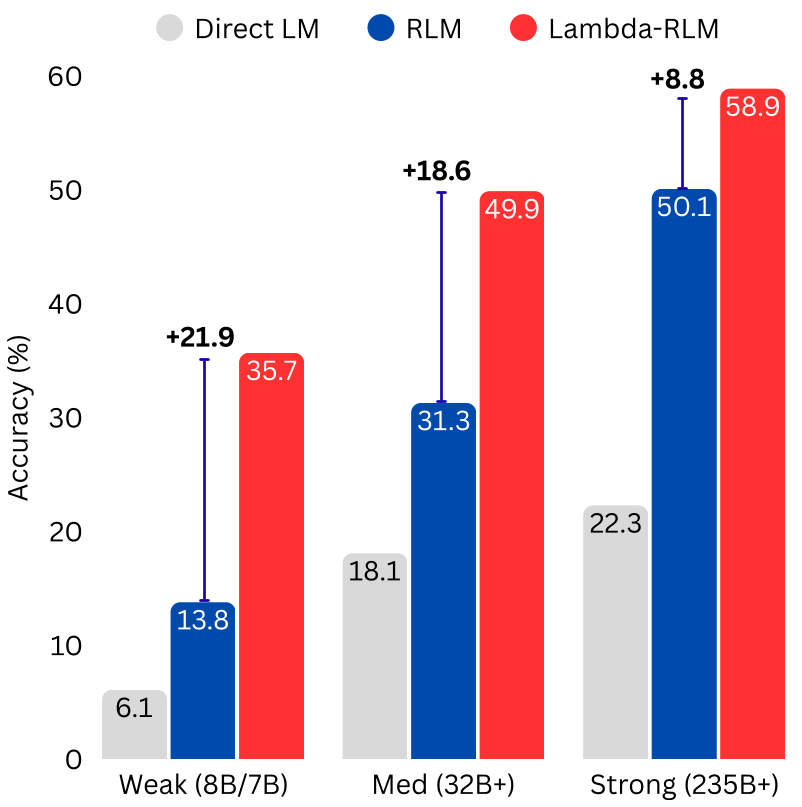
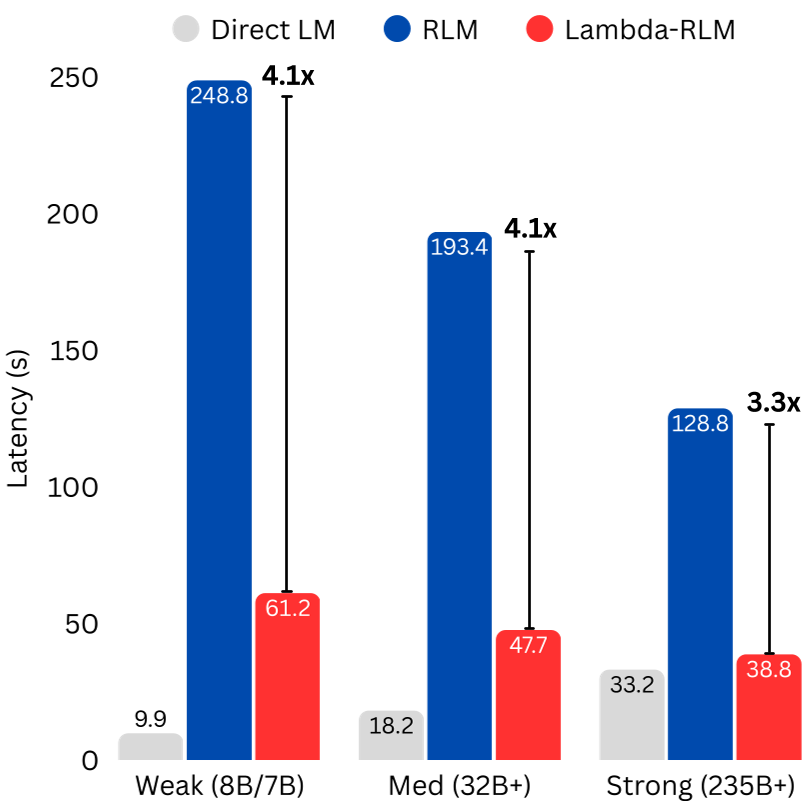
The paper introduces λ-RLM, a long-context reasoning framework that replaces open-ended LLM code generation with a typed functional runtime grounded in λ-Calculus. By using a library of pre-verified combinators (e.g., MAP, REDUCE), λ-RLM achieves SOTA performance across 4 tasks, outperforming standard Recursive Language Models (RLMs) in 81% of comparisons with up to +21.9 accuracy points and 4.1x latency reduction.
