本文提出了 STOP (Super TOken for Pruning),这是首个利用可学习内部信号进行路径剪枝的框架,旨在解决大语言模型(LRM)并行推理中的高昂计算成本。该方法在 1.5B 到 20B 参数的模型上实现了 SOTA 性能,在 AIME25 等推理任务中显著提升了准确率。
TL;DR
在并行推理(Parallel Reasoning)成为大模型标配的今天,计算成本已成沉重负担。本文提出的 STOP (Super TOken for Pruning) 开启了“Type IV”剪枝范式:通过在模型内部植入可学习的“超级 Token”直接感知推理路径的成败。实验显示,它能在降低 70% 以上 Token 消耗的同时,显著将 AIME 数学竞赛的性能推向新高。
背景定位:并行推理的“资源黑洞”
当前的大型推理模型(LRM)如 DeepSeek-R1 或 OpenAI o1,通常采用采样多个独立路径并取共识(Self-Consistency)的策略。但这带来了一个致命痛点:一旦推理路径在早期出错,后续的生成全是浪费。目前的方案要么靠外部判别器(太慢、太贵),要么靠 Prob/Perplexity(太笨、不准)。
作者将路径剪枝方法统一划分为四个象限,并指出最理想的 Type IV(可学习且利用内部信号) 此前竟然一直是研究空白。
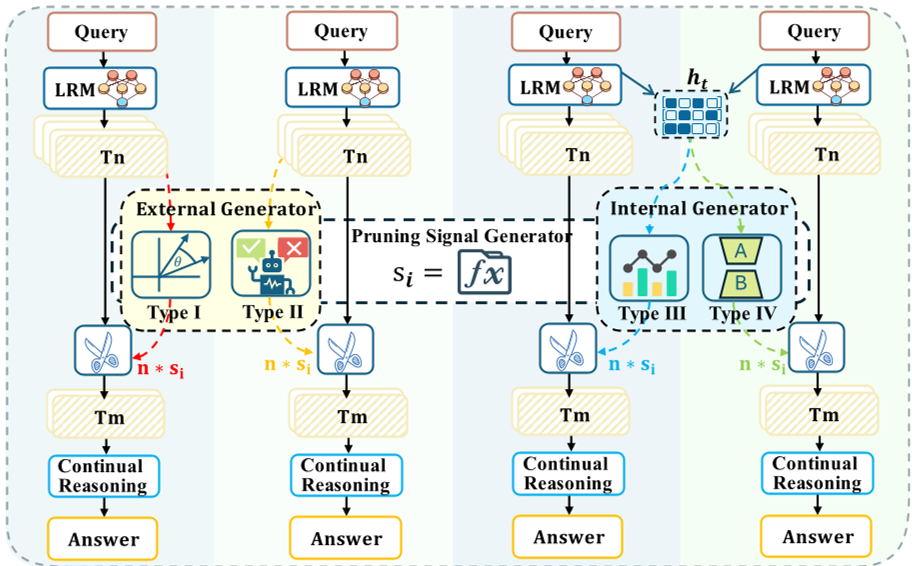
核心动机:模型其实“心里有数”
