ARC-AGI-3 是由 ARC Prize Foundation 推出的第三代通用人工智能评测基准,从静态规则推理转向“智能体化(Agentic)”交互任务。该基准通过 135 个新颖、抽象的轮次制环境,要求 AI 在无指令条件下完成探索、目标推断、环境建模与路径规划,目前的顶尖 AI 模型(如 GPT-5.4, Gemini 3.1)得分均低于 1%,而人类通过率为 100%。
TL;DR
ARC Prize Foundation 正式发布了 ARC-AGI-3,这是目前全球唯一未被刷榜、面向智能体(Agentic)推理的 AGI 评测基准。与前作不同,ARC-AGI-3 将 AI 扔进了一个完全陌生的交互式 2D 环境中,不给任何指令,要求模型像人类一样边玩边学。结果令人震惊:在人类 100% 胜出的环境下,当前最强的 GPT-5.4 和 Gemini 3.1 的得分竟然不足 1%。
核心定位:从“静态推理”到“智能体效率”
过去几年,我们见证了 LLM 依靠“规模定律(Scaling Laws)”和“推理侧扩展(o1 系列)”在代码和数学上大放异彩。然而,ARC-AGI-3 的创作者 François Chollet 指出,这可能只是一种更高级的记忆与模式匹配。
ARC-AGI-3 认为,通用人工智能(AGI)的本质是“获取新技能的效率”。
- 不仅仅是结果:能解决问题不代表智能,用最少的动作、最快的速度解决从未见过的问题才是智能。
- 四大支柱:ARC-AGI-3 考察的是智能体的探索(Exploration)、建模(Modeling)、目标设定(Goal-Setting)以及规划与执行(Planning & Execution)。
痛点深挖:旧基准的“崩塌”与新挑战
虽然 ARC-AGI-1 和 2 成功抵御了早期的预训练缩放,但随着 2024-2025 年 LRM(大推理模型)的崛起,研究者发现通过合成海量类似任务进行“测试时训练(Test-time Training)”,AI 正在通过高维快捷方式“模拟”推理。
ARC-AGI-3 的动机在于:如果任务是静态的,AI 总能通过暴力搜索或过拟合来破解。 因此,ARC-AGI-3 引入了交互性。智能体必须在没有任何 Prompt 解释规则的情况下,通过动作反馈(Action-Feedback)来推断系统的“物理定律”和“获胜条件”。
方法论详解:如何科学地衡量“效率”?
1. 核心知识先验 (Core Knowledge Priors)
为了排除文化背景和语言的影响,所有任务仅基于:
- 物体性 (Objectness):物体是持久存在的。
- 基础几何 (Geometry):对称、旋转、拓扑关系。
- 基础物理 (Physics):重力、碰撞、反弹。
- 代理性 (Agentness):理解某些物体具有意图。
2. 模型架构与交互空间
