本文推出了 VOLMO,一个模型无关且数据开放的眼科大模型开发框架,并据此训练了 2B 参数量的眼科多模态大模型 VOLMO-2B。该模型在眼科图像描述生成、疾病筛查及临床推理任务中全面达到 SOTA 水平。
TL;DR
眼科诊断高度依赖视觉信息与临床病史的综合判断,但现有的多模态模型在眼科垂直领域常常出现“幻觉”或诊断过失。来自耶鲁大学等机构的研究团队发布了 VOLMO (Versatile and Open Large Models for Ophthalmology)。这是一个完全基于公开数据、阶段化训练的模型框架,通过 2B 参数量在眼科图像解读、疾病分期及治疗方案生成上全面超越了 27B 的 MedGemma 和 GPT-4V。
痛点深挖:通用大模型的“色盲”困境
目前的 MLLM 在医疗领域虽有进展,但在眼科面临三大技术瓶颈:
- 细节丢失 (Fidelity Loss):如黄斑变性中的微小渗出,在通用模型常用的 224x224 分辨率下几乎会被磨灭。
- 知识孤岛:通用模型不懂眼科专业术语,且现有基准测试大多仅提供分类标签,缺乏临床所需的逻辑推理。
- 封闭黑盒:高性能模型(如 GPT-4o)不可开源,限制了本地医疗部署的隐私合规性。
核心架构:三阶段炼金术 (Methodology)
VOLMO 并不是简单地堆砌数据,而是模拟了一个眼科医生的培养过程:
1. 领域知识预训练 (Stage 1: Pretraining)
从 82 本眼科期刊中提取了 86,965 对图文对。为了解决原始论文摘要中的缩写和乱码,作者利用 LLM 进行语义增强,将琐碎的注释转化为标准的临床叙述。
2. 任务特定微调 (Stage 2: Task Fine-tuning)
利用包含巴西、亚洲、美国等多族群的 12 种眼科病症数据集(如青光眼、AMD、糖网),通过标准的 Instruction-Response 模式,训练模型执行分类、筛查和分期。
3. 多步临床推理 (Stage 3: Clinical Reasoning)
最令人惊艳的是该阶段。模型不再是一次性给结论,而是通过 913 份真实病例报告模拟:“病史采集 -> 鉴别诊断 -> 确定诊断 -> 制定计划” 的完整闭环。
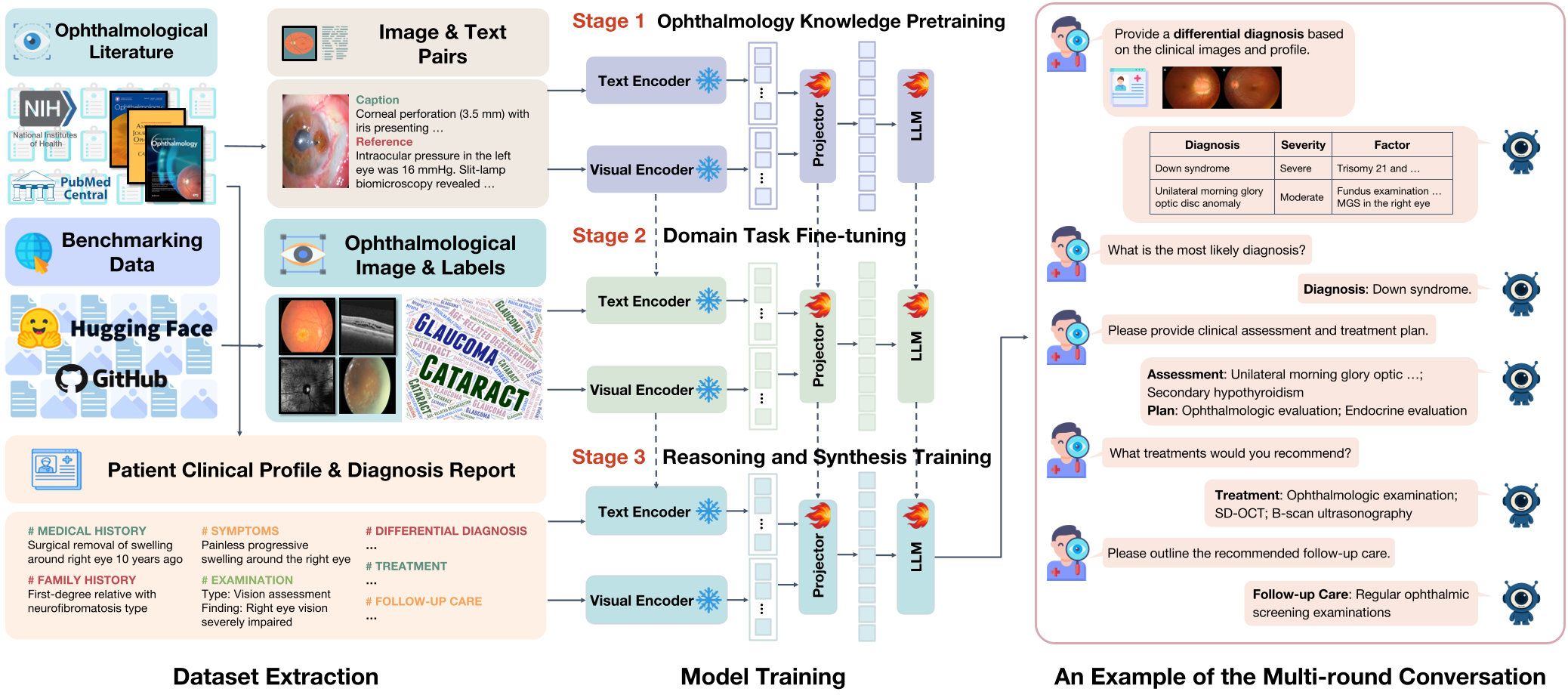 图 1:从数据提取、三阶段训练到多轮对话推理的完整 Pipeline
