Voxtral TTS is a state-of-the-art multilingual zero-shot text-to-speech model featuring a hybrid architecture that combines auto-regressive semantic token generation with continuous flow-matching for acoustic tokens. Built on the 3B-parameter "Ministral" backbone, it achieves a 68.4% win rate over ElevenLabs Flash v2.5 in human evaluations for voice cloning.
Executive Summary
TL;DR: Mistral AI has released Voxtral TTS, a multilingual powerhouse that clones voices with as little as 3 seconds of audio. By abandoning the "purely auto-regressive" dogma and adopting a hybrid AR + Flow-Matching architecture, it delivers human-preferred expressivity and naturalness, outperforming industry leaders like ElevenLabs in zero-shot cloning tasks.
Background: In the landscape of TTS, we have seen a tug-of-war between Auto-Regressive (AR) models (like Valle-E) and Diffusion/Flow models (like Voicebox). Voxtral TTS is a "best of both worlds" synthesis, positioned as a high-efficiency Open-Weight alternative to proprietary flagship systems.
The Core Motivation: Why Hybrid?
Traditional neural TTS treats speech as a flat sequence of tokens. This is problematic because:
- Semantic logic (the words and rhythm) is discrete and long-range.
- Acoustic texture (the timber and emotion) is dense and continuous.
Forcing a model to predict dense acoustic tokens auto-regressively is like trying to paint a masterpiece one pixel at a time—it's slow and prone to accumulating errors. Voxtral's insight is to use an AR backbone for the "skeleton" (semantic tokens) and a Flow-Matching transformer for the "flesh" (acoustic details).
Methodology: The Anatomy of Voxtral
The system relies on a two-part innovation: Voxtral Codec and the Hybrid Generator.
1. Voxtral Codec: Semantic-Acoustic Factorization
The codec compresses 24kHz audio into 12.5Hz frames. Crucially, it splits the latent space:
- 1 Semantic Token (VQ): Trained via distillation from a frozen Whisper ASR model. This ensures the token captures linguistic meaning rather than just noise.
- 36 Acoustic Tokens (FSQ): Finite Scalar Quantized dimensions that capture the "voice print."
2. The Hybrid Inference Loop
Instead of a massive transformer predicting all 37 tokens, the Ministral 3B backbone predicts only the semantic token. The hidden state from this prediction is then fed into a lightweight Flow-Matching Transformer. This second model runs 8 steps of an ODE solver to "denoise" Gaussian noise into the 36 acoustic tokens.
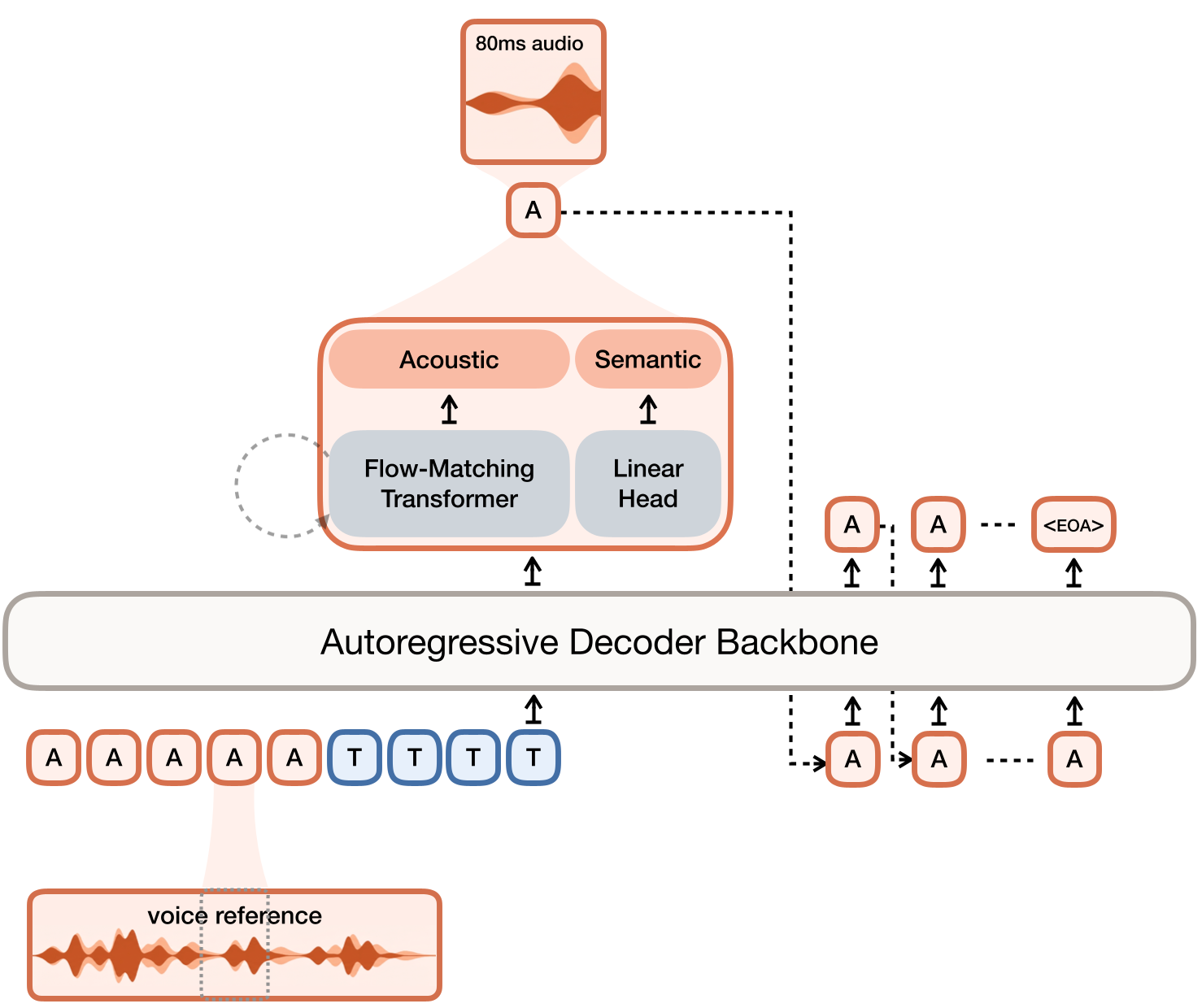 Figure: The Voxtral TTS pipeline—AR for semantics, FM for acoustics.
