This paper introduces LLaDA-V adapted for GUI grounding, marking the first systematic exploration of Discrete Vision-Language Diffusion Models (DVLMs) in this domain. By framing action and bounding-box prediction as iterative denoising, the authors achieve competitive performance against state-of-the-art autoregressive models across web, mobile, and desktop benchmarks.
TL;DR
While Autoregressive (AR) models like Llama and Qwen currently rule the GUI grounding landscape, a new challenger has emerged: Discrete Vision-Language Diffusion Models (DVLMs). This paper adapts LLaDA-V for GUI tasks, introducing a Hybrid Masking Schedule that respects the geometric hierarchy of bounding boxes. The result? A model that achieves competitive Accuracy (SSR) and demonstrates that iterative refinement can rivals sequential prediction in digital environments.
Background: Why Diffusion for GUIs?
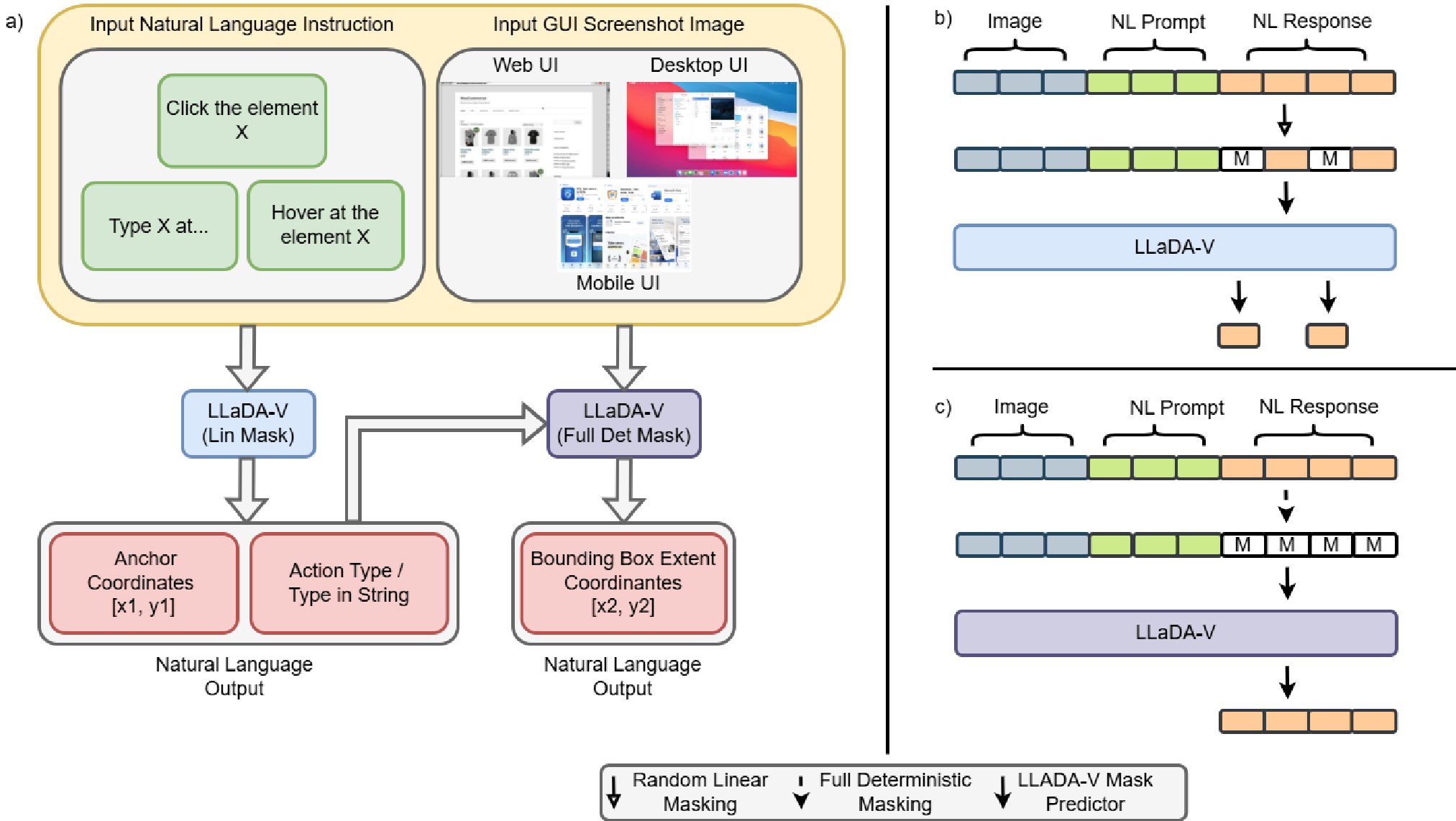
In the realm of GUI Agents, "grounding" is the bridge between a user's intent ("Click the login button") and a machine's action (locating the coordinates [x1, y1, x2, y2]). Conventional AR models generate these coordinates token-by-token. However, GUI elements are inherently spatial.
The authors argue that bidirectional attention—a hallmark of diffusion models—is more suited for spatial reasoning than the "look-back-only" nature of AR models. By treating grounding as a denoising process, the model can refine its "guess" for a button's location iteratively, considering all tokens simultaneously.
