本文提出了 VisionFoundry,一个全自动的任务驱动型视觉语言模型(VLM)合成数据生成框架。该框架仅需任务关键字即可生成包含图像、问题和答案(VQA)的三元组数据集 VisionFoundry-10K,显著提升了模型在空间感知和几何推理方面的能力。
TL;DR
尽管当前的视觉语言模型(VLM)在逻辑推理和对话上表现惊艳,但在简单的“左拥右抱”或“谁在前谁在后”等空间感知任务上却经常翻车。普林斯顿大学与纽大团队联合推出的 VisionFoundry 证明:我们不需要昂贵的人工标注,仅依靠 “LLM 编剧 + T2I 画家 + 强势 VLM 监修” 产生的 10,000 条合成数据,就能让模型在视觉感知基准上实现高达 10% 的性能跃迁。
1. 痛点:为什么 VLM 总是“睁眼瞎”?
目前大多数 VLM 的训练数据源自互联网上的图文对(Web-scale image-text pairs)。这些数据虽然量大,但存在以下致命伤:
- 低层感知信号缺失:没人会在图片说明里写“红色的球在蓝色方块左侧 3 厘米处”。
- 语言偏向严重:模型往往靠猜(基于语言先验)而不是看(基于图像像素)来回答问题。
- 获取成本高:想要系统性覆盖所有视角、遮挡和几何关系,人工标注简直是天文数字。
VisionFoundry 的核心直觉是:视觉感知是一种可以被“编程”生成的技能。
2. Methodology:VisionFoundry 的自动化生产线
VisionFoundry 的架构遵循三个原则:控制性(Controllability)、视觉决定论(Visual Determinism)和验证机制(Verification)。
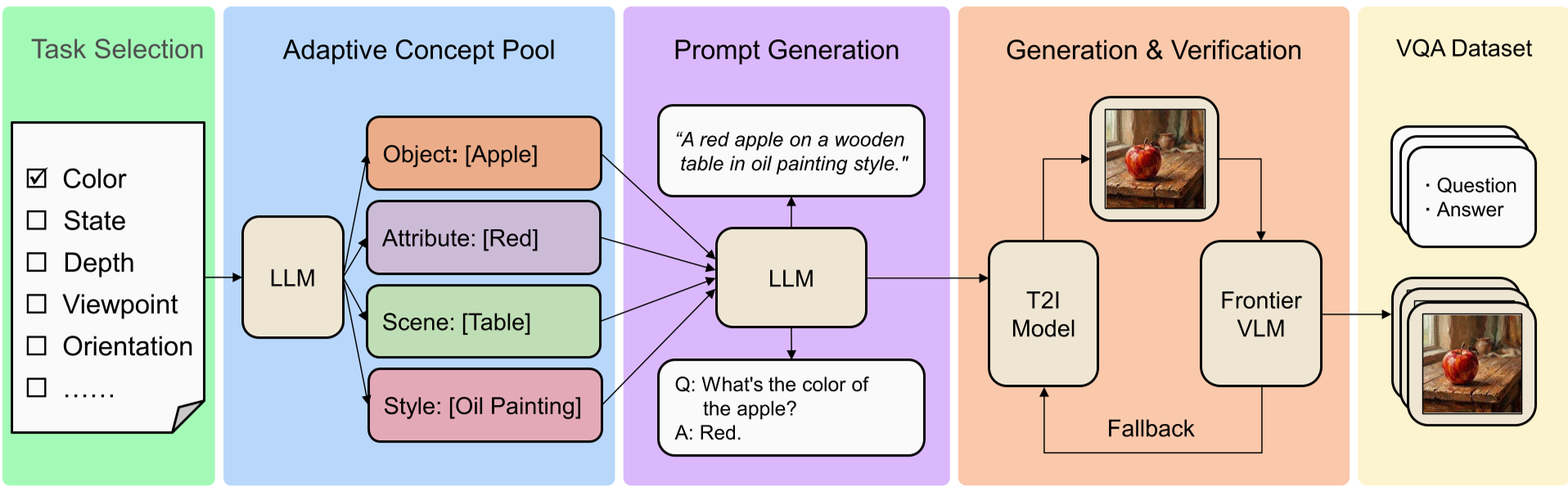 VisionFoundry 流程图:从任务关键字到验证通过的 VQA 三元组
VisionFoundry 流程图:从任务关键字到验证通过的 VQA 三元组
整个流水线分为三步:
- 文本侧构造:给定一个关键字(如“深度排序”),LLM(如 GPT-5.2 模拟)生成详细的图像描述(T2I Prompt)和关联的 QA 对。
- 图像合成:利用高性能 T2I 模型(如 Gemini-2.5-Flash-Image)将文字描述转化为逼真的图像。
- 闭环验证(关键环节):由一个顶级的多模态模型(如 Gemini-3-Pro)担任审计员。它会判断生成的图像是否真的体现了预设的视觉事实(比如“左边是否有那只猫”)。如果审核不通过,样本直接报废。
这种“监修制”确保了即便 T2I 模型偶尔“画错”,这些错误数据也不会污染训练集。
3. 实验:合成数据真的能打吗?