Figure: The Voxtral TTS pipeline—AR for semantics, FM for acoustics.
Experiments: Breaking the SOTA
Voxtral was tested across 9 languages. One of the most striking findings wasn't just the quality, but the Zero-Shot generalization.
- Human Preference: In blind "A/B" tests, humans preferred Voxtral over ElevenLabs Flash v2.5 by a staggering 68.4% win rate for voice cloning.
- Expressivity: Even against specialized systems like Gemini 2.5 Flash TTS, Voxtral remains highly competitive in "Implicit Steering"—the ability to infer emotion naturally from text without explicit tags.
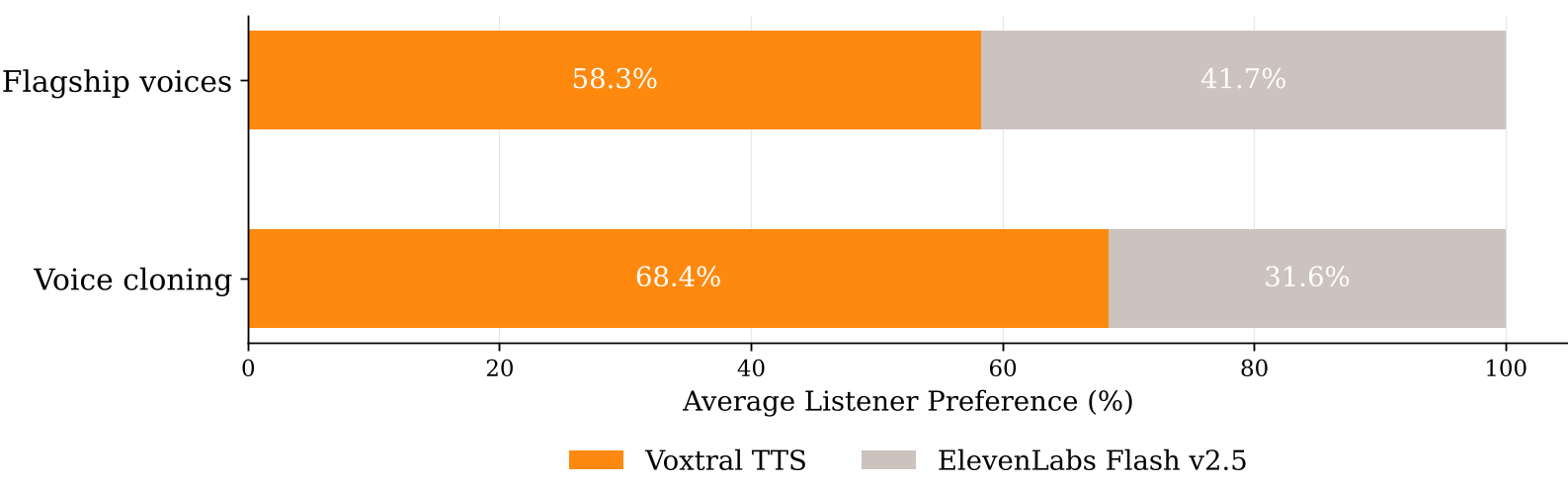 Figure: Voxtral TTS consistently wins in human evaluations, particularly in cloning tasks.
Figure: Voxtral TTS consistently wins in human evaluations, particularly in cloning tasks.
Optimization: Real-Time Performance
A 3B parameter model with a nested Flow-Matching loop could be a latency nightmare. The authors solve this via vLLM-Omni:
- CUDA Graphs: Capturing the ODE solver's execution path to eliminate Python overhead, speeding up generation by 47%.
- Asynchronous Streaming: The AR stage and the Codec Decoder run in parallel. The system generates audio chunks before the full text is even processed.
Critical Insight & Conclusion
Voxtral TTS proves that Direct Preference Optimization (DPO) can be effectively applied to multi-modal, hybrid architectures. By combining a standard cross-entropy DPO (for semantics) with a Flow-DPO (for acoustics), the authors eliminated common TTS artifacts like volume tapering and "hallucinated" words.
The Takeaway: For researchers, the success of the ASR-distilled semantic token suggests that "meaning-aware" quantization is the future of audio modeling. For developers, Voxtral provides a production-ready, open-weight alternative for expressive, low-latency voice applications.
Limitations: While powerful, the model still requires high-quality reference audio for the best results; "in-the-wild" noisy recordings may require higher Classifier-Free Guidance (CFG) values, which can occasionally reduce emotional nuance.