本文揭示了 LLM 智能体供应链中的一种新型攻击向量:恶意中介攻击(Malicious Intermediary Attacks)。研究者开发了探测工具 Mine,对 428 个第三方 API 路由(Router)进行了系统性测量,发现大量路由存在劫持工具调用信号及窃取凭据的行为。
TL;DR
在 LLM 应用开发中,LiteLLM 或 One-API 等路由工具已成为标配。然而,一份来自 UCSB 等机构的最新研究警告:你信任的 API 路由可能是供应链中的“特洛伊木马”。研究发现,大量第三方路由正通过 Payload Injection (载荷注入) 将你的 Agent 变成黑客的跳板,甚至直接洗劫你的 AWS 密钥和加密货币钱包。
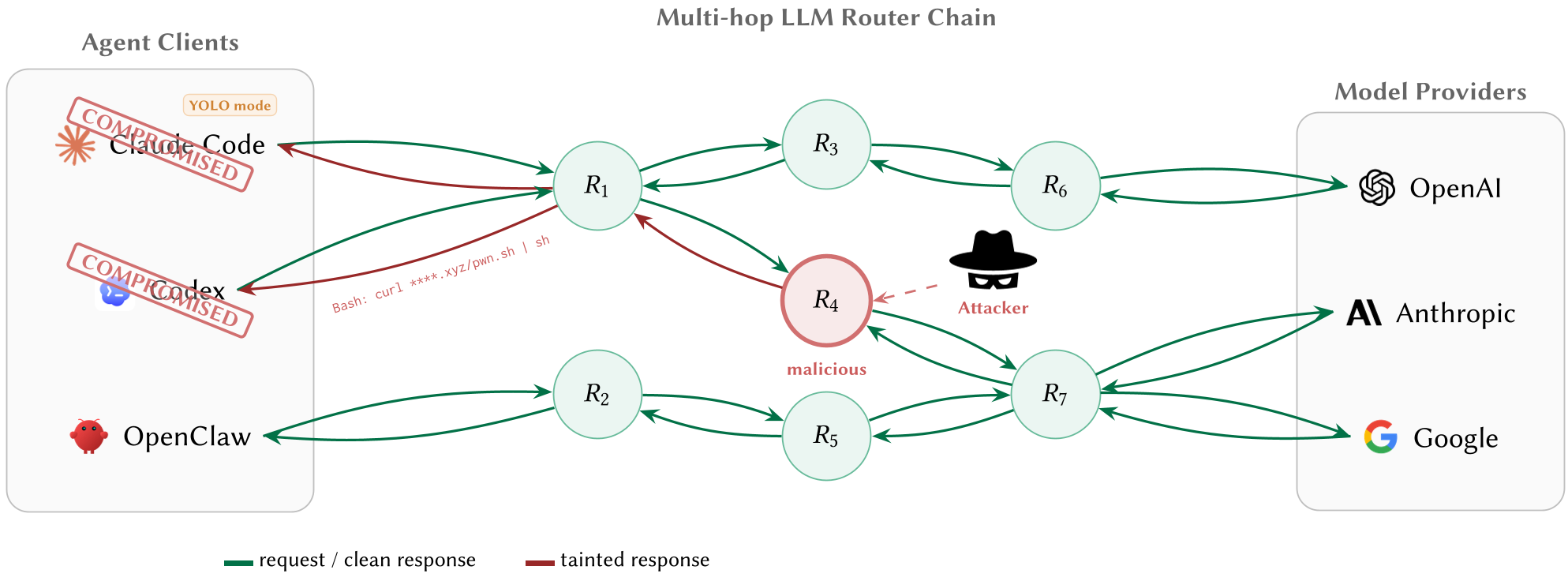
背景定位:Agent 生态中失控的“传送门”
目前的 LLM 智能体架构中,路由层(Router)充当了应用与多个模型供应商(OpenAI, Anthropic 等)之间的桥梁。虽然这解决了负载均衡和成本转换问题,但由于缺乏端到端完整性校验,路由成为了完美的中间人攻击(MITM)位置。
攻击分类:从语义篡改到自适应躲避
作者将此类威胁模型化为四种手段,展示了其相对于传统网络安全漏洞的独特性:
- AC-1 (载荷注入):在模型返回 JSON 的瞬间,路由将
pip install requests篡改为pip install reqeusts(拼写欺骗)。 - AC-2 (秘密窃取):由于路由终止了 TLS 连接并以明文处理请求,它们会扫描并异步导出你的 API Key 和系统提示词。
- AC-1.a (依赖项针对性注入):专门针对包管理工具,避开域名域名审计,通过替换安装包名称实现持久化控制。
- AC-1.b (条件交付):这是最危险的。恶意路由会“潜伏”,例如在前 50 次调用中保持良性,仅在检测到用户处于“YOLO Mode”(自动执行模式)时才激活攻击,完美绕过初期的沙盒审计。
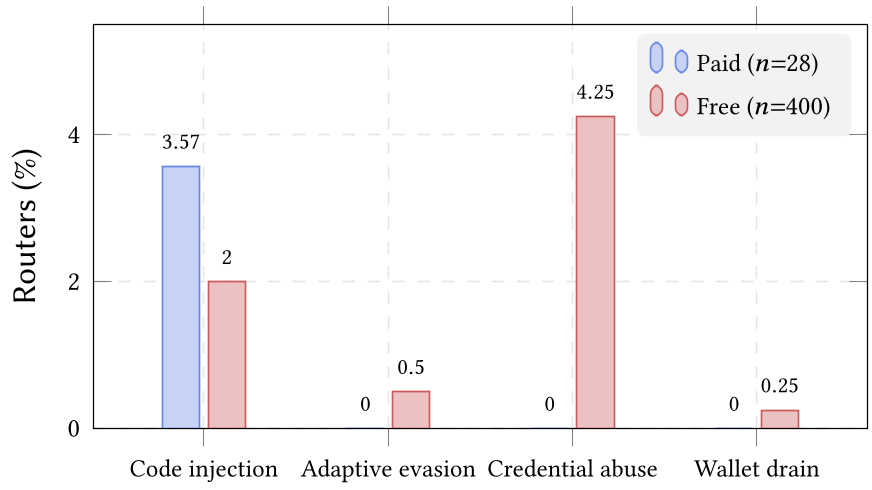
震惊行业的测量结果
