This paper provides a comprehensive survey of World Models for Robot Learning, categorizing them as predictive representations of environmental evolution under action. It focuses on the transition from reactive Vision-Language-Action (VLA) policies to predictive-control paradigms, highlighting state-of-the-art achievements in coupling video generative models with robotic decision-making.
Executive Summary
TL;DR: The robotics field is undergoing a paradigm shift from reactive "Vision-Language-Action" (VLA) policies to predictive World Models. This survey systematizes how predicting the future—whether in pixel space or latent space—serves as the ultimate inductive bias for complex robot control. By moving beyond simple "next-token" prediction to "next-state" imagination, robots are gaining the foresight needed for long-horizon tasks and safer autonomous interaction.
Academic Positioning: This is a seminal survey that organizes the fragmented landscape of embodied AI, moving from modular "predict-then-act" pipelines to unified foundation-scale architectures where world modeling is the core engine of intelligence.
Problem & Motivation: The Limits of Reactivity
Current SOTA models like RT-2 or OpenVLA are primarily reactive. They map an image to an action much like an LLM maps a prompt to a word. However, physical reality is unforgiving. Reactive policies suffer from:
- Compounding Errors: Small mistakes in lead to states never seen during training.
- Lack of Physical Intuition: They don't "understand" that an object will fall if pushed off a table.
- Short Horizons: Without a "mental map" of the future, they cannot plan complex multi-stage maneuvers.
The authors argue that a World Model—a predictive bridge from semantic intent to physically realizable behavior—is the missing link.
Methodology: A Taxonomy of Predictive Control
The paper reframes the relationship between world models and policies through a unified probabilistic lens. If we consider the joint distribution , we can derive:
- Policy Model: Marginalizing out the visual future.
- Controllable World Model: Predicting future states conditioned on action .
- Inverse Dynamics: Recovering from a sequence of .
Key Architectural Paradigms:
- IDM-Style (Decoupled): A video generator "imagines" the task; a separate model figures out the actions to get there.
- Single-Backbone (Unified): Observations and actions are processed as tokens in a shared Transformer (e.g., Cosmos Policy).
- MoE/MoT (Expert-Coupled): Specialized streams for video and action interact via cross-attention.
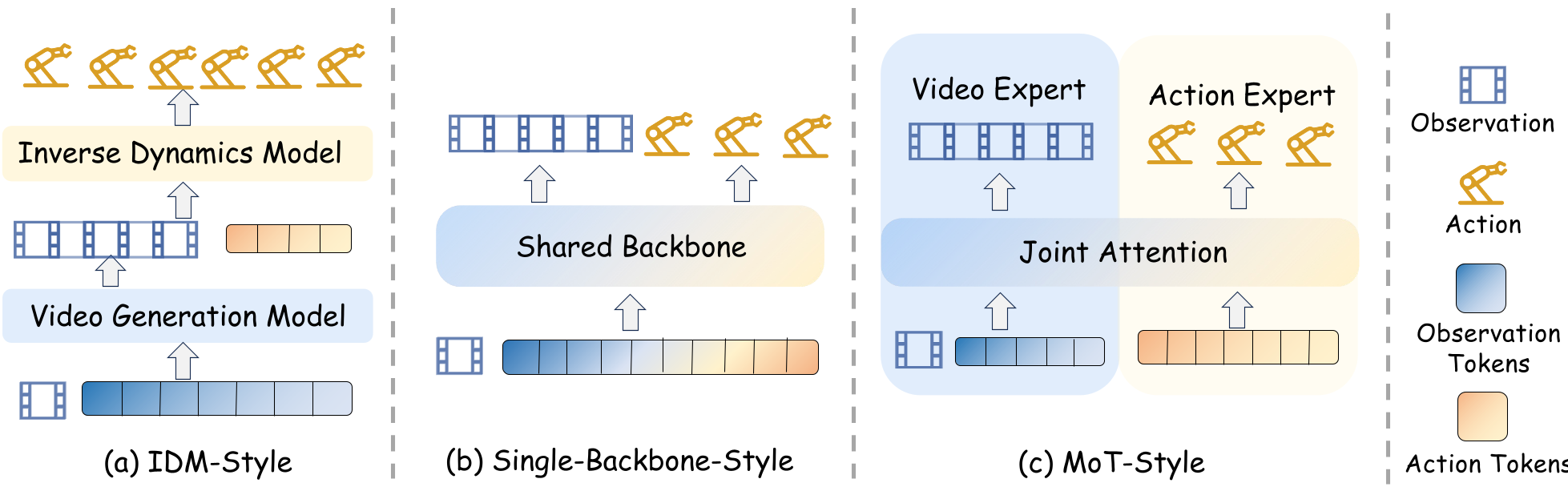 Figure 1: Representative architectural paradigms showing the evolution from decoupled pipelines to unified generative backbones.
