本文通过“表示层次结构”视角揭示了网络剪枝(Pruning)在生成式与非生成式任务中表现不一致的根本原因。研究提出了包含嵌入空间、Logit 空间和概率空间的分析框架,证明了 Softmax 非线性变换和自回归错误累积是导致生成式任务性能崩溃的关键。
TL;DR
模型剪枝(Network Pruning)一直被视为 LLM 瘦身的良药。然而,本文通过严谨的数学推导和实验证明了一个扎心的事实:剪枝后的模型在非生成式任务(如检索、多选)上表现稳如泰山,但在生成式任务(如数学推理、续写)上却极易崩溃。作者通过引入“表示层次结构”视角,定位了罪魁祸首——Softmax 非线性变换。
背景定位:剪枝界的“任务不平等”
在学术界,大家通常习惯用 MMLU 或测相似度来评估剪枝效果。但作者发现,这种评估是不全面的。剪枝在保持语义特征(Embedding)方面做得很好,但在处理需要连续采样、迭代生成的路径时,模型内部的微小偏差会被无限放大。
痛点深挖:为何生成式任务是剪枝的“坟墓”?
传统的剪枝研究往往认为性能下降是由于参数量减少导致的容量损失。但本文指出,问题的内核在于扰动传播(Perturbation Propagation)。
- 表示维度差异:非生成式任务通常只关注少数几个候选 Token 的 Logits。
- 非线性放大:Softmax 将线性空间的微小偏差转化为概率空间的巨大漂移。
- 错误累积:自回归生成过程中,前一步的微小误差会通过 KV Cache 传递给下一步,造成雪崩效应。
核心方法:表示层次分析 (Representation Hierarchies)
作者将推理过程拆解为三个空间,并通过二阶泰勒展开分析了剪枝引入的扰动 如何演变:
- Embedding Space ():剪枝后的隐层表示保持了极高的余弦相似度。
- Logit Space ():经过 LM Head(线性投影)后,偏差不仅没变大,反而因为线性变换的特性被进一步平滑。
- Probability Space ():经过 Softmax 后,灾难发生了。
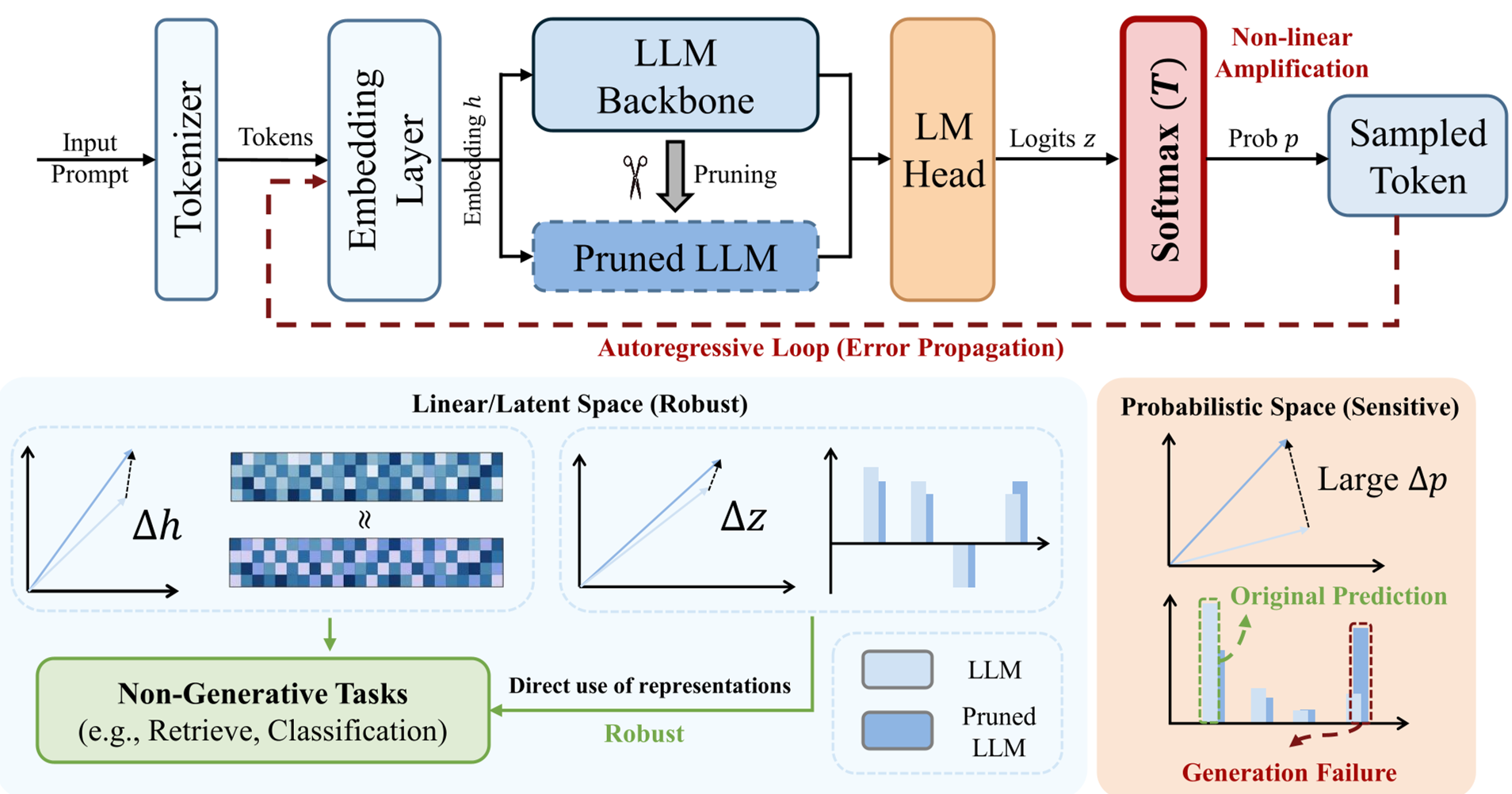 图 1:剪枝扰动在 LLM 不同表示空间中的传播。可以看到 Softmax 后的 显著增大。
图 1:剪枝扰动在 LLM 不同表示空间中的传播。可以看到 Softmax 后的 显著增大。
数学直觉:Softmax 敏感度定理
作者推导出了核心公式(Theorem 2): 这意味着概率空间的偏差高度依赖于 Logit 扰动 的方差 和 温度 。当温度较低或 Logit 方差较大时,概率分布会发生剧变。
实验战绩:任务间的冰火两重天
在 Mistral-7B 和 Qwen-2.5 上的实验支撑了这一理论:
- 非生成式稳健性:即便删除 8 个层,MMLU 平均分几乎不动。
- 生成式溃败:同样的模型,在 GSM8K 数学推理任务上直接从 48.4 跌至 0。
 表 1:Mistral 模型在不同任务下的剪枝表现。注意非生成式与生成式任务的巨大分歧。
表 1:Mistral 模型在不同任务下的剪枝表现。注意非生成式与生成式任务的巨大分歧。
深度洞察:任务相关子空间 (Task-Relevant Subspace)
为什么多选题没事?因为多选题只关心 A/B/C/D 这几个 Token 的相对顺序(Argmax)。作者发现,虽然全表概率分布乱了,但落在特定选项子空间内的概率相对顺序依然稳健。这就是剪枝在非生成场景下依然“好使”的秘诀。
深度分析与启发:我们该如何剪枝?
- 空间敏感性:如果你的产品是做向量搜索(Embedding 驱动),尽管放心剪枝。
- 自回归死结:对于需要长文本生成的 ChatBot,单纯的训练后剪枝(Training-free Pruning)极度危险。
- 未来方向:研究如何通过少量微调(Post-training)来平抑 Softmax 后的方差偏移,将是高压缩比 LLM 走入手机端的关键。
结语
这篇文章打破了“剪枝通用性”的幻象,用优美的数学证明了:剪枝不仅仅是参数量的减法,更是概率分布的重塑。 只有理解了模型内部的表示层次,我们才能在效率与智能之间找到那个精准的平衡点。