环境基于 64x64 的格子,智能体通过有限的动作空间(移动、选择、撤销)与环境交互。
 图 1: 一个典型的 ARC-AGI-3 交互环境(ID: ls20),AI 需要在没有指令的情况下发现生存规律。
图 1: 一个典型的 ARC-AGI-3 交互环境(ID: ls20),AI 需要在没有指令的情况下发现生存规律。
3. RHAE 评分机制:向人类对齐
ARC-AGI-3 引入了 RHAE (Relative Human Action Efficiency) 指标。 其公式定义为: 这里 是人类表现的基准(第二名), 是 AI 的动作数。平方项大大加剧了对“低效方案”的惩罚——如果 AI 用的动作比人类多 10 倍,得分将降至 1%。
实验与结果:AI 的“断崖式”落后
通过对 486 名人类参与者和多家顶级厂商模型的对比,测试结果非常惨烈。
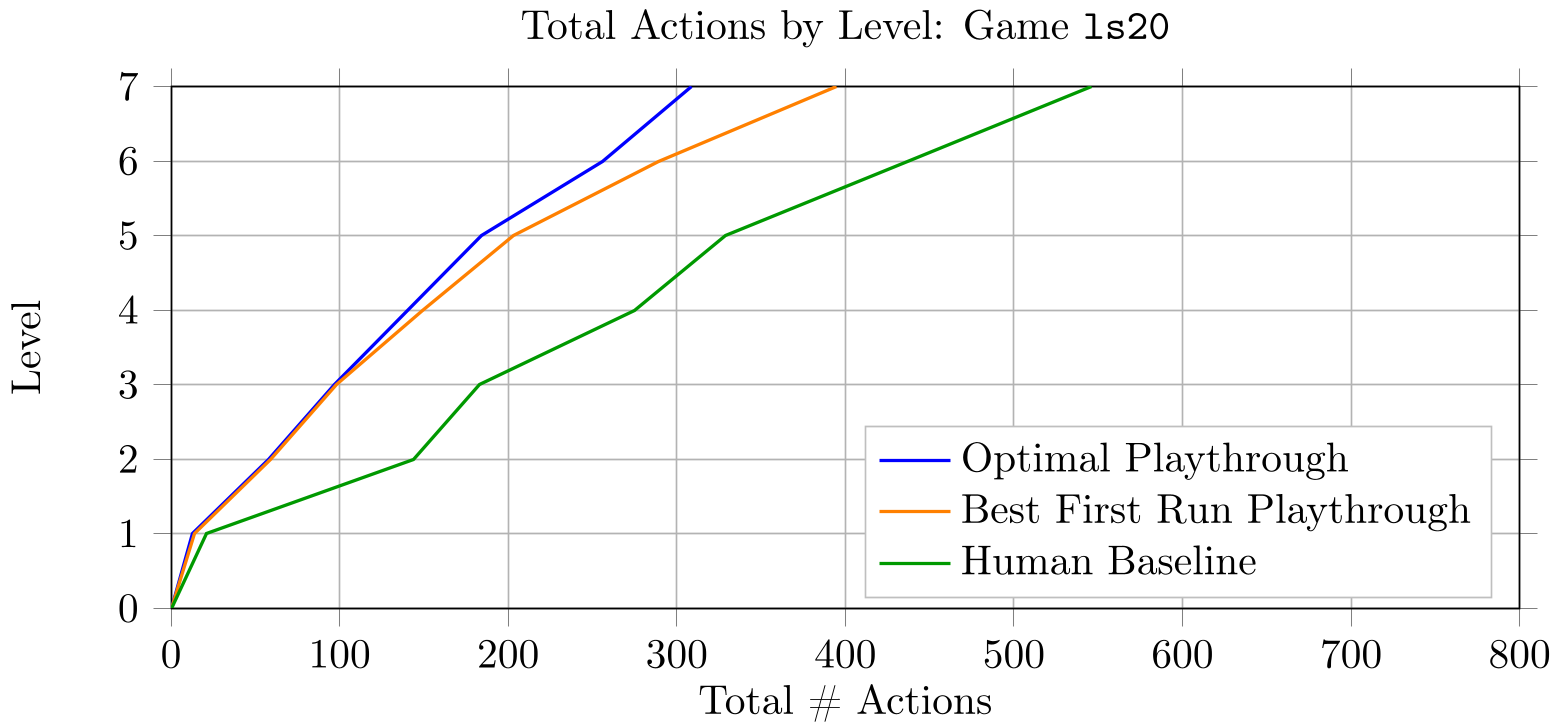 图 2: 在 ls20 关卡中,人类只需极少量的探索动作即可掌握规律。
图 2: 在 ls20 关卡中,人类只需极少量的探索动作即可掌握规律。
| 供应商 | 模型 | 得分 (Score) | | :--- | :--- | :--- | | Google | Gemini 3.1 Pro Preview | 0.37% | | OpenAI | GPT 5.4 (High) | 0.26% | | Anthropic | Opus 4.6 (Max) | 0.25% | | xAI | Grok-4.20 | 0.00% |
深度见解:
- Context 限制:LLM 在处理长序列交互时,Context 预算会迅速耗尽。
- 缺乏假设修正:模型一旦陷入错误的“环境模型”,很难通过少量的交互反馈进行高效的自我修正。
- 无法处理“未知的未知”:AI 目前极度依赖 System Prompt 和已知工具(Tools),但在 ARC-AGI-3 这种没有任何说明书的任务面前,表现得像是在黑暗中乱撞。
深度洞察与总结
ARC-AGI-3 的推出宣告了“刷题式 AI”时代的终结。
- 智能不是存量,而是增量:真正的智能体应该能在几分钟内适应一个完全陌生的游戏规则,而不是在万亿级的数据集里寻找相似的模式。
- Harness 的局限性:论文发现,针对特定环境手工设计的“外挂”(Harness)虽然能提分,但在面对真正的私有测试集时会立刻失效。这说明 AI 本身的流体智力(Fluid Intelligence)并未提升。
局限性:ARC-AGI-3 极其强调效率,这可能导致一些虽然能解决问题但动作稍慢的优秀算法被严重低估。
展望:2026 年的 ARC Prize 奖金池已提升至 200 万美元。如果 AI 能够征服 ARC-AGI-3,那将意味着我们真正掌握了让机器像人类一样学习和进化的秘诀。