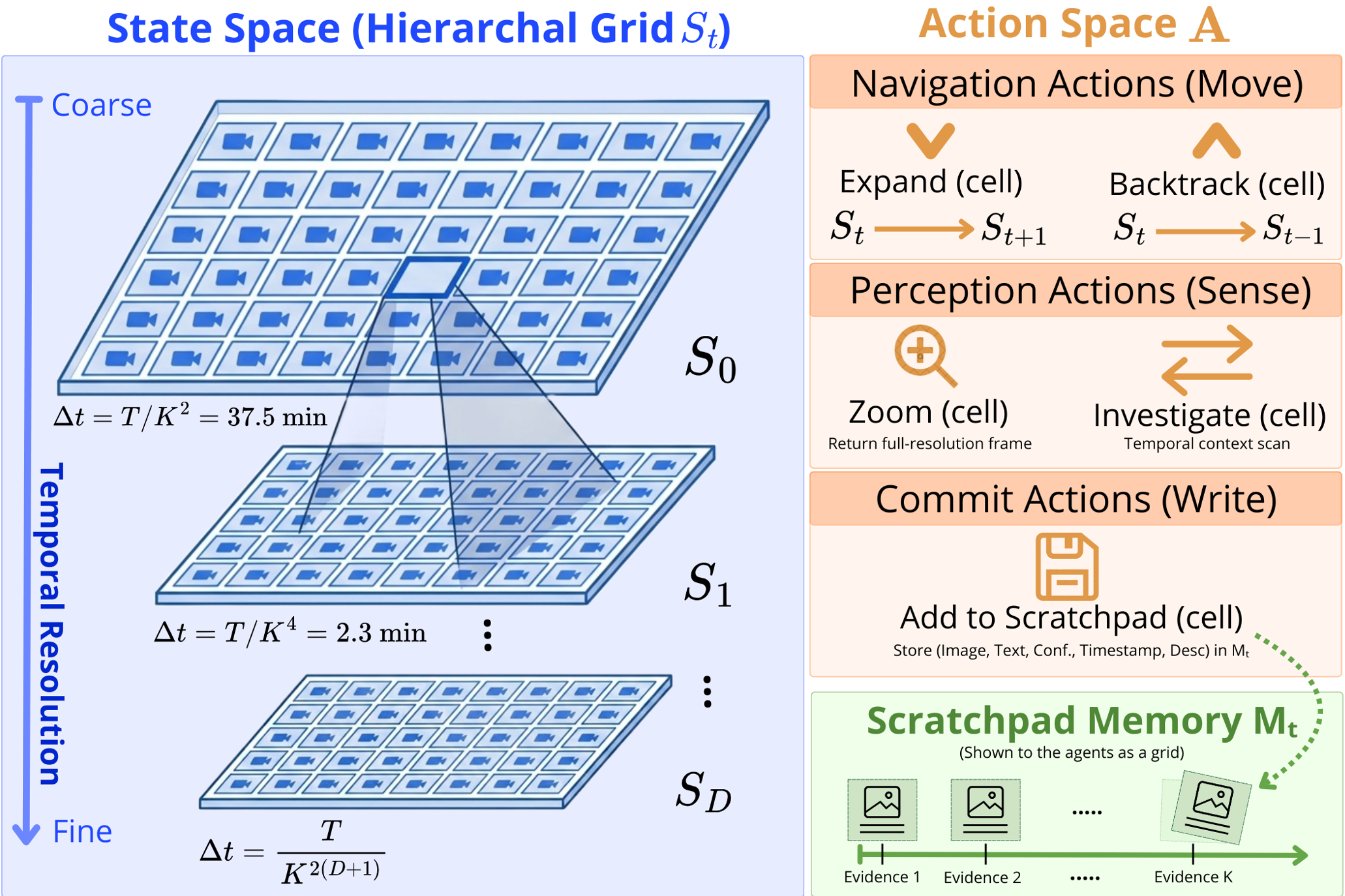 图 2:VideoAtlas 环境定义:分级导航栈、离散动作空间及视觉草稿本。
图 2:VideoAtlas 环境定义:分级导航栈、离散动作空间及视觉草稿本。
3. 实验战绩:10 小时视频的“定海神针”
在扩展至 10 小时的 LongVideoBench-10hr 和 Video-MME 挑战中,VideoAtlas 展现了恐怖的鲁棒性:
- 精度稳定性:当视频从 1 小时拉长到 10 小时,传统 Caption 方案在 VMME 上的准确率暴跌 28.2%(因为 Caption 太长撑爆了上下文窗口),而 Video-RLM 仅下降 0.7%。
- 缓存红利:由于网格结构在递归过程中高度复用,在 vLLM 推理框架下实现了高达 30%-60% 的 Prefix Cache 命中率。这意味着虽然逻辑上处理了更多次图像,但实际 GPU 算力开销被大幅抵消。
- 自适应计算 (Emergent Adaptive Compute):模型展现出一种神奇的特性——面对分散的证据(Scattered Answers),它会自动消耗更多 Token 进行深度搜索;而对于集中式的证据,它会快速收敛并停止。
 图 3:10 小时视频基准测试结果。Video-RLM 在不同时长下的表现极其稳定。
图 3:10 小时视频基准测试结果。Video-RLM 在不同时长下的表现极其稳定。
4. 深度洞察:为什么这很重要?
VideoAtlas 不仅仅是一个刷榜的模型,它提供了一个将无限视频流转化为结构化环境的通用协议。
- 环境预算化 (Environment Budgeting):过去我们调节模型性能只能靠缩放参数或采样率,现在我们可以通过控制“搜索深度 ”来精细化调节计算预算。
- 迈向视觉强化学习 (RL):由于将视频理解定义为了 MDP,这为未来的自动化探索开辟了道路。现在的 Worker 还是 Zero-shot 的,如果未来用 PPO 或 DQN 训练,探索效率将进一步飞跃。
- 解耦感知与调度:实验证明,即使换用更强的 Backone(如从 Qwen 换到 Gemini-Flash),VideoAtlas 的框架依然能稳定带来性能增益,证明了这种调度逻辑的通用价值。
5. 总结与局限
尽管 VideoAtlas 在长视频领域取得了重大突破,但其性能上限仍受限于 Backbone VLM 的原始感知能力(如对细微文本的辨识)。此外,如果视频没有任何明显的视觉锚点,初始的全局探测(Global Probing)可能会消耗额外的回合。
结论:VideoAtlas 证明了——理解长视频不需要“死记硬背”所有帧,只需要一套科学的“地图索引”和灵活的“缩放镜头”。这正是实现通用长视频智能的必经之路。