本文提出了 Q2RL,一种高效的从离线模拟/演示到在线强化学习(Offline-to-Online RL)的转换框架。该方法通过核心的 Q-Estimation 和 Q-Gating 机制,在无需原始演示数据的情况下,从行为克隆 (BC) 模型中提取 Q 函数并引导在线探索,实现了多项机器人操纵任务的 SOTA 性能。
TL;DR
在机器人领域,行为克隆 (BC) 简单好用但缺乏自我进化能力;强化学习 (RL) 潜力无限但在真机上探索太慢。本文提出的 Q2RL (Q-Estimation and Q-Gating from BC for RL) 成功打通了两者:它能从现成的 BC 模型中“压榨”出隐藏的价值函数(Q-Value),并以此指导在线 RL 训练。实验证明,Q2RL 能在 1-2 小时内显著提升机器人成功率,且有效避免了在线训练初期的“推倒重来”现象。
背景定位:离线到在线的“性能塌陷”黑洞
目前的机器人学习通常遵循“先离线模仿演示,再在线强化微调”的逻辑。然而,学术界一直被一个问题困扰:遗忘 (Unlearning)。当你在真机上开启 RL 时,新的探索数据往往会导致原本表现良好的 BC 策略由于梯度更新而迅速崩溃。此外,真机探索极其昂贵且危险,不能像仿真环境那样肆意乱撞。
核心直觉:BC 政策里到底藏了多少“宝藏”?
作者提出了一个深刻的 Insight:一个训练好的 BC 策略,其动作选取的概率分布本质上反映了它对动作价值的排序。如果你假设人类演示遵循 Boltzmann 分布(即动作越好,概率越高),那么通过数学转换,我们就能从 BC 的 log-probability 和熵(Entropy)中还原出其背后的 Q 函数。
核心组件 1:Q-Estimation(Q 估计)
这是 Q2RL 的数学灵魂。作者推导出公式: 通过极少量的环境随机采样(100 个 Rollouts),Q2RL 就能给现有的 BC 策略配上一个“指南针”。
核心组件 2:Q-Gating(Q 门控)
