本文提出了 AgenticRec,这是一个面向排序的任务型推荐智能体框架。它通过集成推荐专用工具集、列表级策略梯度优化(list-wise GRPO)和渐进式偏好精炼(PPR),实现了端到端的推理、工具调用与排序优化,显著提升了在 SOTA 基准上的推荐准确度。
TL;DR
传统的推荐 LLM 大多是“一锤子买卖”:输入历史,输出列表。而 AgenticRec 彻底改变了这一范式。它将推荐过程重构为一个端到端优化的专家决策链:模型在给出排序前,会根据需要主动调用“用户画像”、“行为统计”、“协同过滤”等工具,并利用类似 DeepSeek-V3 的 GRPO 算法进行列表级强化学习。
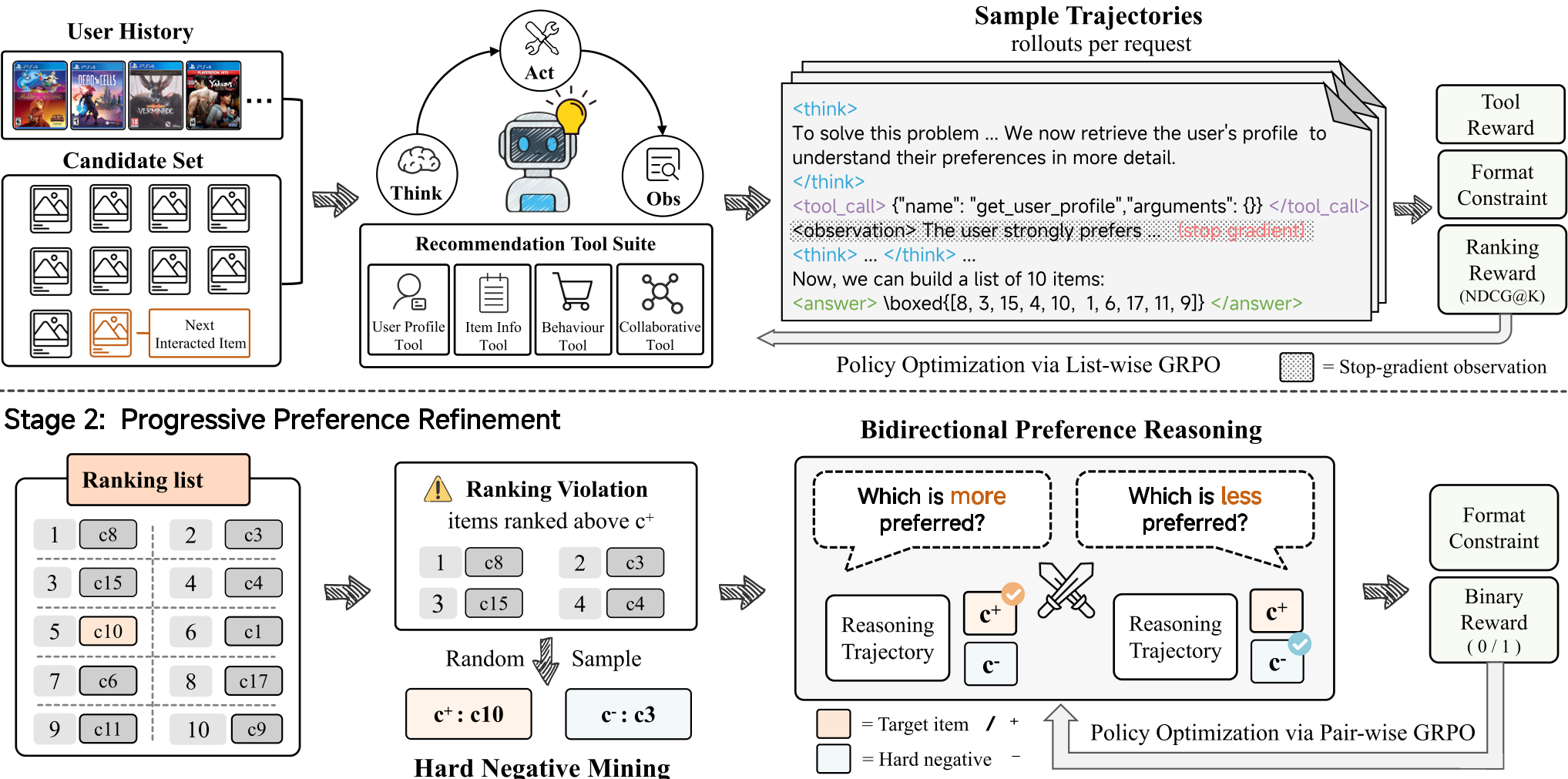 图 1: AgenticRec 与传统训练/非训练智能体的对比。AgenticRec 实现了从推理到排序反馈的全闭环。
图 1: AgenticRec 与传统训练/非训练智能体的对比。AgenticRec 实现了从推理到排序反馈的全闭环。
1. 痛点:为什么 LLM 推理在推荐中常常“掉链子”?
目前 LLM 推荐面临两个瓶颈:
- 脱离本质的“空转”推理:很多模型虽然有推理过程,但那是基于通用语料的“文学创作”,并未与真实的协同过滤信号连接。工具调用(Tool Use)往往是静态的、启发式的,没能真正为排序目标服务。
- 模糊的偏好边界:在 20 个候选项中选出 Top-1 很简单,但在 3 个都很像的项中排出先后很难。隐式反馈(点击/购买)过于稀疏,无法提供足够的细粒度监督。
2. 核心技术:如何炼就“懂行”的智能体?
2.1 列表级策略优化 (List-Wise GRPO)
AgenticRec 并没有采用标准的 PPO,而是借鉴了 GRPO (Group Relative Policy Optimization)。其精妙之处在于:
- 无偏性与低方差:通过同一 Context 下采样多个轨迹(Group),利用组内相对得分作为 Advantage,显著缓解了排序任务中奖励极其稀疏的问题。
- 全路径覆盖:
Think -> Act -> Obs -> Rank。整个决策路径的 Log-likelihood 都会根据最终的 NDCG 得分进行更新。这意味着,模型如果因为调用了错误的工具导致排序下降,其工具调用策略会直接受到惩罚。
2.2 渐进式偏好精炼 (PPR)
为了解决“细粒度歧义”,作者设计了一套“自找麻烦”的机制:
- 困难负样本挖掘:从模型自己生成的错误排序中,找出那些排在正样本之前的“伪王者”。
- 双向偏好推理:
- 正向:为什么用户喜欢 A?
- 负向:为什么用户这次不喜欢 B(虽然 B 和 A 很像)? 这种“推拉结合”的策略,从数学上被证明能更有效地收紧成对排序误差的凸上界 (Convex Upper Bound)。
3. 实验战绩:全线 SOTA