图 1:从数据提取、三阶段训练到多轮对话推理的完整 Pipeline
实验战绩 (Experiments & Results)
图像描述:更懂医生的专业表达
在自动评估指标上,VOLMO-2B 在 ROUGE-L 和 BERTScore 上显著领先。更关键的是手动评估,眼科专家认为其生成的描述在“简洁性”和“专业阅读友好度”上得分极高(4.43/5),而 MedGemma-27B 则显得过于冗长且常包含无关信息。
 图 2:不同模型生成描述的定性对比,VOLMO 能精准识别内源性眼内炎等复杂征象
图 2:不同模型生成描述的定性对比,VOLMO 能精准识别内源性眼内炎等复杂征象
疾病分期:甚至击败了定制化的 RETFound
在与专门为眼底图像训练的基础模型 RETFound 对比中,VOLMO-2B 作为一个通用生成模型,在 12 种疾病中的 8 种表现更优。尤其是在黄斑孔(Macular Hole)分期任务中,F1 达到了惊人的 92.62%。
深度洞察:为什么 2B 能赢?
- 高分辨率感知 (Dynamic Resolution):使用了 InternVL 架构,支持高达 448 像素的动态切片技术,确保了对视网膜神经纤维层等细微变化的捕捉。
- 数据质量优于数量:相比于 LLaVA-Med 这种使用 1500 万对粗糙抓取数据的模型,VOLMO 使用的 11 万个高质量、经 LLM 修剪并经专家抽检的实例,其 Inductive Bias 更契合临床逻辑。
- 推理对齐:Stage 3 的多轮对话设计将病人的家族史、症状与影像特征通过上下文关联,极大地降低了单纯看图说话引发的错误。
局限性与展望
尽管 VOLMO-2B 表现优异,但在处理极致复杂的多病并发推理时仍有提升空间。研究团队已将代码和模型全部开源,这不仅意味着研究人员可以在本地 RTX 3050/4090 显卡上复现并在私有临床数据上微调,也为资源受限地区的初级诊疗提供了可能性。
总结
VOLMO 的出现标志着眼科 AI 从单一分类器(Classifier)迈向了生成式叙事(Generative Narratives)的新阶段。它告诉我们:医学 AI 的未来不在于盲目的大模型军备竞赛,而在于如何通过专业知识的精准注入,让模型真正拥有“临床直觉”。