WorldCache is a training-free caching framework designed to accelerate Diffusion Transformer (DiT) based video world models. By replacing the traditional static "Zero-Order Hold" feature reuse with perception-constrained dynamical approximation, it achieves a 2.3× inference speedup on Cosmos-Predict2.5 while preserving 99.4% of baseline quality.
TL;DR
Generating high-fidelity, physically consistent videos with Diffusion Transformers (DiTs) is notoriously slow. WorldCache is a new training-free framework that accelerates these "World Models" by up to 2.3× with virtually no loss in quality (99.4% retention). It moves beyond simple "skip-and-copy" caching by using motion-aware logic and saliency-weighted probes to ensure that speed never comes at the cost of physical reality.
The "Zero-Order Hold" Trap
In the world of video diffusion, consecutive denoising steps are highly redundant. Prior works like DiCache and FasterCache exploit this by "caching" deep transformer layers and skipping them if the change (drift) between steps is small.
However, these methods suffer from a Zero-Order Hold (ZOH) problem: they treat cached features as static snapshots. In a video of a car driving past a forest, the massive amount of "static" trees masks the "dynamic" movement of the car. If the cache triggers based on the average global drift, the car becomes a "ghost"—a blurred, incoherent mess. For World Models used in robotics or autonomous driving, these artifacts aren't just ugly; they are functional failures.
Methodology: Perception-Constrained Dynamical Caching
WorldCache replaces the brittle ZOH assumption with a pipeline designed to understand what is moving and how it's moving.
1. Causal Feature Caching (CFC)
Instead of a fixed threshold, CFC uses a "velocity" proxy derived from the raw latent input. If the scene has fast dynamics, the threshold tightens, forcing the model to recompute rather than skip.
2. Saliency-Weighted Drift (SWD)
Not all pixels are created equal. SWD calculates a saliency map based on the channel-wise variance of probe features. High variance usually highlights edges and objects (foreground). By weighting the drift signal toward these regions, WorldCache ensures that even a tiny movement in a salient object triggers a recomputation, while background noise is ignored.
3. Optimal Feature Approximation (OFA)
When the model does skip, it doesn't just copy. OFA uses Optimal State Interpolation (OSI)—a least-squares vector projection—to align the cached history with the current trajectory. It optionally uses Motion-Compensated Warping to spatially align features, preventing the "drift" that usually kills long-horizon video generation.
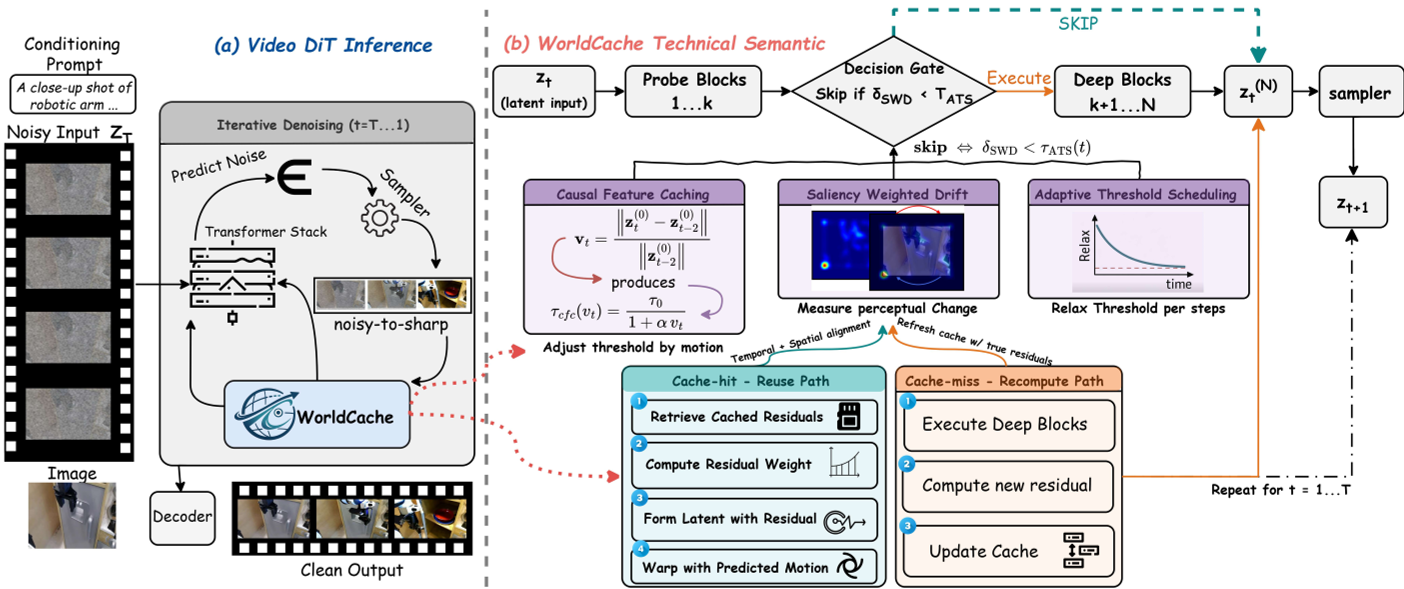 Figure 1: The WorldCache Pipeline. Note the interplay between the Probe, CFC/SWD decision logic, and the OFA approximation.
