本文提出了 Volume Transformer (Volt),这是一种基于原生 Transformer (Vanilla Transformer) 架构的 3D 场景理解主干网络。通过将 3D 点云划分为体积补丁 (Volumetric Patch) 并结合 3D 旋转位置编码 (RoPE),Volt 在无需复杂领域先验的情况下,在 ScanNet、ScanNet200 等多个 3D 分割基准上达到了 SOTA 性能,且推理速度比之前的领先模型 PTv3 快 2 倍。
TL;DR
在 3D 视觉领域,长期以来一直认为由于点云的稀疏性和计算复杂度,必须设计复杂的局部算子或分级架构。本文提出的 Volume Transformer (Volt) 彻底颠覆了这一观念。它直接将原本为 NLP 和 2D 视觉设计的 Vanilla Transformer Encoder 应用于 3D 场景,通过全局注意力(Global Attention)和 3D RoPE 位置编码,在速度和精度上双双超越了高度定制化的当前最强模型 PTv3。
痛点深挖:被“隔离”的 3D 骨干网络
过去的 3D 模型(如 Point Transformer v3, 3D U-Net)虽然强大,但存在两个核心局限:
- 生态孤岛:定制化的局部注意力算子通常需要手写的 CUDA 内核(如 PTv3 的空间填充曲线),无法享受到 FlashAttention 等通用 Transformer 加速技术的红利。
- 归纳偏置的局限:模型中过多的领域先验(Inductive Biases)虽然在小数据集上表现稳健,但在大数据面前往往会成为上限。
Volt 提出的动机很简单:能否像 2D 领域的 ViT 那样,用最干净的架构,吃最强的数据红利?
方法论详解:如何将 3D 推入 Vanilla Transformer?
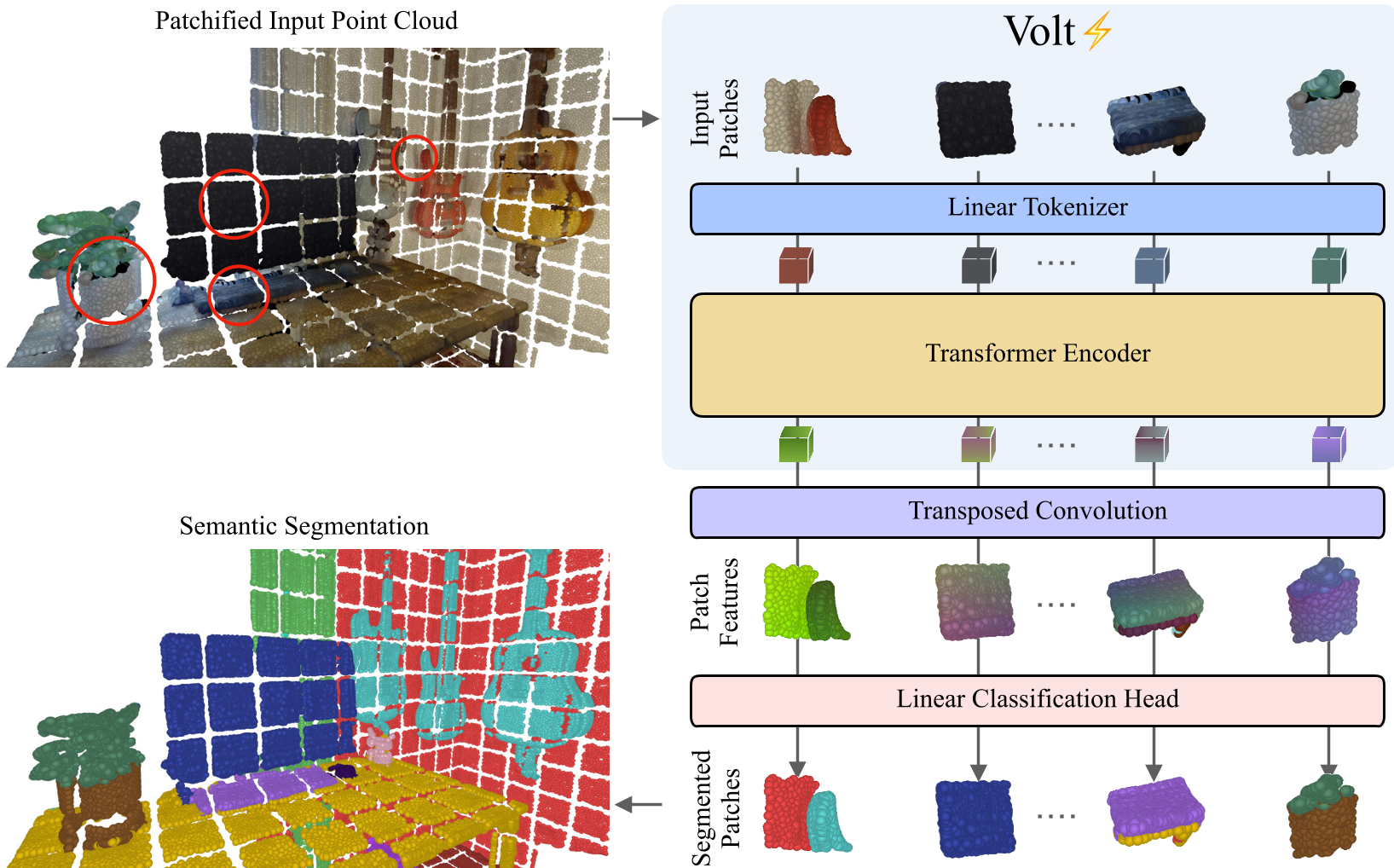
Volt 的核心架构只需三个关键步骤:
1. 体积补丁 Tokenization
由于点云动辄数十万点,直接把点当成 token 会触发 的内存爆炸。Volt 将 3D 空间划分为 Cubic Patches(立方体补丁)。
- 首先进行体素化(Voxelization)。
- 接着使用一个步长等于核大小的 Sparse 3D Convolution 进行下采样,将每个 patch 映射为一个 D 维的特征向量(Token)。
