本文推出了 ZEBRAARENA,一个基于程序化生成的诊断性模拟环境,用于研究工具增强型大语言模型(LLMs)中推理与动作(Reasoning-Action)的耦合能力。该环境利用知识最小化的 Zebra 逻辑谜题,通过控制缺失线索量来评估模型获取外部信息并整合进演绎推理的效率。
TL;DR
大模型真的会用工具吗?还是在“瞎猫碰死耗子”?最近的研究表明,LLM 在处理复杂逻辑时,即便手握搜索工具,也往往表现出极其低效的调用模式。ZEBRAARENA 是一个全新的诊断性模拟环境,它将经典的 Zebra(爱因斯坦)谜题通过“扣减线索”转化为一个部分可观测的推理解密任务。结果显示,顶级模型如 GPT-5 在该任务中虽然能解题,但工具使用成本比理论最优值高出 2.7 倍,揭示了当前模型在 Reasoning-Action Coupling (推演-行动耦合) 上的巨大鸿沟。
痛点深挖:为何现有 Benchmarks 测不准 Agent?
当前的 Agent 评估往往陷入两个极端:
- 重检索、轻推理:如 HotpotQA 等搜索任务,一旦搜到答案,剩下的推理如同儿戏。
- 重环境、轻逻辑:如 WebArena 或 Embodied AI,环境变数太多(弹窗、网络延迟、随机动力学),模型失败了你分不清是它“脑子笨”还是“手不灵”。
ZEBRAARENA 的核心直觉是:屏蔽一切外部知识干扰,只测逻辑。它通过程序化生成的 N×M 矩阵谜题,确保每个任务都有唯一解,且模型必须通过调用 API 获取缺失的线索。这就像是一场“限制资源”的密室逃脱,每走一步都有成本。
核心机制:ZEBRAARENA 的精密设计
ZEBRAARENA 将谜题转化为一个约束满足问题(CSP)。环境预设了两种工具:
- Fact Query (事实查询):直接查询某物是否在某处(如:1号房子住的是不是爱因斯坦?)。
- Relation Query (关系查询):查询高级逻辑关系(如:喝茶的人是不是住在喝咖啡的人左边?)。
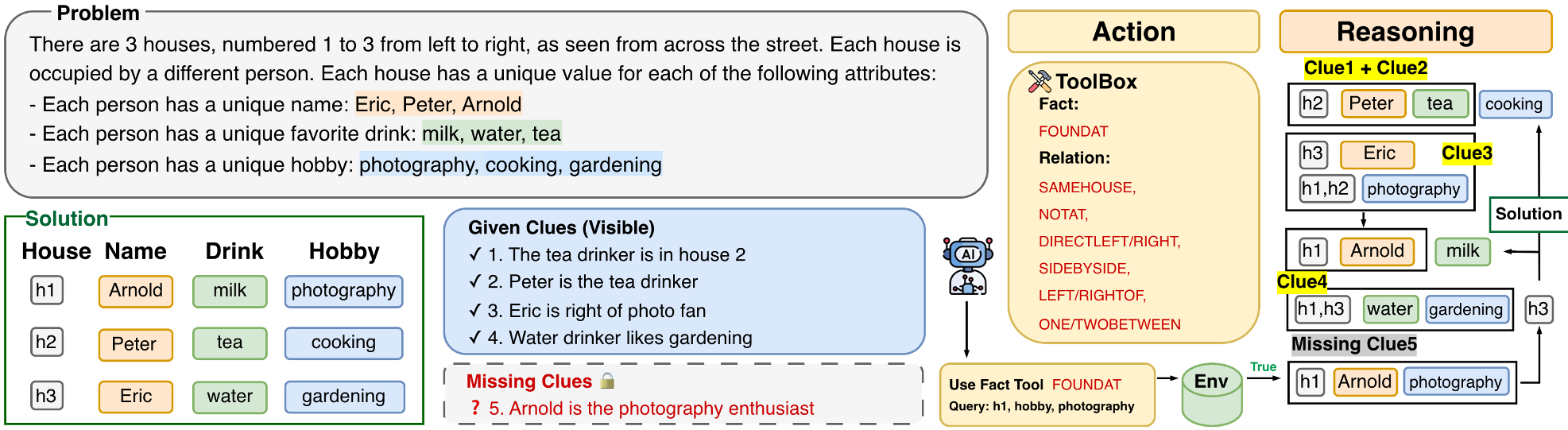 图 1:ZEBRAARENA 工作流。模型在 <think> 标签内进行推理,由于初始线索不足,必须通过 <query> 获取信息,最后给出 <solution>。
图 1:ZEBRAARENA 工作流。模型在 <think> 标签内进行推理,由于初始线索不足,必须通过 <query> 获取信息,最后给出 <solution>。
这种设计的巧妙之处在于:理论最优查询数 (K) 是可计算的*。这为衡量模型是否“啰嗦”提供了定量的金标准。