Figure 1: Representative architectural paradigms showing the evolution from decoupled pipelines to unified generative backbones.
World Model as Simulator: The "Digital Rehearsal"
One of the most profound insights is the use of world models as Learned Simulators. Instead of training in slow, brittle physics engines (like Gazebo or Isaac Sim), we can train VLA policies inside a Video World Model.
- Imagination-Driven RL: Policies "rehearse" in the world model, receiving rewards based on predicted visual outcomes.
- Verification & Ranking: At inference time, the robot generates three possible action plans, "dreams" the outcomes of all three, and executes the one that looks most successful.
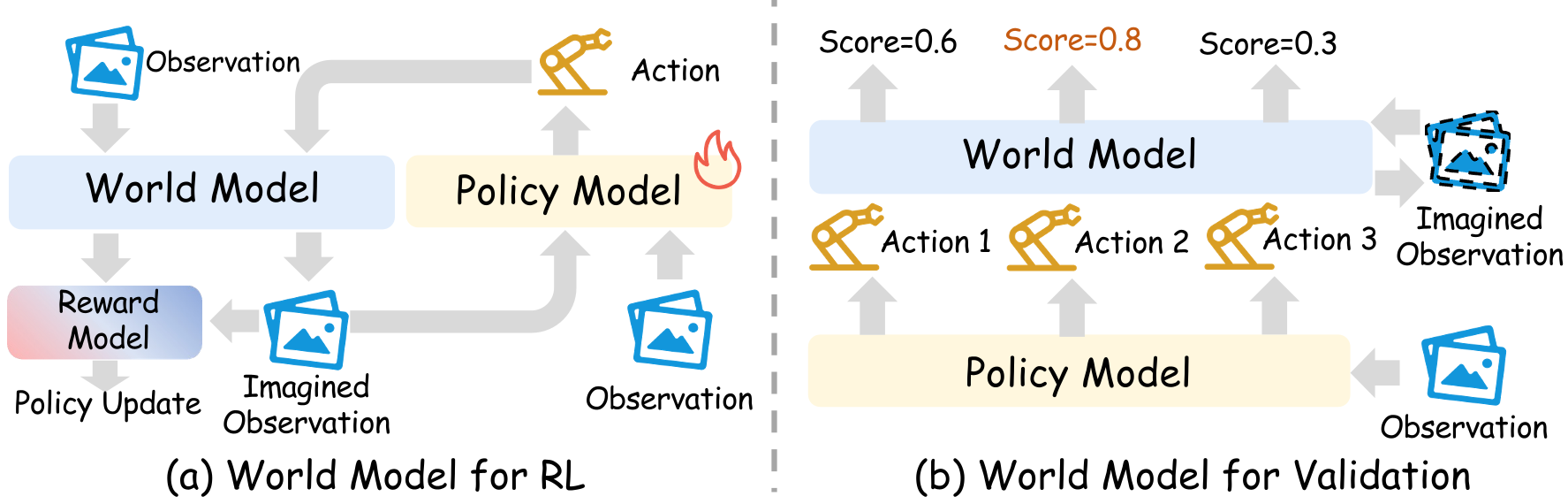 Figure 2: Using World Models for Reinforcement Learning (training) and Validation (inference-time ranking).
Figure 2: Using World Models for Reinforcement Learning (training) and Validation (inference-time ranking).
Experiments & Results: Is Imagination Real?
The survey aggregates results across standard benchmarks like LIBERO. The results are clear:
- Coupled Models Win: Models that use a shared backbone (e.g., Cosmos Policy at 98.5% avg) or MoT-style fusion (LingBot-VA at 98.5% avg) significantly outperform early decoupled attempts.
- Long-Horizon Robustness: The biggest delta is seen in the "Long" suite of LIBERO, where world models help maintain task consistency.