Figure 1: The WorldCache Pipeline. Note the interplay between the Probe, CFC/SWD decision logic, and the OFA approximation.
4. Adaptive Threshold Scheduling (ATS)
Denoising typically follows a "structure-then-detail" path. ATS exploits this by keeping the cache threshold strict during early steps (where the physical layout is decided) and relaxing it aggressively during the final refinement steps.
Experimental Results: SOTA Efficiency
The authors tested WorldCache on the Cosmos-Predict2.5 (2B & 14B) and WAN2.1 models using the PAI-Bench (Physical AI Benchmark).
- Speedup: Reaches 2.3× on Cosmos-2.5-2B.
- Fidelity: Maintained an overall score of 0.745 (vs. 0.748 baseline) on Text-to-World tasks.
- Robotics: On the EgoDex-Eval benchmark, WorldCache maintained higher PSNR and SSIM than previous SOTA caching methods, proving it handles hand-object interactions far better.
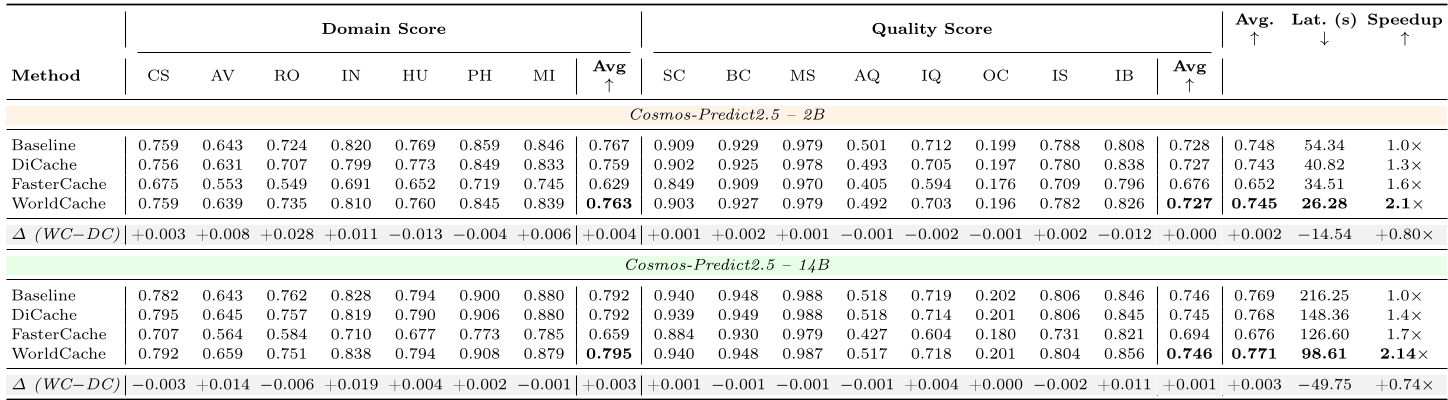 Table 1: Comparison on PAI-Bench. WorldCache (WC) consistently occupies the "sweet spot" of high speed and high domain/quality scores.
Table 1: Comparison on PAI-Bench. WorldCache (WC) consistently occupies the "sweet spot" of high speed and high domain/quality scores.
Visual Evidence: No More Ghosts
The qualitative results highlight the stark difference in "cleanliness." While previous methods like DiCache produce ghosting on moving vehicles or pedestrians, WorldCache maintains object persistence.
 Figure 2: WorldCache (c) vs. DiCache (b). Notice the red boxes in (b) showing ghosting and deformation, which are corrected in (c).
Figure 2: WorldCache (c) vs. DiCache (b). Notice the red boxes in (b) showing ghosting and deformation, which are corrected in (c).
Conclusion & Insight
WorldCache represents a shift from "heuristic-based skipping" to "principled approximation." By treating DiT caching as a dynamical system identification problem, it solves the primary bottleneck of video world models: the high cost of autoregressive sampling.
The key takeaway for the industry is the "Invest & Spend" strategy: spend compute on high-quality saliency-aware decisions and structural denoising steps, then harvest massive speedups by relaxing the constraints once the physical backbone of the video is secure.