作者构建了包含 10 个感知任务的 VisionFoundry-10K 数据集。实验结果令人振奋:
| 模型基座 | 基准测试 | 提升幅度 | | :--- | :--- | :--- | | Qwen2.5-VL-3B | CV-Bench-3D | +10.5% | | MiMo-VL-7B | MMVP (Pair) | +14.0% | | Llama-3.2-11V | RealWorldQA | +1.6% |
核心发现
- Scaling Law 依然有效:随着合成数据量从 0.5k 增加到 10k,感知能力呈稳步上升趋势。
- 合成+自然=最强混合:实验证明,在相同数据规模下,加入合成数据的模型表现优于纯自然数据微调的模型。
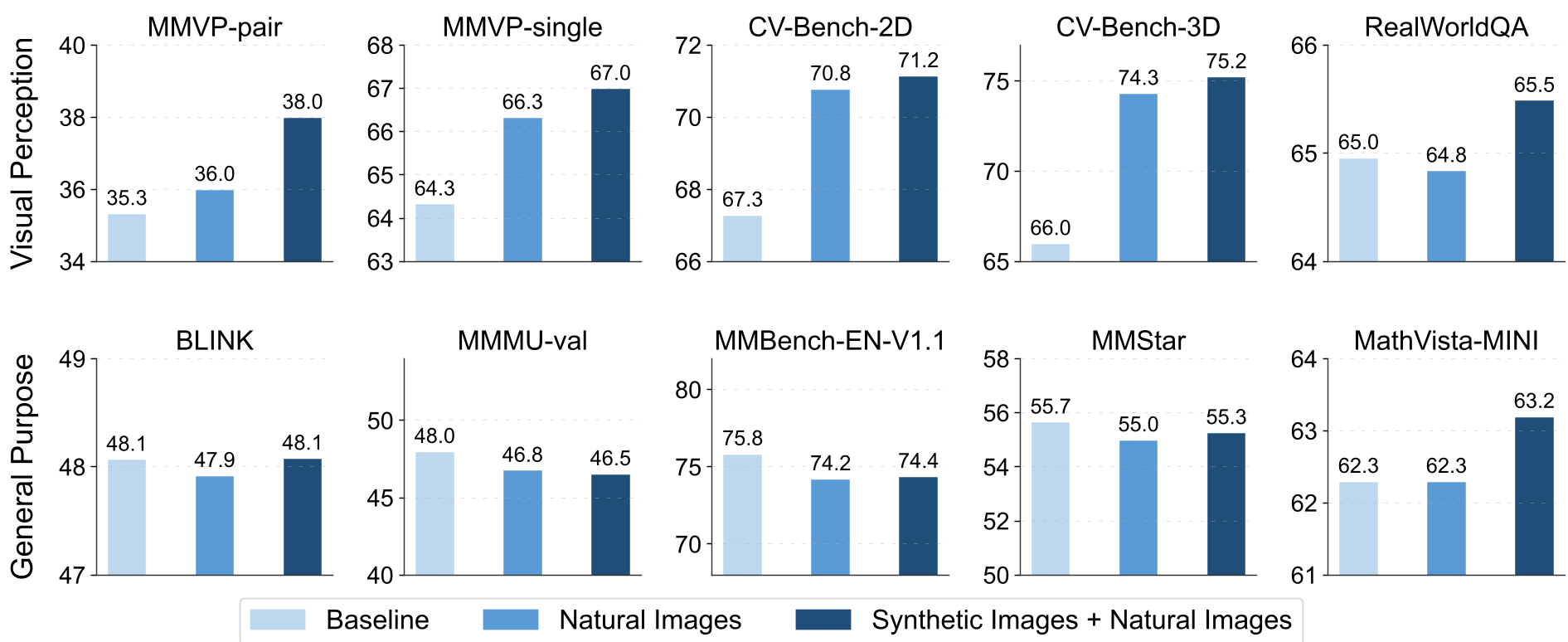 随着数据规模增加,模型的空间感知准确率(如 CV-Bench-3D)显著提升
随着数据规模增加,模型的空间感知准确率(如 CV-Bench-3D)显著提升
4. 深度洞察:为什么合成图像有效?
传统的观点认为合成图像存在“领域鸿沟(Domain Gap)”,可能导致模型崩坏。但 VisionFoundry 证明了在 底层视觉领域:
- 精准的像素级对齐:合成图像的布局是可以被 Prompt 精确操纵的,这种“像素-文本”的强耦合是互联网杂乱数据无法提供的。
- 多样性补全:合成模型可以生成现实中罕见的怪异组合(例如:放在冰块上的热气腾腾的牛排),从而迫使模型真正去“看”而不是去“猜”。
5. 总结与反思
VisionFoundry 的成功预示着多模态训练的一个新范式:我们不再受限于自然界抓取的图像,而是可以根据模型的性能短板,“按需印刷”训练数据。
局限性:
- 目前的任务多集中在简单的物体关系,对于涉及长链逻辑推理的复杂视觉任务,合成数据是否依然如此高效尚待验证。
- 验证环节高度依赖于现有的顶级封闭源代码模型(如 Gemini),开源社区需要更强大的本地“验证员”模型。
未来展望: 随着 T2I 模型视频生成能力的爆发,也许下一代 VisionFoundry 就能带我们教 VLM 理解复杂的物理动力学和时间顺序。
本文基于论文: VisionFoundry: Teaching VLMs Visual Perception with Synthetic Images