本文推出了 ZAYA1-8B,一个基于 Zyphra MoE++ 架构的推理强化型混合专家模型,拥有 700M 激活参数和 8B 总参数。该模型在全栈 AMD 算力平台上训练而成,仅凭不足 1B 的激活参数,在 AIME'25 和 HMMT'25 等硬核数学竞赛榜单上达到了 91.9% 和 89.6% 的惊人准确率,比肩甚至超越了 DeepSeek-V3.2 和 GPT-5-High 等巨型模型。
TL;DR
Zyphra 发布了 ZAYA1-8B 技术报告,这是一个“以小博大”的推理专家模型。它仅凭借 0.7B 的激活参数(总规模 8B),通过全栈 AMD 训练基础设施和一种名为 Markovian RSA 的测试时计算(TTC)技术,在 AIME、HMMT 等数学竞赛任务上强力“越级打怪”,其表现甚至触及了 GPT-5-High 和 DeepSeek-V3 的边界。
核心定位:打破“参数即正义”的信条,通过极致的架构设计与推理算法协同,实现顶级的推理密度。
痛点深挖:为何推理总是“重体力活”?
传统推理模型面临两大难题:
- 参数冗余:Dense 模型在生成每一个 Token 时都要激活全部参数,即便是在简单的逻辑环节,极其低效。
- 上下文过载:思维链(CoT)推理越深,KV-Cache 就越大。现有的递归聚合方法(如 RSA)会将多个候选推理支流堆叠,导致上下文长度呈爆炸式增长,推理速度急剧下降。
核心方法论:ZAYA1-8B 的三支箭
1. 架构重构:MoE++ 与 ZAYA1 路由器
相比于标准的 Transformer MoE,ZAYA1-8B 做了三项激进改动:
- CCA (Compressed Convolutional Attention):在压缩潜空间(Compressed Latent Space)进行序列混合,大幅减少了长上下文下的 KV-Cache 压力。
- MLP 路由器:弃用了简单的线性路由器,改用多层 MLP。实验证明,增加路由器的表达能力能显著提升专家选择的准确性,从而实现更自信(低熵)的专家调用。
- 残差缩放:精细控制深度网络中的残差流增长。
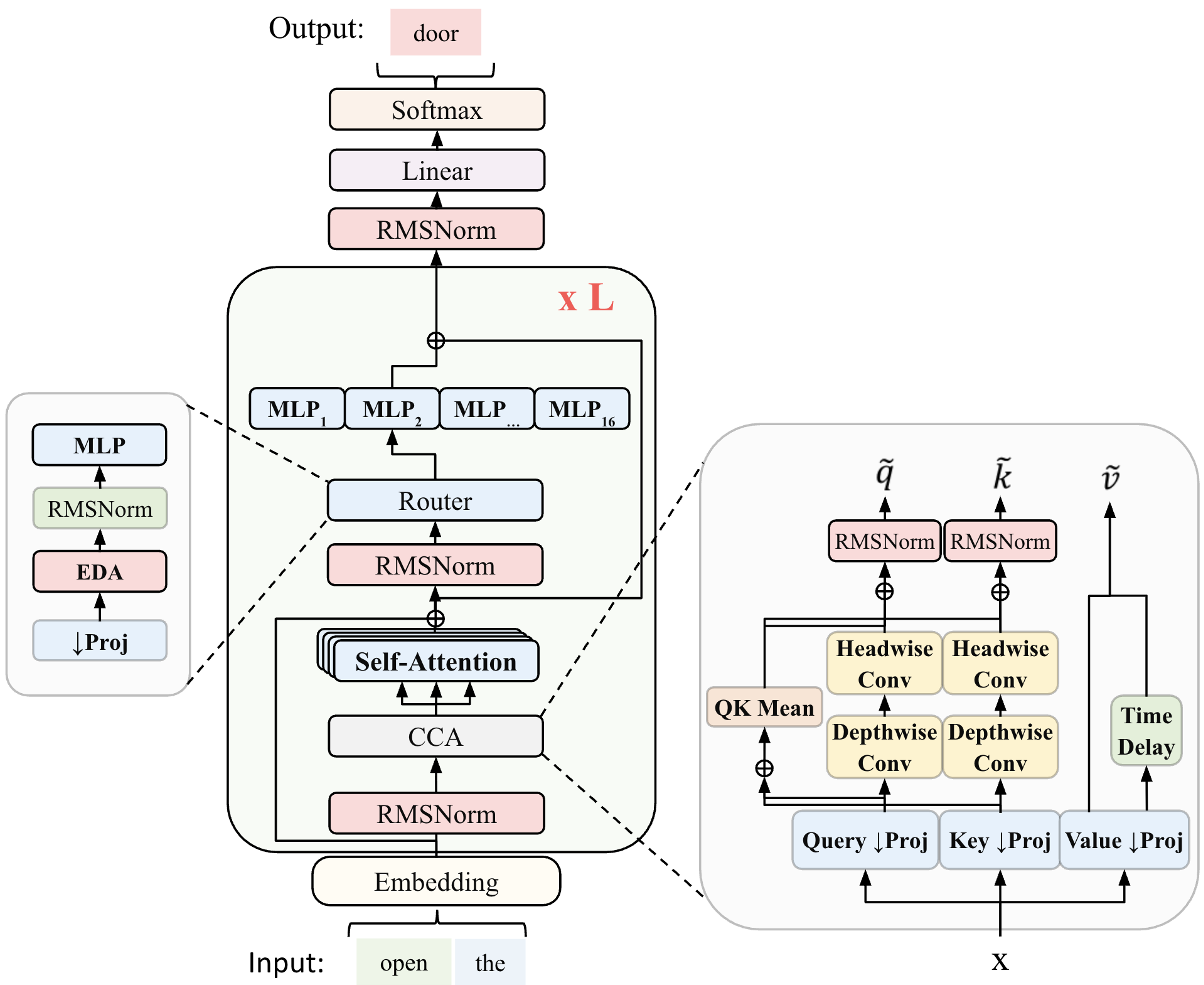 图 1: ZAYA1-8B 架构模型,重点展示了 CCA 注意力和 MLP 路由器的集成。
图 1: ZAYA1-8B 架构模型,重点展示了 CCA 注意力和 MLP 路由器的集成。