实验与结果:顶级模型的“平庸”表现
研究者测试了从 Llama 到 GPT-5 的多款模型,发现了以下惊人结论:
1. 准确率瓶颈
在 Small 难度下,强模型几乎能做到 100%,但随着矩阵扩大(Large 维度)和缺失线索增加,GPT-5 的表现也开始动摇。弱模型如 Llama-3.3-70B 在中等难度下就几乎全线崩溃,表现出极高的“信息获取不足(Insufficient Rate)”,即它甚至没搜集全必要的线索就急于猜答案。
2. 低效的冗余调用
这是本论文的核心洞察:Inefficiency Ratio (IR)。
- GPT-5:虽然准确率最高,但其工具调用次数平均是理论最优值的 1.7 到 3.7 倍。
- Gemini 2.5 Flash:表现出极度的“话痨”,每道题消耗的 Token 数高达 20k,而 GPT-5 仅需 1.2k。
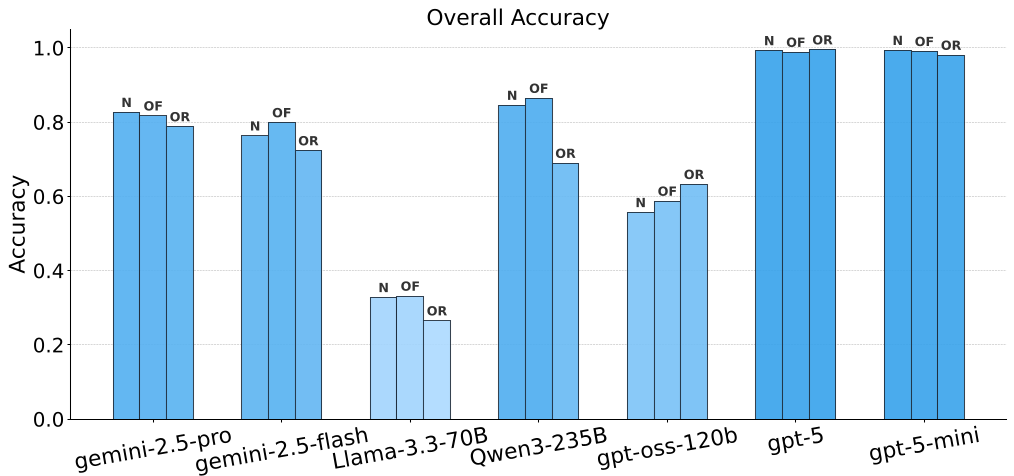 图 2:不同规模下的性能表现。右侧图表清晰地展示了 IR 指标随着搜索空间(Space Size)扩大而剧烈上升,说明模型难以在高复杂度下保持动作效率。
图 2:不同规模下的性能表现。右侧图表清晰地展示了 IR 指标随着搜索空间(Space Size)扩大而剧烈上升,说明模型难以在高复杂度下保持动作效率。
3. 预算焦虑
当在 Prompt 中告知模型“你只有 K* 次查询机会”时,模型的准确率会大幅下降。这意味着目前的模型极度依赖过量的冗余采样来弥补其规划能力的不足,一旦面临精确的资源预算,它们往往会在前期浪费掉关键的查询机会。
深度洞察:什么是真正的推理-动作耦合?
ZEBRAARENA 证明了,真正的 Agent 智能不在于它会用多少种 API,而在于它是否具备 Uncertainty Calibration (不确定性校准)。
优秀的 Agent 应该能意识到:“我当前的逻辑推导在这个点断了,所以我必须调用一个关于‘颜色’的关系查询来连接上下文。” 而目前的 LLM 基本是:“我不确定,所以我先把所有房子的属性都问一遍再说。”
总结
ZEBRAARENA 为我们提供了一面镜子。它指出,未来通往 AGI Agent 的道路上,搜索效率与逻辑严密性的权衡将是比单纯扩大模型参数更为关键的挑战。
局限性:目前的谜题仍属于静态逻辑逻辑,未来需要引入动态环境或含有“噪声线索”的设置,以更好地模拟现实世界。
启示:如果你正在开发 AI Agent,请不要只关注它的工具成功率,去看看它的 IR (不确定性冗余度) —— 那才是区分“平庸”与“顶尖”的真实边界。