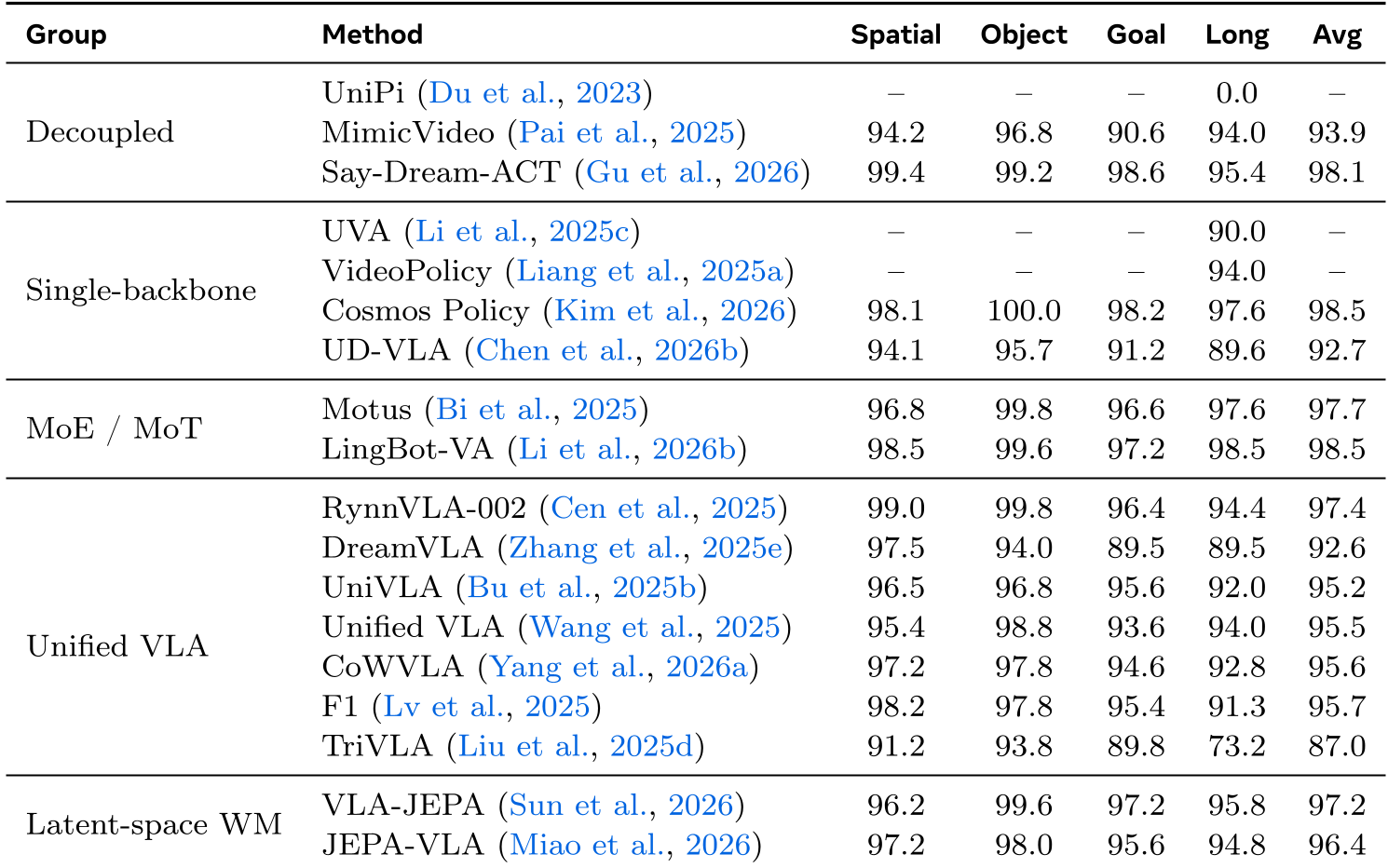 Table 1: Success rates on LIBERO suites across different world-model paradigms.
Table 1: Success rates on LIBERO suites across different world-model paradigms.
Critical Analysis & Conclusion
While "Video Generation" is currently the dominant instantiation of world models, the authors identify several bottlenecks:
- Causal Conditioning: A model might generate a video of a cup moving because it thinks that's what should happen, not because the action caused it. This leads to a lack of precise control.
- Efficiency: Iterative denoising (Diffusion) is too slow for 50Hz real-time robot control.
- Missing Modalities: Current models are "all eyes and no feel." Real world models must integrate Tactile and Force feedback.
Takeaway
The future of robotics isn't just "Better Perception" or "Bigger VLA." It is Foundation World Models—reusable, action-conditioned simulators that allow robots to understand the consequences of their actions before the motors ever move.