X-World 是由小鹏汽车 GWM 团队开发的受控自我中心多摄像头生成式世界模型(World Model)。该模型基于 WAN 2.2 架构,通过动作条件的视频生成技术,能够根据驾驶指令和场景约束(如动态代理、道路元素和文字描述)生成高度一致的 360 度环视视频流,旨在为端到端自动驾驶(VLA 策略)提供可扩展、可复现的闭环仿真环境。
TL;DR
小鹏汽车 GWM 团队发布了 X-World,这是一个专为端到端自动驾驶设计的生成式世界模型。它不仅能生成电影级的 360 度环视驾驶视频,更核心的突破在于其强受控性与实时交互能力:你可以给它一个驾驶动作(Action),它能即时反馈出对应的视觉演变,并支持对路标、行人和天气进行精细化编辑。
1. 背景定位:为什么评估是端到端的“深水区”?
随着 Vision-Language-Action (VLA) 模型成为主流,传统的模块化测试(如检测 AP)已不再适用。端到端模型需要的是闭环评测——但在现实中测试“切入车流”或“鬼探头”不仅危险且不可复现。
现有的视频生成模型往往是“黑盒”,难以实现精确的动力学反馈。X-World 的出现,本质上是为自动驾驶策略提供了一个带有“后悔药”机制的高精度模拟器。
2. 核心挑战与 Insight
构建一个合格的可驾驶世界模型需要解决三个硬骨头:
- 动作因果性 (Action Causality):踩油门画面必须加速,打方向盘视角必须偏转。
- 跨视图一致性 (Cross-view Consistency):左侧相机看到的车头,必须在右侧相机看到对应的车尾,几何逻辑不能乱。
- 长时稳定性 (Temporal Stability):不能开着开着路就消失了,或者画面模糊成一团。
3. 方法论详解:从“视频生成”到“物理模拟”
X-World 基于业界领先的 WAN 2.2 (5B) 架构进行改造。
架构解析
- 视点-时间自注意力 (View-temporal Attention):在 Transformer 层中交替进行时间维度和相机维度的注意力计算,强制让 7 个摄像头的 Token 进行“对表”,确保空间逻辑统一。
- 两阶段训练策略:
- Stage-I (受控能力植入):通过 Cross-Attention 注入 Ego-Action(速度、曲率等)、动态障碍物坐标和静态车道线。
- Stage-II (因果流式演化):这是本文的精髓。作者将模型从双向(Bidirectional)改为因果(Causal)机制,并使用 Self-forcing 训练策略。
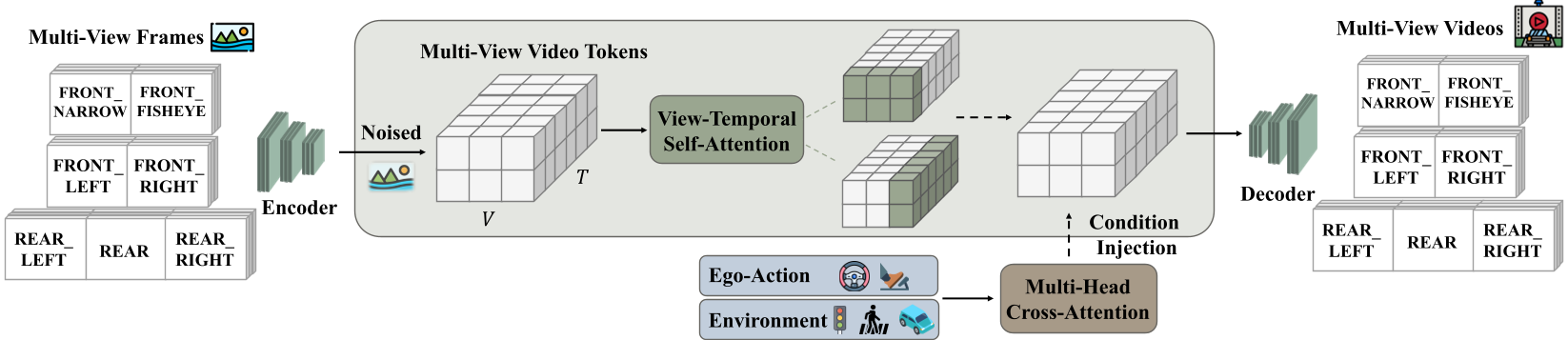 图 1:X-World 整体架构,展示了如何通过各种 Condition 驱动多视频流生成。
图 1:X-World 整体架构,展示了如何通过各种 Condition 驱动多视频流生成。
4. 实验结果:不仅仅是画出来的
动作遵循与场景编辑
实验显示,X-World 能够根据输入的动作序列(如 Turn Left, Lane Change)生成物理上完全合理的画面(见图 4)。更有价值的是其**反事实分析(Counterfactual Analysis)**能力:
- 原本视频中车辆在跟车,我们可以强行输入“变道绕行”的指令,观察生成模型反馈的安全性。
- 我们可以手动在画面中“放置”一个骑行者(Cyclist),测试 VLA 模型的规避反应。
 图 2:针对动态障碍物和静态道路元素的精确控制演示。
图 2:针对动态障碍物和静态道路元素的精确控制演示。
长时演化表现
得益于 Rolling KV Cache,X-World 支持长达 24 秒以上的稳定视频生成,这足以覆盖绝大多数城市路口交互场景的评测需求。
 图 3:24 秒长时序列生成,画面逻辑依然保持高度连贯。
图 3:24 秒长时序列生成,画面逻辑依然保持高度连贯。
5. 深度洞察:工业界的野心
小鹏团队在文中明确指出了 X-World 的三大应用路径:
- VLA 2.0 的闭环考场:不再依赖 Log 回放,而是真正让 AI 在视频里“开车”。
- 在线强化学习 (Online RL) 的温床:在虚拟视频空间里进行低成本的探索与试错,学习从事故边缘恢复。
- 零样本风格迁移 (Zero-shot Style Transfer):只需改变文本 Prompt,就能将中国路况视频瞬间转换为“德国下雨的夜晚”,极大地加速了海外市场的模型适配。
总结
X-World 证明了:基于 DiT 的大视频模型通过精妙的条件注入与因果训练,完全可以胜任“世界模拟器”的角色。这不仅是学术上的 SOTA,更是迈向通用自动驾驶(L4+)的关键基础设施。
局限性分析:尽管视频质量优秀,但在处理极高动态的极端碰撞物理效果时,纯视频空间建模可能仍缺乏显式的三角几何约束。未来结合 3DGS 语义增强或许是进一步提升稳定性的方向。