VP-VLA is a novel dual-system framework that decouples high-level reasoning from low-level control in robotic manipulation. It uses a "System 2" planner to generate structured visual prompts (crosshairs and bounding boxes) that guide a "System 1" controller, achieving state-of-the-art performance on benchmarks like RoboCasa (+5% success) and SimplerEnv (+8.3% success).
TL;DR
Robotic Vision-Language-Action (VLA) models often struggle with "spatial blindness"—they understand the command but miss the exact target. VP-VLA solves this by introducing a dual-system architecture. A high-level System 2 Planner identifies targets and draws a "crosshair" or "bounding box" directly on the robot's camera feed. A low-level System 1 Controller then simply follows these visual cues. This simple yet powerful decoupling led to an 8.3% boost on SimplerEnv and superior real-world robustness.
Problem & Motivation: The Black-Box Bottleneck
In traditional VLA frameworks, a single model must simultaneously solve three hard problems:
- Instruction Interpretation: "What does the user want?"
- Spatial Grounding: "Where is that specific bottle in the cluttered scene?"
- Low-level Control: "How do I move my joints to grab it?"
The authors observed that existing models often fail when encountering novel objects because they overfit to specific scenes. They treat the instruction as a "vibe" rather than a set of precise geometric coordinates. If the model hasn't seen a "red shoe" in a "green box" before, the monolithic structure often collapses because its reasoning and execution are too tightly coupled.
Methodology: System 1 and System 2
VP-VLA draws inspiration from Daniel Kahneman’s "Thinking, Fast and Slow."
1. The System 2 Planner (Thinking Slow)
This module uses a pre-trained VLM (Qwen3-VL) to perform "Event-Driven Task Decomposition." It doesn't run at every millisecond (which would be computationally expensive). Instead, it triggers only when a physical state changes—like the gripper closing. It then generates:
- Interaction Anchors: A crosshair (+) on the target object center.
- Spatial Constraints: A bounding box ([ ]) defining the goal area.
2. The System 1 Controller (Thinking Fast)
The controller receives the raw RGB image plus the visual prompt overlay. To ensure the robot doesn't ignore these overlays, the authors introduced an Auxiliary Grounding Objective. During training, the model is forced to predict the coordinates of the prompts it sees, ensuring its internal features are "locked" onto the visual cues.
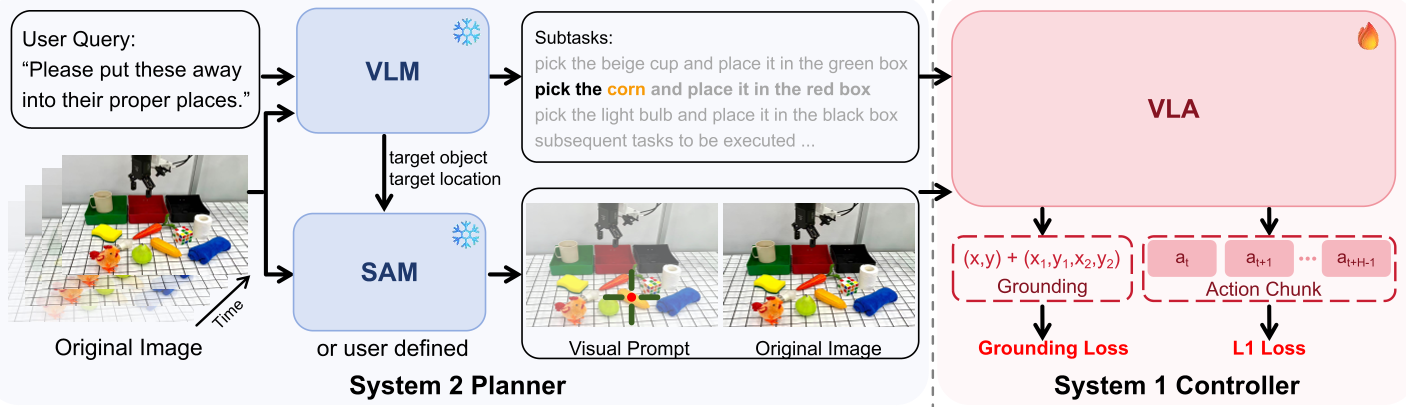 Fig 1: The dual-system architecture of VP-VLA.
Fig 1: The dual-system architecture of VP-VLA.
Experiments: Superior Precision and Robustness
The model was put to the test across RoboCasa (simulated kitchen) and SimplerEnv (standard VLA benchmark).
- Precision Gains: On tasks like "Put Eggplant in Yellow Basket," VP-VLA reached a 95.8% success rate, compared to just 70.8% for the primary baseline.
- OOD Generalization: In real-world "Waste Sorting," when presented with completely new objects (Out-of-Distribution), the baseline's performance dropped by 16.7%. In contrast, VP-VLA only dropped by 2.5%, proving that the visual prompts provide a universal "interface" that works regardless of the specific object appearance.