- 典型设置下,一个室内场景仅生成约 5,000 个 tokens,这使得全局注意力在现代显卡上通过 FlashAttention 实现变得轻而易举。
2. 3D 旋转位置编码 (3D RoPE)
Transformer 是置换不变的,因此位置编码至关重要。Volt 扩展了 RoPE,将 Query 和 Key 进行轴内分解,并在 X, Y, Z 三个轴上独立应用旋转变换。
- 非对称设计:考虑到 3D 场景(尤其是自动驾驶)水平方向信息多于垂直方向,Volt 给 X/Y 轴分配了比 Z 轴更多的频率参数配置。
3. 数据驱动的训练配方 (Recipe)
原生模型很难训。为了解决 3D 数据量不足导致的过拟合,Volt 使用了:
- CNN Distillation:从一个经典的 3D U-Net(MinkUNet)中“借用”归纳偏置。
- 多数据集联合训练:横跨 ScanNet++, ARKitScenes 等多个数据集,打破单一数据的限制。
实验与结果:速度与精度的双重碾压
1. SOTA 性能对比
在 ScanNet200 和最新的 ScanNet++ 上,Volt 展现了恐怖的 Scaling 能力。随着训练数据的增加(从 50% 到 100% 乃至跨库训练),Volt 的提升斜率远超 PTv3,最终在室内外多个任务中摘得桂冠。

2. 推理效率
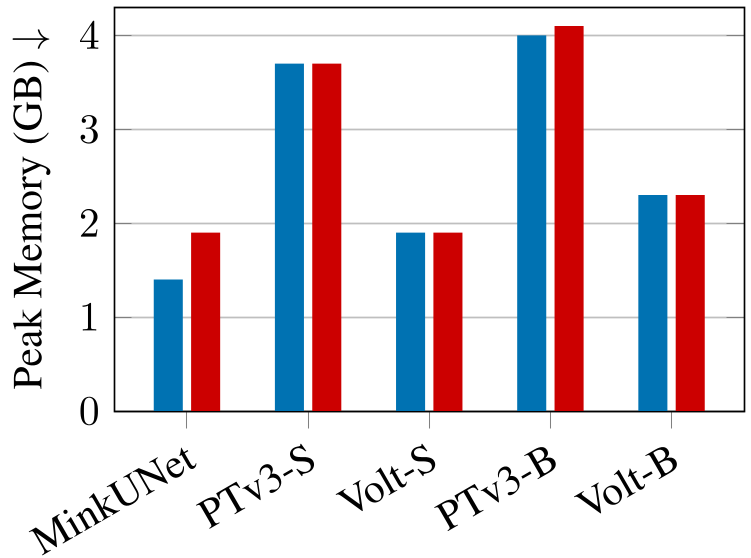
得益于其架构的纯净性,Volt 可以直接调用 FlashAttention-2 核心。
- 延迟降一半:Volt-B 在 A100/H100 上的推理速度是 PTv3 的 2 倍。
- 内存省一半:峰值显存占用减少了 48%。
深度洞察:3D 视觉的“大统一”前夜
Volt 的意义不仅在于刷了几分,而是在于它证明了:只要算力够强、数据够多,3D 领域不需要特殊的定制,标准的 Transformer 才是最终解。
通过消除 specialized 3D modules,Volt 让 3D 任务可以无缝集成到现有的多模态大模型(VLM)生态中。未来,我们或许能看到一个像 Llama 处理文本一样处理 3D 物理世界的通用模型,而 Volt 正是这一路径上的一个强力支点。
局限性:在极小的数据集(如只有几百个样本)下,如果没有高效的蒸馏和增强,Volt 仍然难以和传统 CNN/等变卷积竞争。但这正是 Scaling Law 告诉我们的真理:数据才是架构的上限。