VideoNet is a large-scale benchmark for domain-specific action recognition, encompassing 1,000 actions across 37 diverse domains. The authors introduce a specialized 500k video-QA training dataset and demonstrate that fine-tuning a Molmo2-4B model enables it to outperform many 8B-parameter state-of-the-art models.
Executive Summary
TL;DR: VideoNet is a massive new benchmark designed to test if AI truly understands what is happening in a video, rather than just identifying the objects within it. By covering 1,000 actions (from "Double Axel" in skating to "Double Crochet" in crafts) across 37 domains, it exposes a massive performance gap between humans and the best AI models. While open-weight models initially fail this test, the authors prove that specialized, automated data collection can bridge the gap, allowing a 4B model to beat 8B giants.
Background: This work shifts the focus from "general video understanding" (which has become saturated) back to Domain-Specific Action Recognition. It sits at the intersection of dataset engineering and VLM evaluation, challenging the current industry assumption that larger models naturally learn complex actions from the web.
The Problem: Perception vs. Recognition
Ancient philosophy (Aquinas) said: "Who knows not motion, knows not nature." Modern VLMs, unfortunately, mostly know "objects." Current benchmarks like Kinetics are too coarse; a model only needs to see a "climbing wall" to guess "rock climbing."
The authors argue that current models fail at compositional reasoning. To distinguish a "triple flip jump" from a "Salchow jump" in figure skating, a model must notice the specific use of a toepick. Standard VLMs treat video as a series of images, often ignoring these subtle temporal nuances.
Methodology: Building the Expert's Eye
The authors didn't just scrape YouTube; they built a hierarchy.
- Taxonomy: LLM-augmented lists of actions verified against expert blogs.
- Hard Negatives: Instead of comparing "Basketball" to "Tennis," they compare "Alley-oop Dunk" to "Put-back Dunk."
- Human-in-the-loop: A three-stage pipeline (Collection -> Verification -> Trimming) ensuring 97%+ label accuracy.
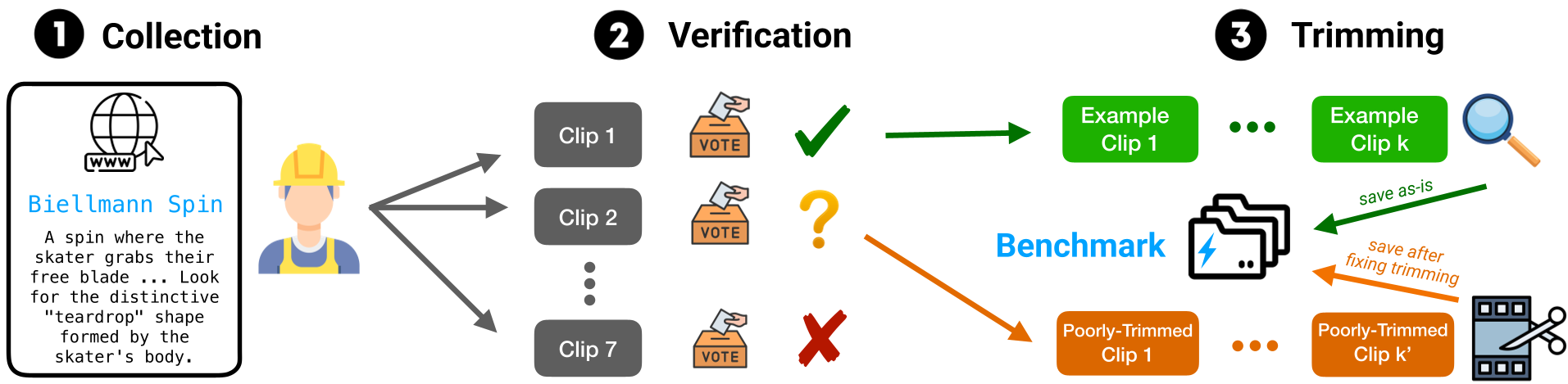 Figure 1: The VideoNet Benchmark collection pipeline, turning non-expert annotators into domain verifiers.
Figure 1: The VideoNet Benchmark collection pipeline, turning non-expert annotators into domain verifiers.
The "SingleAction" Breakthrough
Collecting human-verified data is expensive. To scale training, the authors flipped the script on Gemini. While Gemini is bad at naming a specific skateboarding trick, it is excellent at localizing when "something is happening."
By aligning these localized clips with video titles and Whisper-generated transcripts (the SingleAction strategy), they created a 160k-500k clip training set. This "distillation from signals" creates a feedback loop that improves the model's perception without human intervention.
Results: The Few-Shot Failure
One of the most striking findings is the Few-Shot Gap.
- Humans: Give a human 3 examples of a new action, and their accuracy jumps +13.6%.
- VLMs: The same 3 examples only yield a +2.9% gain.
Some models, like Gemini 3.1 Pro, actually performed worse when given more examples, suggesting they get "distracted" by background details in the examples rather than focusing on the motion.
 Figure 2: Performance of models across different categories. Note the high "Food" scores (likely due to object bias) vs the low "Dance" scores (pure motion).
Figure 2: Performance of models across different categories. Note the high "Food" scores (likely due to object bias) vs the low "Dance" scores (pure motion).
Deep Insight: Training Quality > Quantity
The study found that the SingleAction filter (the strictest and smallest dataset at 162k clips) resulted in better performance than the larger TranscriptLocalized set (496k clips). This confirms a brewing consensus in the AI community: for complex temporal reasoning, a smaller "clean" dataset is worth more than a half-million noisy samples.
Conclusion & Limitations
Takeaway: VideoNet proves that specialized action recognition is a distinct skill that general pre-training hasn't solved. Fine-tuning on domain-specific motion data is currently the only way to reach expert-level performance.
Limitations: Even the best models still struggle with "hard negatives." AI can tell you that you are skating, but it still can't reliably tell you if your jump was a "Lutz" or a "Loop." The road to a truly "expert" VLM requires better temporal grounding—the ability to focus only on the frames where the "toepick" hits the ice.
For more details, visit the official project site: tanu.sh/videonet