为什么外部判别器(External Judge)不如内部信号? 因为生成的文本是离散且低维的投影,会丢失大量的模型不确定性。相反,模型的 Hidden States(隐藏状态) 包含了丰富的逻辑一致性和置信度信息。作者的 Insight 是:让模型自己告诉我们,这条路走不走的通。
方法论:STOP 架构深度解析
STOP 的设计极其简洁且非侵入式:
- [STOP] Token:在词表中新增一个特殊 Token,充当聚合信息的“传感器”。
- Critique Adapter (LoRA):仅在处理 [STOP] token 时激活,用于提取错误相关的特征,而不干扰模型本身的生成能力。
- Classification Head:将 [STOP] 的输出映射为一个 0-1 的概率分值。
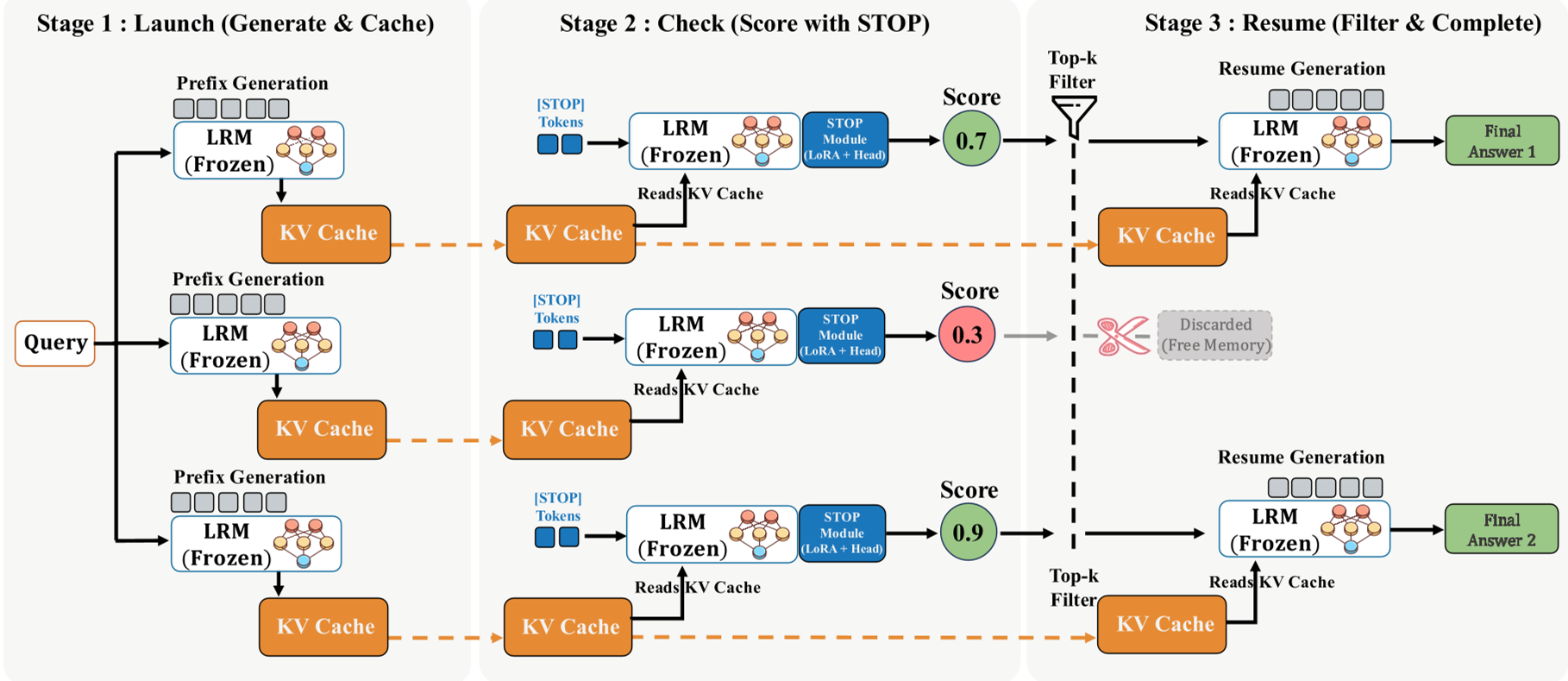
三阶段工作流:Launch-Check-Resume
- Launch:并行生成 N 条路径的初始前缀,并缓存 KV Cache。
- Check:在缓存后追加 [STOP] token,瞬间计算出每条路径的“潜力分”。
- Resume:只让 Top-k 的潜力路经继续“跑完全程”,丢弃其余废柴路径。
实验与战绩:效率与精度的双重飞跃
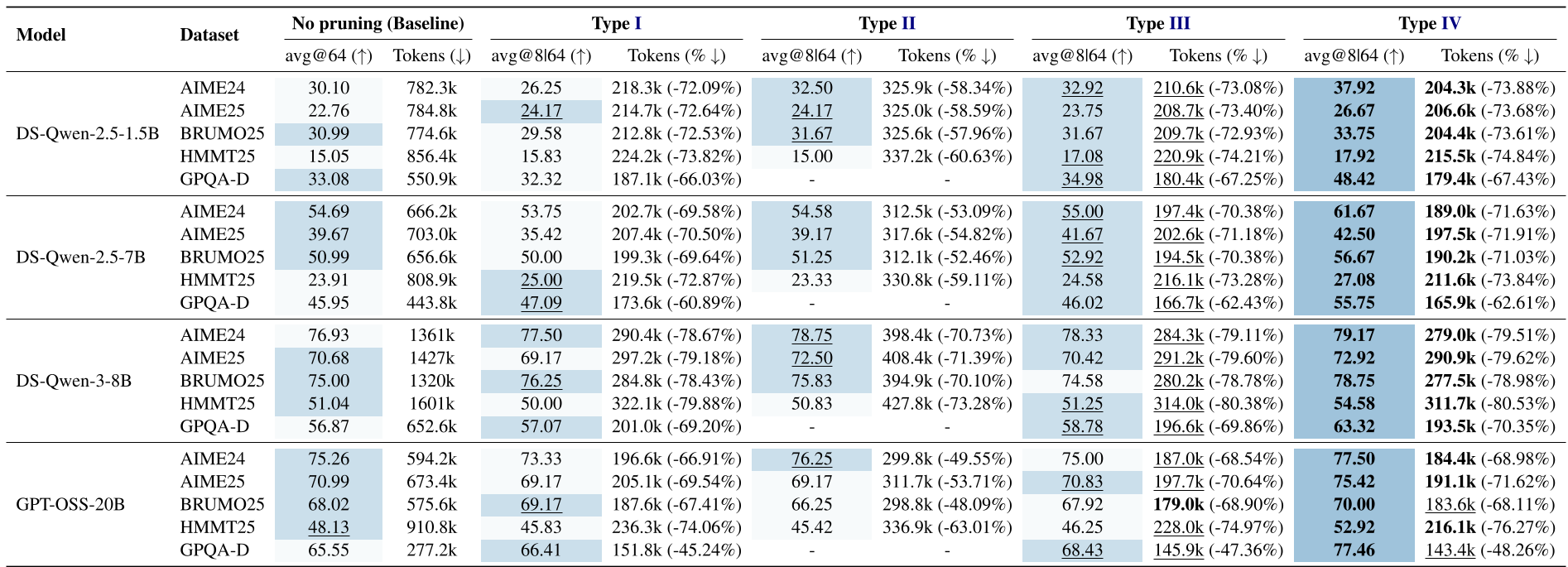
在多达 1.5B 到 20B 参数的跨度实验中,STOP 表现出惊人的 Scalability:
- 性能提升:在 AIME2024 任务上,1.5B 模型通过 STOP 剪枝后的准确率(37.92%)竟然超过了未剪枝基线(30.1%)。这意味着剪枝不仅省钱,还起到了“提纯”候选集的作用。
- 超低开销:相比于外部判别器 3.37% 的执行延迟,STOP 的延迟仅为 0.59%,几乎可以忽略不计。
深度洞察:STOP 到底在看什么?
通过对 [STOP] Token 的 Attention Map 进行可视化,作者发现了一个有趣的现象:
- 高分路径:模型会将注意力集中在“cognitive pivots”(逻辑转折点),如 "don’t" 或 "but",这说明它在审视逻辑推导的严密性。
- 低分路径:模型往往表现出“Premature Closure”(过早收敛),注意力直接跳到了最终选项,暴露出路径由于缺乏逻辑支撑而在“盲猜”。

总结与展望
STOP 证明了在模型推理早期进行“熔断”不仅是可能的,而且是非常高效的。它建立了一套 Scaling Law 指南,告诉开发者在不同的计算预算(Compute Budget)下该如何选择保留路径比例 。
局限性:目前实验主要集中在固定位置剪枝,未来若能实现“动态采样位置”剪枝,效率可能还会进一步突破。此项技术对 RLHF 训练过程中的采样效率提升也具有巨大的潜在价值。
主编点评: 这篇论文最牛的地方在于它把“模型感知”从单纯的文本生成中剥离出来,用极小的 Token 成本换取了全局的计算效率。在 o1 类大模型普及的今天,这种“省钱就是赚钱”的优化是工程落地的关键。