Executive Summary
TL;DR: λ-RLM is a breakthrough framework that tames the "wild west" of LLM-driven recursive reasoning. By replacing free-form Python generation with a rigid, typed functional runtime based on λ-Calculus, it allows even small 8B models to outperform massive 405B models on 128K-context tasks. It guarantees termination, bounds costs, and slashes latency by up to 4x.
Context: This work moves the needle from "LLM-as-Agent" (stochastic and prone to failure) toward "LLM-as-Callable-Oracle" (deterministic and verifiable). It is a SOTA-shattering entry in the field of inference-time scaling and neuro-symbolic integration.
The Problem: The "Coding Tax" and Stochastic Rot
When prompts exceed the native context window (e.g., 128K tokens), LLMs suffer from Context Rot—an exponential decay in accuracy. While Recursive Language Models (RLMs) tried to solve this by letting the LLM write its own decomposition code, they introduced Stochastic Control Failures:
- Syntax Errors: The model writes code that won't run.
- Infinite Recursion: The model forgets to define a base case.
- High Variance: Every "turn" in the REPL loop adds latency and potential for hallucination.
The authors argue that we shouldn't ask an LLM to build the "pipes" of the recursion; we should only ask it to process the "water" flowing through the leaves.
Methodology: Tying the Knot with λ-Calculus
The core innovation is λ-RLM, which treats long-context reasoning as a structured functional program.
1. The Combinator Library
Instead of arbitrary code, the system uses a trusted library:
- SPLIT/PEEK: Deterministic partitioning.
- MAP/REDUCE: Higher-order functions to distribute and aggregate reasoning.
- M: The only neural component—the LLM itself, limited to small, safe chunks.
2. The Y-Combinator Logic
In λ-Calculus, recursion is handled by fixed-point combinators. λ-RLM defines the solver such that: This ensures the "knot" of recursion is tied symbolically. The LLM never sees the "loop"—it only sees the specific sub-problem it is assigned to solve.
Theoretical Guarantees: Math Over Magic
Unlike standard agents, λ-RLM provides:
- Guaranteed Termination: By induction, every step strictly reduces the input size until the base case.
- Optimal Partitioning: The authors prove that the cost-minimizing partition size is or calculated via a closed-form derivative.
- Power-Law Decay: While direct LLM inference decays exponentially (), λ-RLM decays only via a power law, making it far more robust for massive inputs.
Experiments: Scaling Small Models to Giant Feats
The team tested λ-RLM across 9 models (Qwen, Llama, Mistral) on tasks like searching through 128K documents and pairwise reasoning.
Key Breakthroughs:
- Scale Substitution: A Qwen-8B model using λ-RLM statistically tied with a Llama-70B using standard RLM, while being 3.1x faster.
- Efficiency: In the OOL-Pairs task, λ-RLM was 6.2x faster because the quadratic complexity was handled symbolically by the
CROSSoperator, not the LLM.

Critical Analysis & Conclusion
Takeaway
The era of "unconstrained agents" may be ending. λ-RLM proves that by restricting what an LLM can do (control flow), we actually enhance what it can achieve (reasoning). It effectively separates semantic understanding from structural orchestration.
Limitations
The system is currently limited by its fixed combinator library. For highly creative, non-standard tasks like CodeQA, free-form RLMs still occasionally win because they can perform "backtracking" or "adaptive batch sizing" that isn't yet in the λ-library.
Future Work
The next frontier is extending this "typed runtime" to multi-modality and RL-based optimization of the combinator selection itself. As the authors put it, the future of AI reliability lies in providing models with high-integrity, verifiable environments.
Main Result Visualization: