本文提出了 Agent Factory,这是一种利用通用编程智能体(Claude 4.5/4.6)进行高层次综合(HLS)硬件优化的双阶段框架。该方法无需硬件领域特定训练,通过分解子核优化与全局决策缩放,在多个 HLS 基準测试中实现了平均 8.27 倍的加速。
TL;DR
硬件设计的自动化一直是个难题,尤其是 高层次综合 (HLS) 阶段。IBM 的研究者们最近通过一篇论文展示了:即便是没有接受过任何硬件训练的通用编程智能体(如 Claude 4.5/4.6),通过一种名为 Agent Factory 的协作机制,也能在 HLS 优化中跑出 20 倍以上的加速比,其表现直接看齐甚至超越了资深硬件工程师。
痛点与动机:为什么 HLS 自动化这么难?
HLS 的初衷是让开发者用 C/C++ 就能写硬件逻辑,但现实很骨感:
- 搜索空间爆炸:循环展开(Unroll)、流水线(Pipeline)、内存分区(Array Partition)的组合呈指数级增长。
- 非线性反馈:增加资源投入(如完全展开循环)有时反而会因为内存端口冲突导致性能下降,这种“反直觉”让传统算法极其头疼。
- 缺乏全局观:现有的自动化 DSE (Design Space Exploration) 工具大多只能在给定的参数池里“抽奖”,却不会像人类工程师那样“重写代码”。
核心架构:双阶段代理工厂 (Agent Factory)
作者提出了一种巧妙的“分解-聚合-进化”策略,解决了复杂设计的扩展性问题。
第一阶段:微观探索与 ILP 约束
