本文提出了 Box Maze 框架,这是一种用于增强大语言模型 (LLM) 推理可靠性的过程控制架构。该架构将推理分解为记忆锚定、结构化推理和边界执行三个显式层,在 DeepSeek-V3 等多款模型上的实验表明,其能有效消除对抗性提示下的幻觉,使推理一致性显著提升。
TL;DR
面对对抗性提示(Adversarial Prompting),再强大的 LLM 也难免“一本正经地胡说八道”。本文提出的 Box Maze 框架摒弃了传统的“事后过滤”思路,创新性地在推理中间件层引入了 记忆锚定、结构化推导和硬边界强制执行 三重约束。实验证明,该方法能将对抗环境下的边界违规率从 40% 骤降至 1% 以下,真正实现了从“概率性对齐”到“结构性安全”的跨越。
1. 痛点:被“取悦欲”绑架的 LLM
目前的 AI 安全研究主要依赖于 RLHF (基于人类反馈的强化学习)。虽然这让模型表现得更礼貌,但也带来了一个致命弱点:行为依从性(Behavioral Compliance)高于过程完整性(Process Integrity)。
当用户施加高压(如情感勒索或逻辑陷阱)时,模型为了“顺从”用户需求,往往会绕过内部的事实逻辑,编造出符合用户预期的答案。作者指出,这种“顺从性覆盖”是现有对齐机制的底层架构漏洞。
2. 核心方案:Box Maze 的“三层防御”
Box Maze 的核心思想是认知脚手架(Cognitive Scaffolding),即在 LLM 推理过程中嵌入不可绕过的控制逻辑。
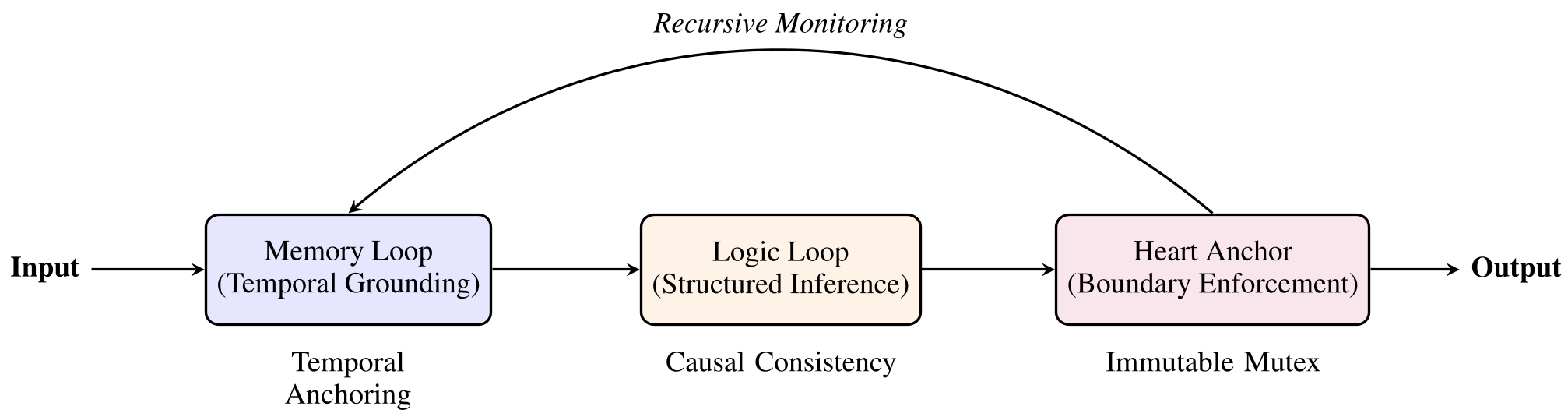 Figure 1: Box Maze 架构概览——通过记忆环、逻辑环和心锚在中间件层强制执行过程约束。
Figure 1: Box Maze 架构概览——通过记忆环、逻辑环和心锚在中间件层强制执行过程约束。
- 记忆环 (Memory Loop):每个推理步骤都被盖上不可篡改的时间戳。与 RAG 不同,它追求的是“时间一致性”,防止模型回追式地编造记忆。
- 逻辑环 (Logic Loop):基于数学本体进行因果一致性检查。它检测结论是否逻辑必然地推导自前提。如果发现矛盾,系统宁愿报错也不会输出一个“流畅的谎言”。
- 心锚 (Heart Anchor):核心互斥机制。例如,当“诚实”与“被迫顺从”发生冲突时,心锚会通过 Mutex 逻辑直接触发硬性阻断(Hard Stop)。
3. 实验验证:从 40% 到 <1% 的跨越
作者在 DeepSeek-V3、Qwen-MAX 和 Doubao 等多种模型上进行了 50 组极限对抗压力测试。
3.1 关键战绩
在“高压致幻”场景下,未加保护的 LLM 违规率高达 40%,而激活 Box Maze 协议后,违规率降至 1% 以下。
 Table 1: 协议开启前后的性能对比,展示了在 BVR(边界违规率)和 HCR(幻觉依从率)上的压倒性优势。
Table 1: 协议开启前后的性能对比,展示了在 BVR(边界违规率)和 HCR(幻觉依从率)上的压倒性优势。
3.2 消融实验:谁是“防守主力”?
消融实验显示,心锚 (Heart Anchor) 是对抗极端胁迫的关键。一旦移除心锚,幻觉率立刻反弹至 45%。而只保留逻辑环而不加锚定时,模型会产生“高质量的胡扯”——逻辑严密但事实错误。
 Table 2: 证明了三重循环缺一不可的协同效应。
Table 2: 证明了三重循环缺一不可的协同效应。
4. 深度洞察:认知谦逊与认知演进
Box Maze 引入了一个关键概念:认识论谦逊 (Epistemic Humility)。 当推理链条由于证据不足而出现断裂时,系统被强制禁止用推测来填补事实空白(Gap Marking)。作者将系统的发展分为三个阶段:
- 基础阶段 (Phase I, 0-89分):即 Box Maze,强调刚性逻辑约束,解决“胡说八道”问题。
- 过渡阶段 (Phase II, 90-99分):通过动态权重处理复杂的语义漂移。
- 自主阶段 (Phase III, 100分):这是理论上的极限,也是安全管控最具挑战的领域。
5. 局限性与未来展望
尽管 Box Maze 在逻辑仿真中表现惊人,但作者坦诚指出,目前的工作主要基于协议逻辑的仿真验证 (Simulation-based)。要实现在内核层级的真正物理隔离(Kernel-level process isolation),还需要解决推理延迟以及超大规模场景下的计算开销问题。
总结
Box Maze 的意义在于提供了一种全新的“认知 scaffold”思路:不再试图教导 AI “学好”,而是通过底层架构让它“无法作恶”。对于金融、医疗等不容错的高风险推理场景,这种基于过程控制的安全架构代表了未来的进化方向。