本文提出了 FOSSA,一种基于 Transformer 的新型深度估计架构,专门用于从焦堆栈(Focus Stack)中恢复绝对尺度深度。通过引入“堆栈注意力机制(Stack Attention)”和全新的真实世界基准测试集 ZEDD,FOSSA 在多次测试中显著超越了现有 SOTA 方法,将误差降低了高达 55.7%。
TL;DR
普林斯顿大学的研究团队通过 FOSSA 架构和新的 ZEDD 数据集,打破了长期以来“从失焦恢复深度(Depth from Defocus, DfD)”方法难以在大规模真实场景中泛化的魔咒。FOSSA 凭借创新的堆栈注意力机制,实现了无需标定、Zero-shot 即可输出精确绝对尺度的深度图。
背景:为什么 DfD 这么难?
虽然单目深度估计(Monocular Depth Estimation)近期取得了巨大进步,但它们始终面临着**尺度二义性(Scale Ambiguity)**的问题。相比之下,DfD 通过分析一组不同焦距拍摄的照片(Focus Stack),利用光学成像原理直接推导绝对物理深度。
然而,DFD 长期以来受困于两个痛点:
- 数据贫瘠:由于高质量、带真实 LiDAR 深度的焦堆栈极难采集,现有模型大多在几十个合成场景上“圈地自萌”。
- 架构僵化:传统 CNN 架构难以有效捕捉多张图像之间微妙的像素级清晰度变化。
核心创新 1:FOSSA 架构
FOSSA(FOcuS Stack Attention Transformer)不再简单地拼接图像,而是将 Transformer 架构进行了“DfD 适配化”:
- 权重共享的 ViT 主干:利用在大规模数据集上预训练的权重(如 Depth Anything v2)作为启动点。
- 堆栈注意力层(Stack Attention Layer):在空间的每个 Patch 位置,模型会沿着“图像堆栈”这一维度进行自注意力计算。这就像是模型在反复比对同一物体在不同焦距下的虚化程度:“这个像素在第 3 张图里最清楚,对应的焦距是 2 米,所以它的深度大约就是 2 米。”
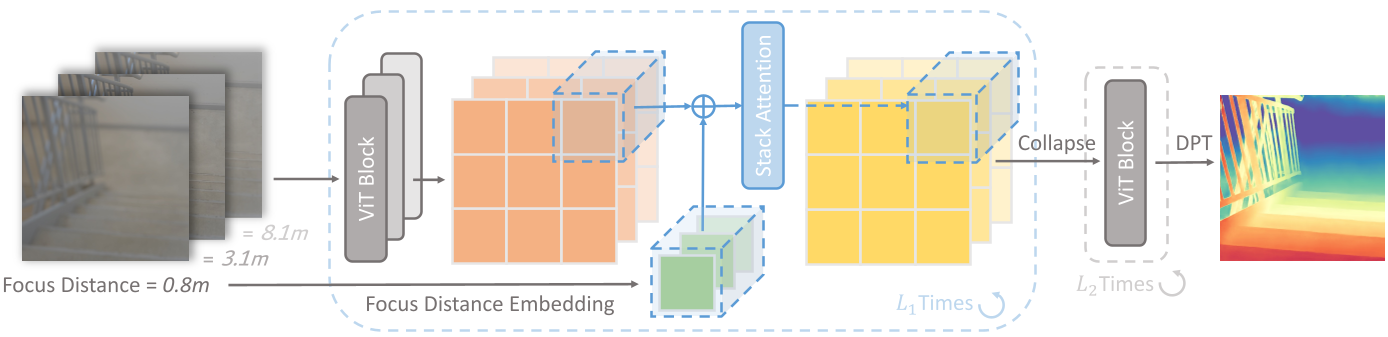 图 1:FOSSA 整体架构,注意其中间穿插的 Stack Attention 层。
图 1:FOSSA 整体架构,注意其中间穿插的 Stack Attention 层。
核心创新 2:ZEDD 真实基准测试集
为了验证模型的实战能力,团队推出了 ZEDD 分布式基准。相比于之前的 DDFF 数据集,ZEDD 的优势是压倒性的:
- 高分辨率:采用了 4K 级别的超清图像。
- 大孔径:支持 F/1.4 等极浅景深,使得失焦信号更加明显。
- 真 LiDAR 标注:使用高精度的 Ouster Lidar 进行点云累积,确保了 Ground Truth 的质量。
 图 2:ZEDD 焦堆栈输入及其对应的精确深度图。
图 2:ZEDD 焦堆栈输入及其对应的精确深度图。
实验结果:降维打击
FOSSA 的表现极其惊艳。在从未见过的 ZEDD 测试集上,即便是在 Zero-shot(未针对该数据集训练)的情况下,它的误差也远低于现有的单目和 DfD 模型。
 表 1:在 DDFF 数据集上的对比,FOSSA 的 MSE 指标几乎是前人工作的几分之一。
表 1:在 DDFF 数据集上的对比,FOSSA 的 MSE 指标几乎是前人工作的几分之一。
关键特性观察:
- 鲁棒性:即使只给模型 2 张图像(而非训练时的 5 张),甚至缩小孔径,FOSSA 依然能维持较高的精度(图 5)。
- 绝对深度:不同于单目模型的“相对深度”,FOSSA 输出的是真实的物理距离(米),这对于自动驾驶或机器人抓取至关重要。
总结与洞察
FOSSA 的成功证明了两点:
- 物理先验 + Transformer = 降维打击:利用 Stack Attention 显式建模光学失焦过程,效果远好于广合式的端到端黑盒。
- 数据合成的艺术:通过随机化 PSF(点扩散函数)形状,利用已有的 RGBD 大数据集“伪造”出的焦堆栈,足以训练出能应对复杂现实光学的通用模型。
尽管目前 FOSSA 仍局限于静态场景,但它为未来手机影像系统的“后对焦时代”以及机器人视觉避障开辟了一条清晰的技术路径。