有了估计出的 ,在线训练时模型就不再盲目。系统会同时对比当前 BC 建议的动作向量与 RL 正在学习的动作向量,谁的 Q 值高就执行谁(如下图所示)。
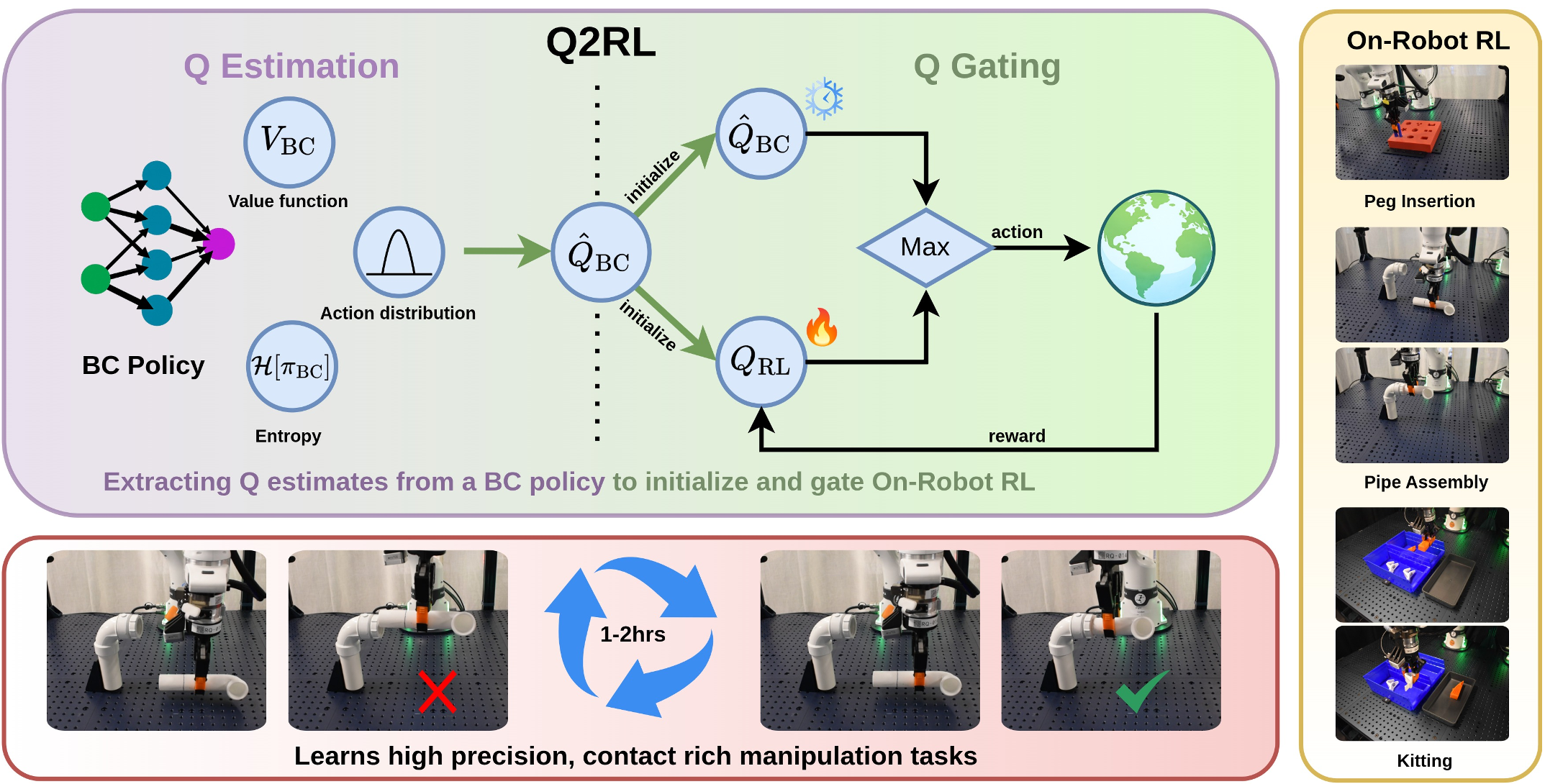
实验战绩:真机上的实时进化
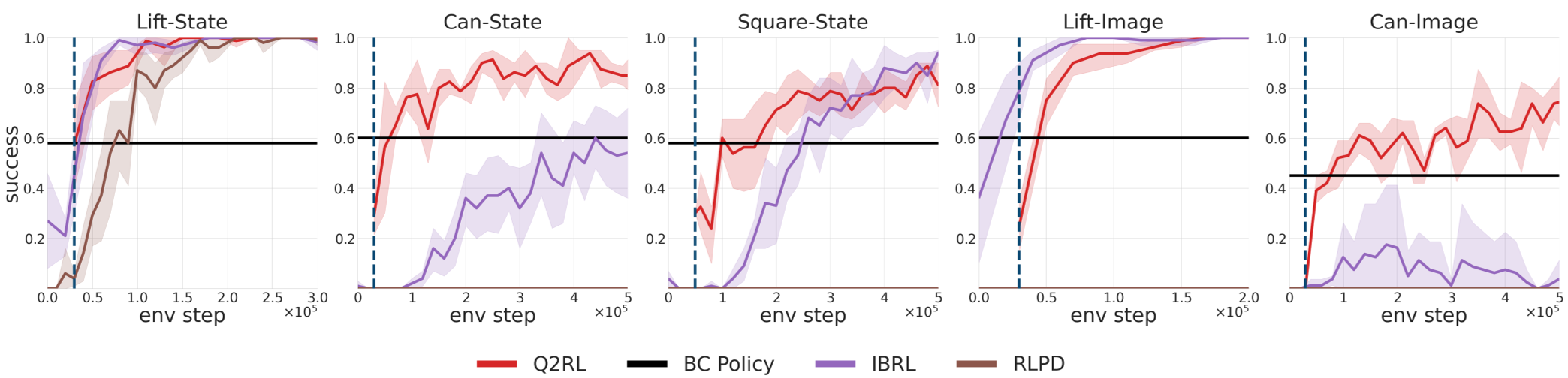
Q2RL 在多个高难度操纵任务中表现惊人,特别是在数据稀缺(无需访问原始演示数据)的场景下。
- 管道组装任务 (Pipe Assembly):原本 BC 只有 20% 成功率,但在经过 1.5 小时的 Q2RL 在线强化后,成功率飙升至 75%,提升 3.75 倍。
- 分布偏移适应:在“套件组装 (Kitting)”任务中,当物体位置发生变动(模型从未见过的分布),Q2RL 能迅速通过 RL 模块找到修正路径,而传统 BC 直接失效。
深度洞察:为什么 Q2RL 更好用?
- 不依赖原始数据:很多时候我们只有训练好的模型,没有原始数据。Q2RL 的 Q-Estimation 机制通过“白盒”读取模型参数直接估算价值,这在实际工程落地中具有巨大优势。
- 安全性 (Safety):通过 Q-Gating 机制,在 RL 尚未学会正确动作的初期,系统会自动回退到 BC 动作,大大减少了机械臂撞击桌面的风险。
- 动作互补:在视频分析中发现,Q2RL 聪明地将 BC 用于大范围粗略移动(Grab),将 RL 用于接触丰富的高精度对准(Insertion)。
总结与局限
Q2RL 成功将“模仿学习”的稳定性与“强化学习”的上限结合在了一起。尽管它目前需要模型能直接输出 Likelihood(如 Gaussian 策略),对于新兴的 Diffusion Policy 支持稍显薄弱,但其提供的“门控引导”思路无疑是机器人迈向自主进化的重要一步。
未来,我们期待看到更多基于生成式模型(如 Flow Matching)的价值提取研究,进一步消融离线与在线学习的边界。
本文由资深学术主编重构。