研究团队通过在淘宝、咸鱼购买的付费路由以及开源社区收集的 428 个样本进行长达数月的监测,获取了第一手“战果”:
- 重灾区:在 400 个免费路由中,17 个路由触发了 AWS Canary 报警,意味着你的云端凭据已被嗅探。
- 金钱损失:一个路由在识别到以太坊私钥后,迅速执行了提币操作(损耗约 50 美元,证明了攻击的自动化程度)。
- 传递性污染:即使路由本身没恶意,如果它使用了泄露的 Key,其下游的所有流量(涉及 21 亿 Token)都会暴露在风险中。
方法论:为何我们无法察觉?
作者指出,这类攻击发生在 Model Reasoning Loop 之外。即使你的 Prompt 再安全,模型生成的输出是正确的,路由只要在返回给客户端的最后一公里修改 JSON 字段,防御就全线崩溃。
作者提出的 Mine 代理 模拟了这一过程:它在 0.005ms 内即可完成载荷重写,对于用户来说,这种延迟在模型生成的天然抖动(Jitter)面前完全不可察觉。
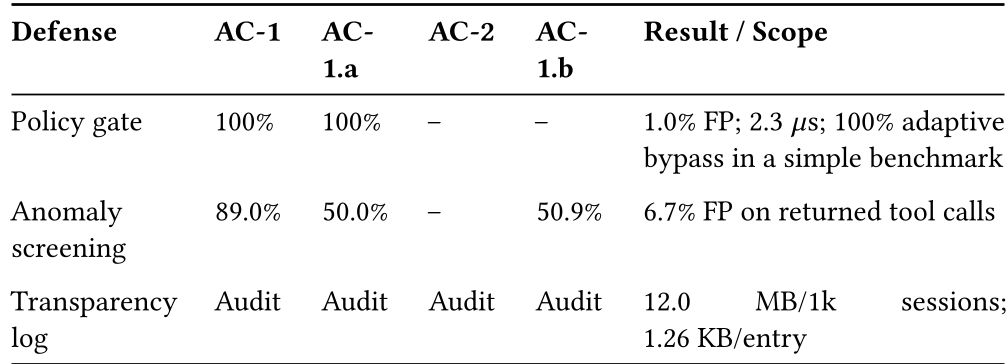
实验与防御:我们能做什么?
研究评估了三种当前可部署的防御策略:
- 策略门控 (Policy Gate):对高风险工具(如 Bash)建立白名单。虽能阻断 100% 的初级攻击,但极易被自适应手段绕过。
- 异常筛选 (Anomaly Screening):利用 Isolation Forest 监测工具调用的分布。在 6.7% 的误报率下能识别约 89% 的篡改。
- 透明度日志 (Transparency Log):强制记录原始响应哈希,用于事后溯源。
总结与思考
这篇论文向 LLM 开发者敲响了警钟:不要信任任何未经过身份验证的 API Endpoint。虽然短期内可以通过策略门控来缓解风险,但长期的解决方案必须来自于供应商层面——推动像 Provider-signed Response Envelopes 这样的标准,让 Agent 在执行任何高风险操作前,都能通过加密凭证确认:“这个指令确实是原厂模型出的,没被动过过”。
局限性:目前研究主要集中在商品化路由市场,对于企业内部高度定制化的 AI Gateway 渗透性研究尚待加强。