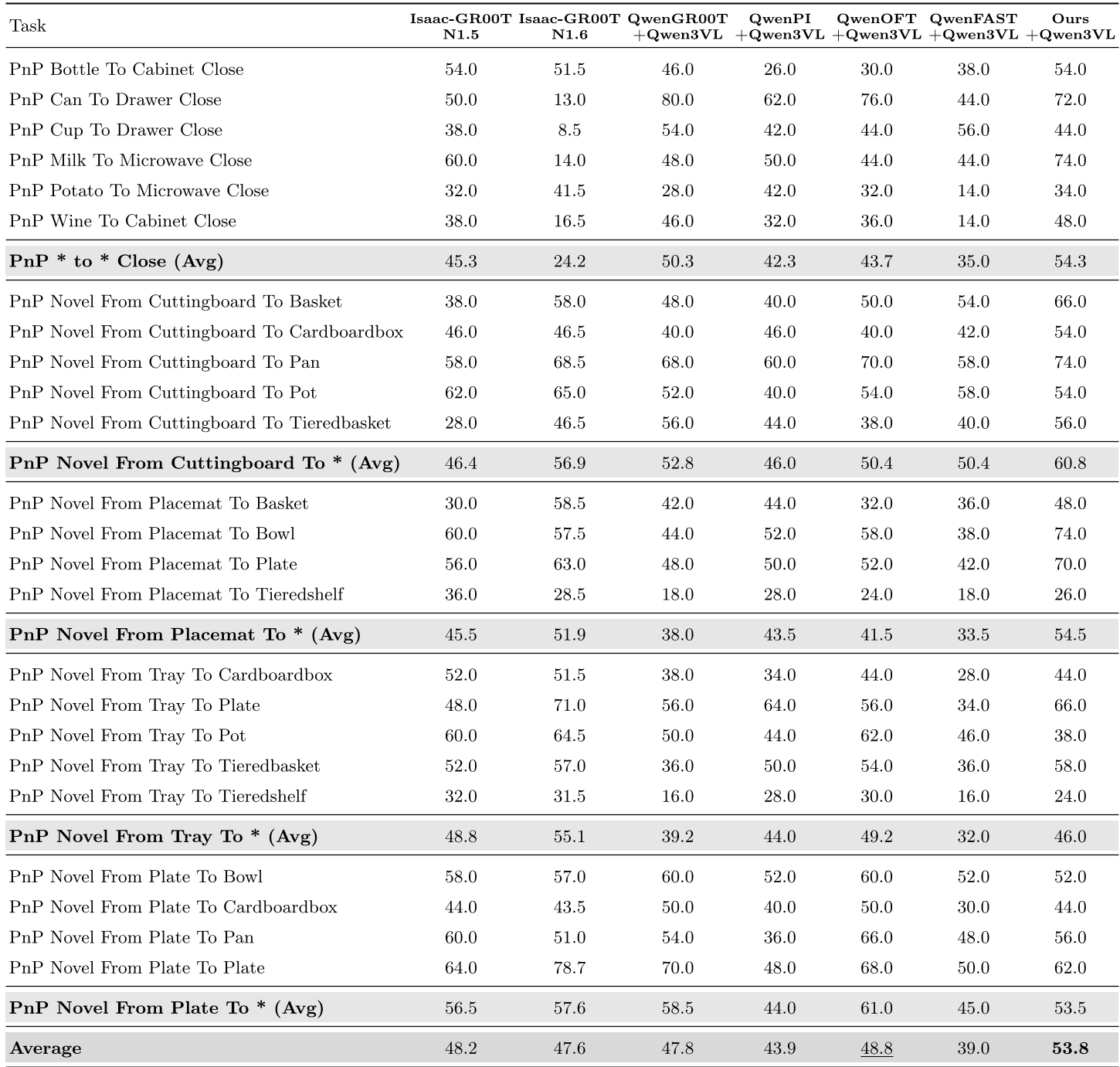 Table 1: VP-VLA consistently outperforms competitors like GR00T and π0.5 across various tasks.
Table 1: VP-VLA consistently outperforms competitors like GR00T and π0.5 across various tasks.
Critical Insight: Why Does it Work?
The beauty of VP-VLA lies in Interface Engineering. By translating a high-level linguistic concept ("the wine bottle") into a low-level visual marker (red crosshair), the burden on the controller is drastically reduced. It no longer needs to know what a "wine bottle" is; it only needs to know how to "move toward the crosshair."
Limitations
- Latency: The System 2 Planner still requires a VLM forward pass, which, while event-driven, can introduce pauses in complex, high-speed multi-stage tasks.
- Prompt Geometry: The ablation study showed that the shape of the prompt matters (crosshairs work better than simple dots). Finding the "optimal" visual language for robots is still an open question.
Conclusion
VP-VLA demonstrates that "visual prompting" acts as a modular bridge between reasoning and action. By forcing the model to ground its policy in explicit spatial markers, the researchers have moved one step closer to truly generalist robots that can operate in unpredictable, real-world kitchens and factories with surgical precision.