在 Amazon 多个数据集上的对比实验显示,AgenticRec 不仅吊打了传统的 SASRec 等序列模型,也大幅领先于 LLaRA 等基于微调的 LLM 推荐模型。
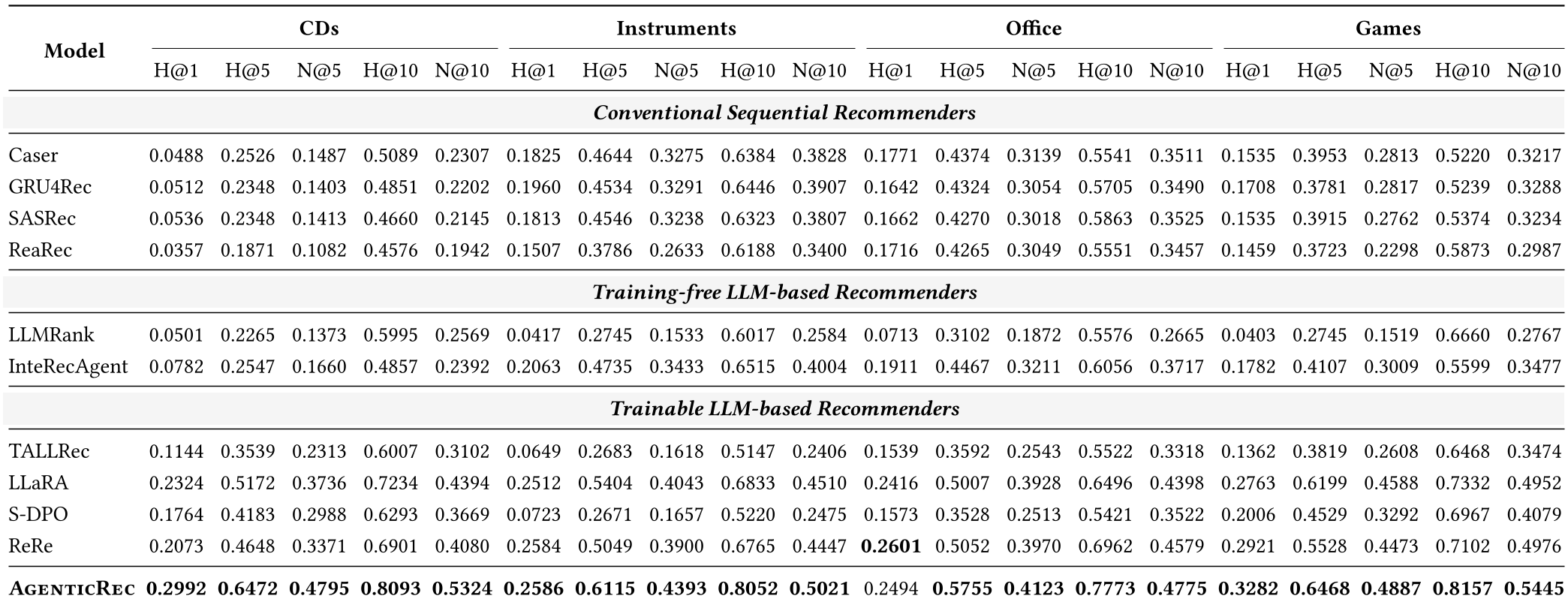 表 1: AgenticRec 在各项指标上均打破了基准记录。
表 1: AgenticRec 在各项指标上均打破了基准记录。
关键发现:
- 工具不是越多越好:在未训练(Frozen)状态下,乱用工具甚至会导致性能下降。但经过 Agentic 训练后,工具调用与性能提升表现出强正相关(见下图)。
- 规模效应:随着 Backbone 从 1.7B 扩展到 8B,模型利用工具进行逻辑推理的能力呈现线性增长。
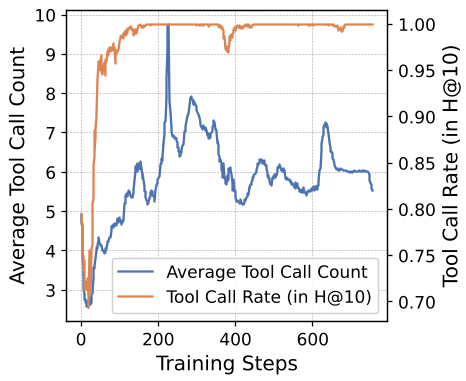 图 2: (a) 随着训练进行,有效工具调用占比显著提升;(b) H@10 稳步增长。
图 2: (a) 随着训练进行,有效工具调用占比显著提升;(b) H@10 稳步增长。
4. 深度洞察:推荐系统的未来是“决策引擎”
AgenticRec 的成功提供了一个重要启示:推荐不等于预测。 真正的推荐是:
- 主动探索:发现信息不足(如用户买了 GameCube 配件),主动去查新款 Switch 游戏(协同过滤)。
- 逻辑闭环:不仅要通过文本理解意图,还要通过分布式 ID 和行为统计校验直觉。
- 错误学习:通过分析排序违规,实现自我进化。
局限性:多步推理和工具调用不可避免地带来了更高的推理延迟(TTL)。在超高并发的工业级实时场景中,如何平衡“思考深度”与“响应速度”将是下一步演进的关键。
作者总结:AgenticRec 证明了,只要给予正确的反馈(List-wise Reward)和合适的工具,LLM 有潜力成为比人类专家更细腻的“私人购物顾问”。