2. 训练的前置过滤:AP-Trimming (答案保留修剪)
为了让模型在只有 4K 长度的预训练初期就能学习长达 10K+ 的推理数据,作者提出了 AP-Trimming。
- 直觉:推理的前端是建模和规划,尾端是收尾。修剪掉推理链中间部分的冗余,但死死保住“开始部分的规划”和“最后的答案”,确保模型学到的是从逻辑起点到终点的映射,而非无头无尾的碎片。
3. 测试时计算的变体:Markovian RSA
这是 ZAYA1-8B 最硬核的黑科技。它结合了 RSA 的递归聚合与“马尔可夫思维”的边界感。
- 怎么做:生成 个候选推理链,但只取每个链条最后 个 Token(尾部)传递给下一轮聚合。
- 为何有效:这使得推理上下文是“有界”的。无论你推理多久、聚合多少次,预填充(Prefill)的显存占用始终维持在常量,解决了推理深度与计算资源之间的死循环。
实验与结果:小参数的奇迹
在 AIME'25 上,ZAYA1-8B 展现了恐怖的竞争力:
- 对比 DeepSeek-R1-0528:ZAYA1 以极小的激活规模实现反超。
- TTC 的魔力:引入 Markovian RSA 后,其性能从单轮的 88.3% 飙升至 91.9%。
 图 2: ZAYA1-8B 在不同激活参数量下的 AIME 表现,显著偏离了传统缩放曲线。
图 2: ZAYA1-8B 在不同激活参数量下的 AIME 表现,显著偏离了传统缩放曲线。
深度洞察:推理即过程,而非存储
ZAYA1-8B 的成功带来了一个关键启示:推理性能和事实记忆是解耦的。
- 大参数模型(如数百 B)强在博闻强识(MMLU 表现好)。
- 小激活模型(如 ZAYA1)强在逻辑密度。
通过将更多算力分配给“思考过程”(测试时计算)而非“静态权重”,我们可以用极低的硬件成本实现顶尖的逻辑能力。这不仅是学术上的突破,更是为移动端边缘推理指明了方向。
局限性与展望
尽管在逻辑推理上称王,但在常识性任务(MMLU-Pro)上,ZAYA1 依然无法完全弥补其物理参数容量较小带来的知识缺口。此外,模型当前在多轮 Agent 交互任务中略逊于专门针对此优化的模型。Zyphra 团队表示,未来将进一步探索 Agentic RL 和更深度的算力缩放。
总结:ZAYA1-8B 告诉我们,只要路由够准、思考够深,1B 级别的核心也能撬动 AGI 的大门。