- 并行子核优化:协调代理将复杂的 Top 函数分解,为每个子函数分发一个独立的优化代理。
- 结构化策略:这些代理会尝试保守型、流水线型、激进型等 7 种不同的变体。
- ILP 全局筛选:利用 整数线性规划 (ILP),在给定的面积(Area)约束下,挑选出能够实现全局性能最优的子核组合方案。
第二阶段:宏观重构与推理缩放 (Scaling)
这是本文最精彩的地方。系统会启动 $N$ 个专家代理(Expert Agents),它们不再盯着单个函数,而是站在全局视角(System-level)进行“跨函数手术”:
- Pragma 重新组合:联调跨模块的流水线深度。
- 内存重组:打破函数边界的数组分区。
- 代码级变换:执行循环融合(Loop Fusion)或代数简化。
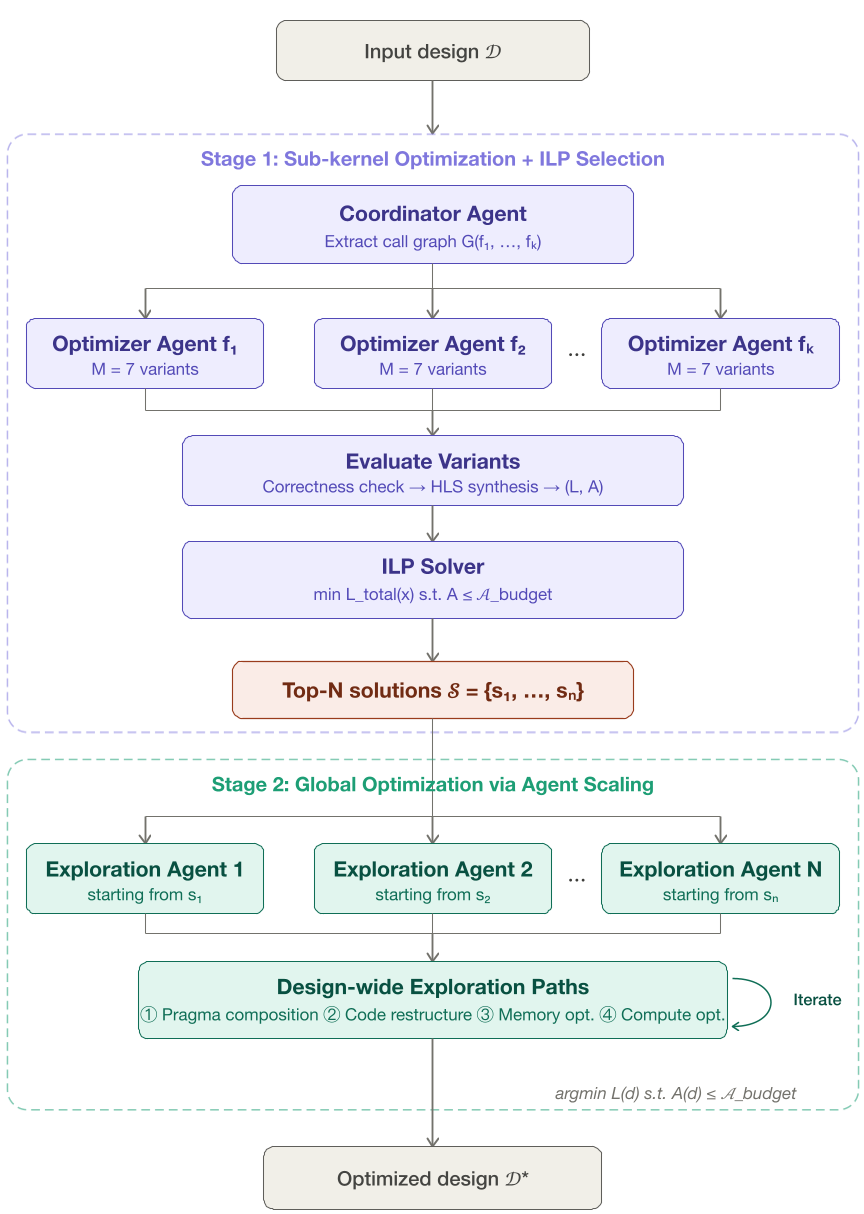 图 1:Agent Factory 的双阶段工作流:从子核分解到全设计全局精炼。
图 1:Agent Factory 的双阶段工作流:从子核分解到全设计全局精炼。
实验发现:Scaling Is All You Need?
研究团队在 Vitis HLS 环境下测试了 12 个经典内核。
性能飞跃
随着代理数量(N)的增加,设计的帕累托前沿(Pareto Front)不断向左上方移动(即相同面积下延迟更低)。
- 典型案例:
streamcluster内核在 10 个代理的加持下实现了惊人的 20x+ 高速化。 - 发现直觉:AI 代理在没有任何预设的情况下,通过 Synthesis-in-the-loop 的反馈,自主“学会”了