The Core Innovation: Hybrid Masking
Standard discrete diffusion (like the original LLaDA) uses linear masking, where tokens are hidden at random. This is problematic for geometry: the top-left corner ($x1, y1$) and bottom-right corner ($x2, y2$) are not independent; the latter defines the boundary relative to the former.
To solve this, the authors introduced a two-phase training strategy:
- Linear Masking Phase: Learns "coarse" grounding (identifying the action type and the anchor point).
- Deterministic Masking Phase: Specifically masks the extent ($x2, y2$) while keeping the anchor visible, forcing the model to learn the conditional spatial relationship.
Experimental Insights: Scaling and Parameters
The researchers found that DVLMs are highly sensitive to how they are "steered" during inference. They tracked three key knobs:
- Diffusion Steps: How many iterations of denoising.
- Generation Length: The output budget.
- Block Length: The amount of parallel token generation.
Setting these to 64 proved to be the "sweet spot" for balancing accuracy and latency. Interestingly, they observed that training on diverse data (web, mobile, desktop) not only improved accuracy by ~20 points but actually reduced latency because the model became more "confident," converging in fewer steps.

Results & SOTA Comparison
On the Mind2Web (M2W) benchmark, the adapted LLaDA-V 8B (Hybrid) achieved an SSR of 83.9%, outperforming the 3B versions of Phi and Qwen 2.5 VL. While the 7B/8B AR models still hold a slight edge in raw latency (1.1s vs ~3-5s for diffusion), the DVLM shows a superior ability to refine bounding boxes in complex layouts where AR models might drift.
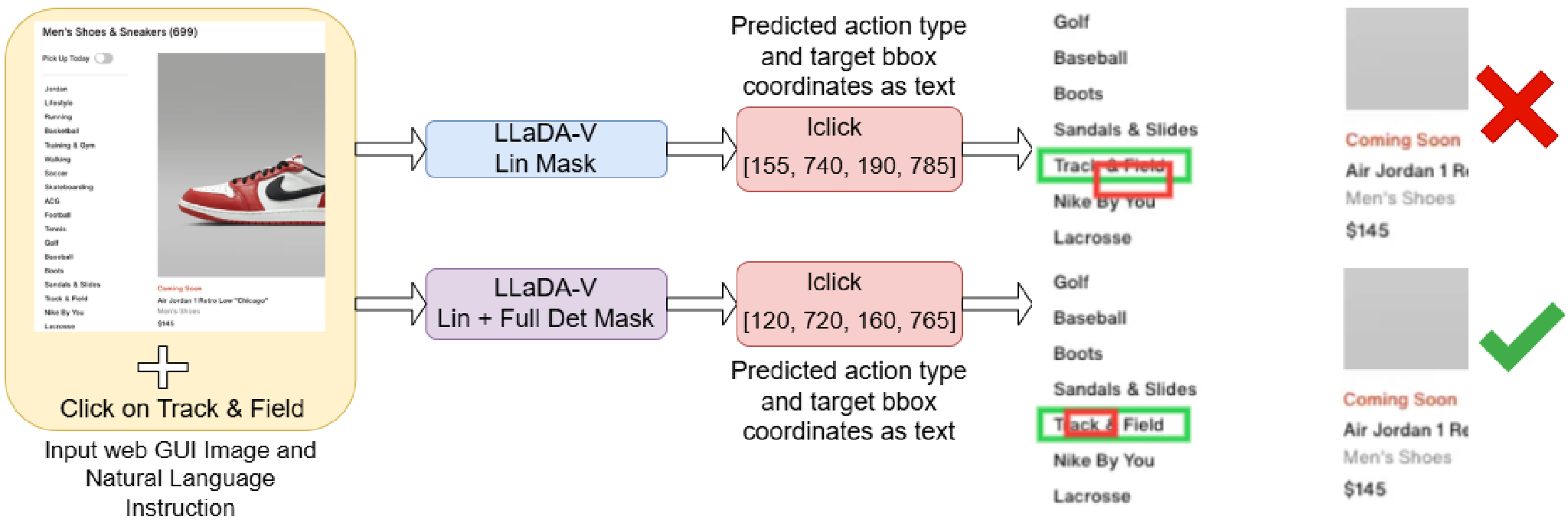 The image above demonstrates how Hybrid Masking (Red Box) provides a much tighter, more accurate fit to the element than standard Linear Masking.
The image above demonstrates how Hybrid Masking (Red Box) provides a much tighter, more accurate fit to the element than standard Linear Masking.
Critical Perspective
Strengths:
- Spatial Intelligence: Exploits bidirectional attention to solve the "coordinate drift" common in sequential AR models.
- Iterative Refinement: The low-confidence re-masking strategy allows the model to "change its mind," leading to more robust localization.
Limitations:
- The Latency Tax: Diffusion is inherently more expensive due to multiple forward passes. While parallel token generation helps, it currently cannot match the raw speed of optimized AR KV-caching.
- Single-Turn Focus: The study focuses on atomic actions. How these models handle long-horizon multi-step planning (e.g., "Book a flight from start to finish") remains an open question.
Conclusion
This work proves that diffusion isn't just for generating pretty pictures; it’s a powerful framework for structural understanding. By moving away from purely sequential generation, we can create GUI agents that "look" at the whole screen and refine their actions with a level of spatial awareness that AR models struggle to match.