WorldAgents is a multi-agent framework that leverages 2D foundation image models (like Flux.2) and Vision-Language Models (VLMs like GPT-4) to synthesize expansive, 3D-consistent worlds. By framing 3D generation as an iterative agentic process, the method achieves superior photorealism and navigability compared to prior video or depth-based benchmarks.
TL;DR
Can models trained only on flat pixels actually "understand" the 3D world? WorldAgents answers with a resounding "Yes." By orchestrating a multi-agent system—featuring a VLM Director, an Inpainting Generator, and a 2-stage Verifier—the researchers from TU Munich demonstrate that 2D foundation models like Flux.2 and GPT-4 can be guided to "extrude" highly complex, 360-degree navigable 3D worlds from mere text prompts.
The Motivation: Moving Beyond "Flat" Intelligence
The core tension in 3D computer vision today is the Data Gap. We have billions of 2D images but very few high-quality 3D environments to train on. While 2D generators like Stable Diffusion or Flux can create stunning imagery, they are "spatially illiterate" in isolation—moving the camera often results in objects morphing, disappearing, or breaking the laws of physics.
The authors' key insight: 2D images are projections of a 3D reality. Therefore, 2D models must have implicit spatial knowledge buried in their weights. To extract it, we don't need more data; we need a "managerial" layer to enforce consistency.
Methodology: The Agentic Pipeline
WorldAgents replaces the typical rigid pipeline with a collaborative agentic loop.
1. The Director (The Brain)
A VLM (like GPT-4) acts as the high-level architect. It analyzes what has already been built and describes what should be in the next unexplored corner. It prevents the model from "wandering off" or repeating objects (semantic drift).
2. The Generator (The Builder)
The generator doesn't just "guess" the next view. It renders a partial view from the existing 3D reconstruction (using 3D Gaussian Splatting) and then uses 3D-aware inpainting to fill in the gaps. This anchors the new pixels to the existing geometry.
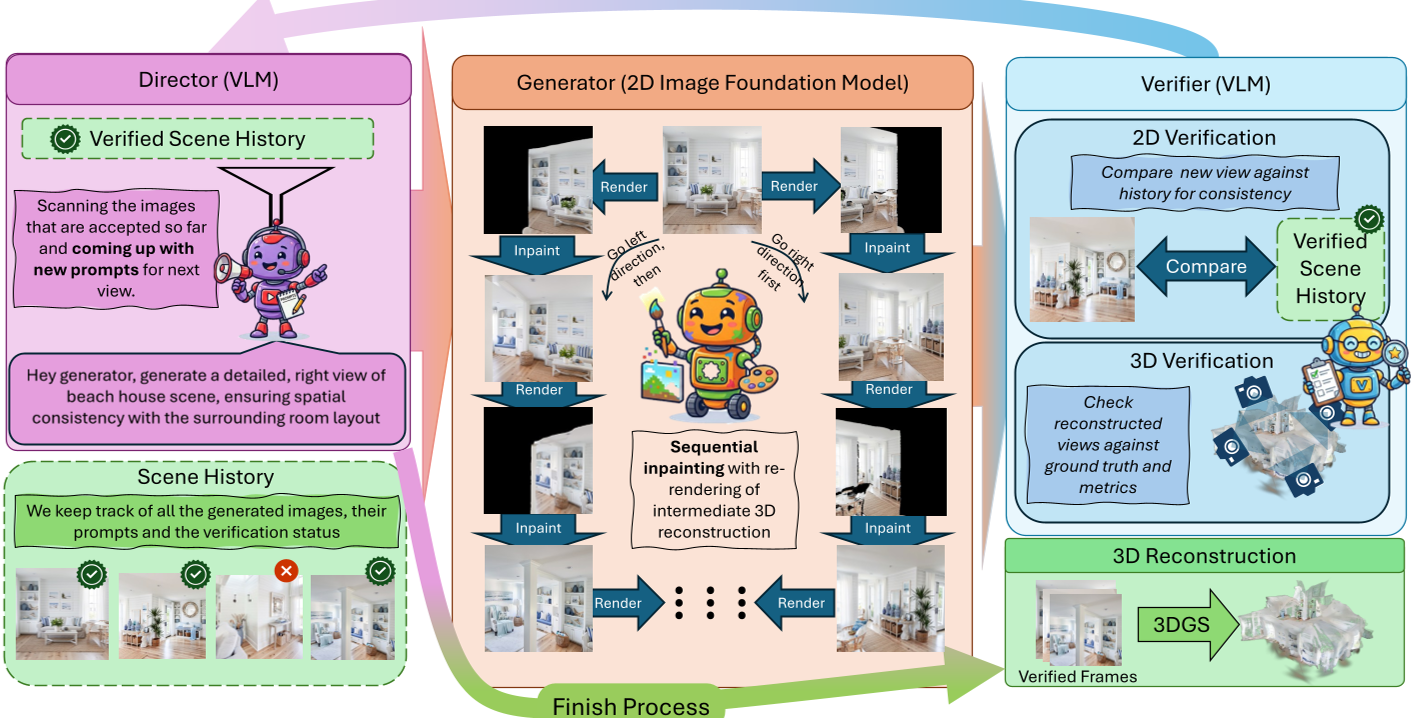
3. The Two-Stage Verifier (The Quality Control)
This is the "Zero-Tolerance" auditor.
- 2D Stage: Checks if the image looks good and matches the prompt.
- 3D Stage: Temporarily inserts the image into the 3D scene and checks if it breaks the math (re-rendering metrics like PSNR and SSIM). If the image causes "blur" or "ghosting," it is discarded and re-sampled.
Experiments & SOTA Results
The researchers tested combinations of state-of-the-art models including Flux.2, GPT-4, and Qwen. The results show a massive jump in realism compared to previous stalwarts like Text2Room.

| Method | CLIP Score (Prompt Alignment) | CLIP-IQA (Quality) | | :--- | :--- | :--- | | Text2Room | 22.27 | 0.27 | | WorldExplorer | 24.49 | 0.58 | | Ours (Flux.2 + GPT-4) | 26.79 | 0.89 |
The ablation studies confirmed that the Verifier and Inpainting modules were non-negotiable. Without them, the scenes lacked "loop closure"—the ability to return to the same spot and see the same objects.
Critical Analysis & Future Outlook
While WorldAgents creates stunning static worlds, the process is computationally heavy, taking roughly 25 minutes per scene on an A6000 GPU. Furthermore, the reliance on an external "reconstruction" step (3DGS) means the model isn't truly "thinking" in 3D natively; it is being forced to be consistent by the verifier.
However, the takeaway for the industry is massive: Agentic feedback loops are the new frontier for grounding LLMs/VLMs in reality. As we move toward 4D (dynamic) scenes, the "Director/Generator/Verifier" paradigm will likely become the standard for creating interactive digital twins and metaverse assets.
Summary (Takeaway)
WorldAgents proves that the "World Model" capability is already latent in our best 2D models. By treating these models as agents rather than just functions, we can synthesize coherent, immersive 3D realities that were previously thought impossible without massive 3D training sets.