ARRAY_PARTITION是解决内存瓶颈的神器。
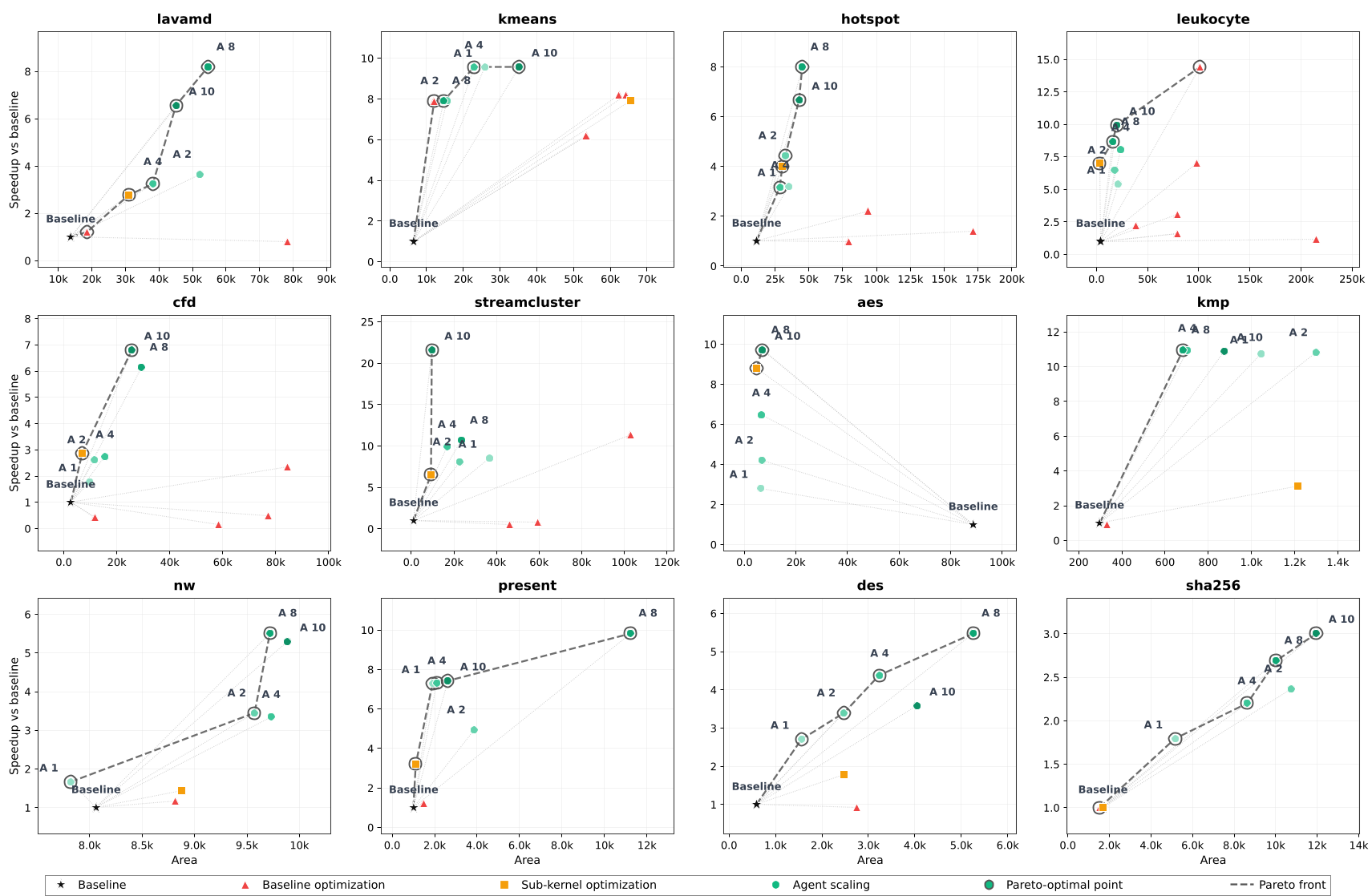 图 2:随代理数量(N)增加,各 Benchmark 的加速性能呈现明显的扩展效应。
图 2:随代理数量(N)增加,各 Benchmark 的加速性能呈现明显的扩展效应。
跨领域验证:从 FPGA 到 ASIC
研究不仅限于 FPGA。通过对比 HLS 面积报告与逻辑综合工具 ABC 的结果,作者发现这种基于代理的面积预测在 ASIC 流程中同样具有极高的相关性(如 SHA256 相关系数达 0.992),证明了该方法的通用价值。
深度洞察
- 超越局部最优:最好的最终设计往往并不源于第一阶段 ILP 排名第一的方案。这说明跨函数的“化学反应”是独立子核优化无法触及的盲区,代理的全局重构能力至关重要。
- 成本代价:这种优化并非免费。实验显示的 Token 消耗平均在 7.67M 左右,这意味着我们实际上是用“推理时计算量”换取了“硬件性能”。
- 局限性:对于极其简单的内核,代理数量增加会带来边际效应递减。此外,在极度紧凑的面积预算下,AI 可能会陷入过度优化的死胡同。
总结
IBM 的这项研究为我们展示了 Agentic AI 在硬核技术领域的巨大潜力。它不再仅仅是写个 Python 脚本,而是能够像一个经验丰富的硬件架构师一样,在复杂的约束下进行权衡与重构。随着 LLM 推理能力的进一步演进,全自动“无人值守”的硬件加速器设计可能离我们不远了。