本文推出了 VisBrowse-Bench,这是一个专门评估多模态浏览智能体(Browsing Agents)在真实网络环境中进行“视觉原生搜索”能力的基准测试。该基准包含 169 个经过专家严格校验的 VQA 实例,要求模型通过文本-图像检索和联合推理来完成复杂的跨模态证据链验证。
TL;DR
传统的 AI 浏览智能体(Browsing Agents)正在面临“视觉失算”的尴尬:它们在复杂网页上往往只读文字而无视图像证据。本文提出的 VisBrowse-Bench 填补了这一空白,通过 169 个极具挑战性的多步推理任务,证明了即使是顶级模型如 Claude-4.6 或 o3-deep-research,在真正需要“看图寻证”的视觉原生搜索任务中,胜率也不足 50%。
背景定位:从“读网页”到“看世界”
在 Deep Research 领域,当前的基准测试(如 MMSearch)大多将视觉信息视作搜索的“敲门砖”——只要给出一张图,模型通过反向搜图拿到一个关键词(实体名),后续就变成了纯文本搜索。这种 “视觉降级” 现象掩盖了模型在处理真实世界多模态信息时的无力感。
痛点深挖:为什么现有的 Agnet 还是“睁眼瞎”?
- 过度依赖工具快捷键:许多模型遇到图片直接调用识别工具,缺乏对图像细节(颜色、空间关系、局部特征)的细粒度理解。
- 推理链的单模态化:一旦进入搜索流程,现有的 Reasoning Path 几乎全部转化为文本处理,模型不再主动寻找网页中的视觉线索来验证答案。
- 视觉证据的不可替代性:现实中很多问题的答案隐藏在图片与文字的相互校对中(例如:某品牌代言人在特定演唱会海报上的领带颜色),这无法通过纯文本摘要获取。
核心贡献:VisBrowse-Bench 与智能体工作流
1. 专家级数据设计
作者遵循“多模态信息整合”与“视觉能力强制调用”两大原则。每个问题都是一个多跳推理任务(至少 3 跳,且包含至少 2 个关键视觉证据块),涵盖媒体、生活、艺术、地理等 7 大领域。
2. 强大的 Agent 具身能力
为了让模型能动起来,作者设计了一套包含五种核心工具的闭环工作流:
- Text Search / Image Search: 获取广域信息。
- Reverse Image Search: 溯源图片背景。
- Image Crop (图像裁剪):这是关键,通过局部放大(Zoom-in)解决细粒度识别问题。
- Webpage Visit: 结构化提取网页内容。

实验战绩:全线崩溃的 SOTA 们
在测试中,作者对比了闭源模型(Gemini, GPT, Claude, Kimi)与开源模型(Qwen3-VL)。
- 性能天花板:Claude-4.6-Opus 凭借其极其平衡的工具调用策略和强大的推理能力,以 47.6% 的准确率摘得桂冠。
- Deep Research 的局限:备受瞩目的 o3-deep-research 表现平平,仅有 41.1%,说明专门针对强逻辑优化的模型在多模态证据融合上仍有优化空间。
- 开源力量差距明显:Qwen3-VL-235B 仅有 14.2%,显示出开源社区在 Agent 复杂决策与多轮图像理解合并方面面临巨大挑战。

深度洞察:为什么 Kimi-K2.5 反超了 Gemini?
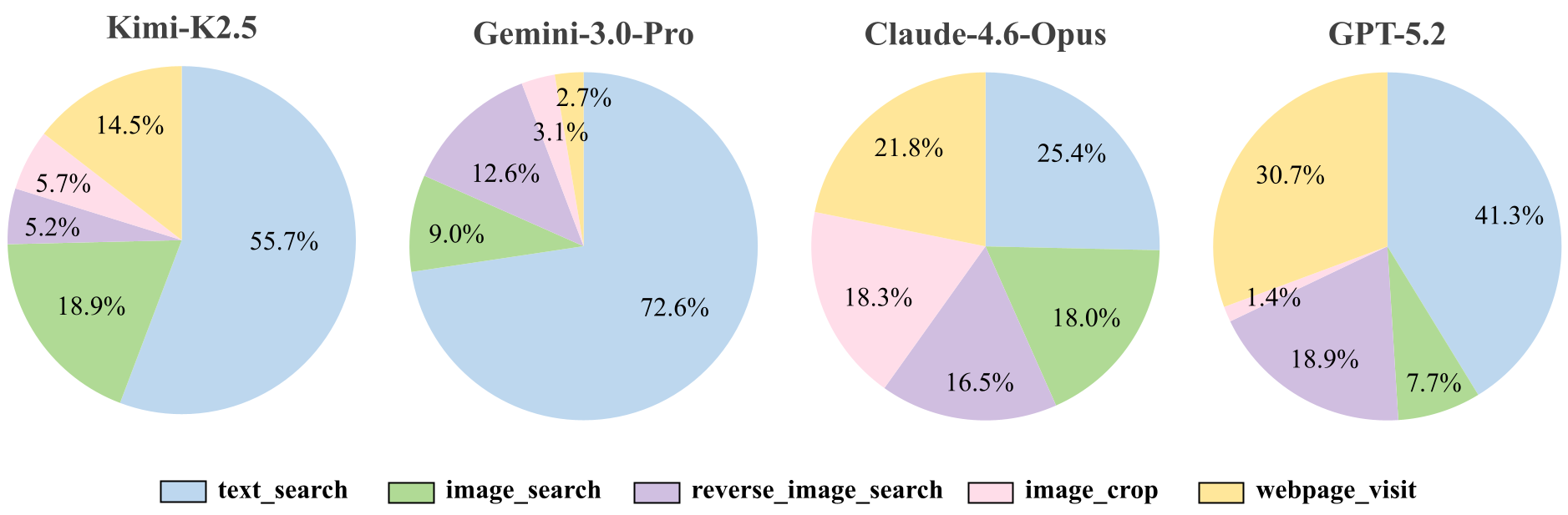
一个有趣的观察是,Kimi-K2.5 在加入图像搜索(+IS)后表现大幅提升(+19.5%)。根据工具使用分布图(Figure 5),Kimi 相比其他模型更倾向于频繁使用 image_search 工具。这种“主动探索视觉证据”的倾向使其在 VisBrowse-Bench 这种视觉导向的任务中占据了优势。
总结与局限性
VisBrowse-Bench 证明了当前 AI 距离真正的“多模态专家”还有很长的路要走。模型的局限性在于:
- 视觉推理能力断层:即使找到了包含信息的图片,模型也常常由于无法进行精准的局部特征提取(如 Case Study 中领带颜色的识别失败)而功亏一篑。
- 工具调用的盲目性:模型有时会陷入无效的循环调用,或在关键步骤忽略了应有的视觉验证。
未来展望:这项工作为多模态智能体的发展指明了方向——我们需要更先进的 RL 策略来训练模型在搜索过程中“时刻睁大双眼”,并在复杂的海量网页视觉信息中进行高效的价值锚定。