DMax introduces a novel paradigm for Diffusion Language Models (dLLMs) designed to enable aggressive parallel decoding by mitigating error accumulation. Built upon the LLaDA-2.0-mini architecture, it achieves a significant speedup (e.g., 2.7x increase in TPF on GSM8K) while maintaining state-of-the-art generation quality.
Executive Summary
TL;DR: The dominance of Autoregressive LLMs (AR-LLMs) is primarily challenged by their sequential nature. Diffusion Language Models (dLLMs) promised parallel decoding, but "error accumulation" has historically crippled their accuracy at high speeds. DMax shatters this trade-off. By transforming the decoding process from a binary "Mask-to-Token" jump into a "Soft Self-Revision" flow in the embedding space, DMax achieves over 1,300 Tokens Per Second (TPS) while preserving 99% of the base model's reasoning accuracy.
Background: DMax is a SOTA enhancement for masked diffusion models like LLaDA. It moves the field from "stable but slow" or "fast but broken" toward a robust, highly parallel inference regime.
The "One-Way" Trap: Why Prior dLLMs Fail at Speed
The fundamental problem in current Masked Diffusion Language Models (MDLMs) is Error Accumulation.
- Binary Commitment: Conventional models treat decoding as a one-way street. Once a
[MASK]is converted to aToken, that token is fixed. - Context Contamination: If the model makes a mistake in an early parallel step, that mistake becomes "ground truth" context for the next step.
- Semantic Collapse: Under aggressive parallelism (decoding many tokens at once), errors cascade until the output becomes gibberish.
Methodology: The DMax Solution
DMax introduces two synergistic components to replace the "one-way" bottleneck with an iterative "self-correction" loop.
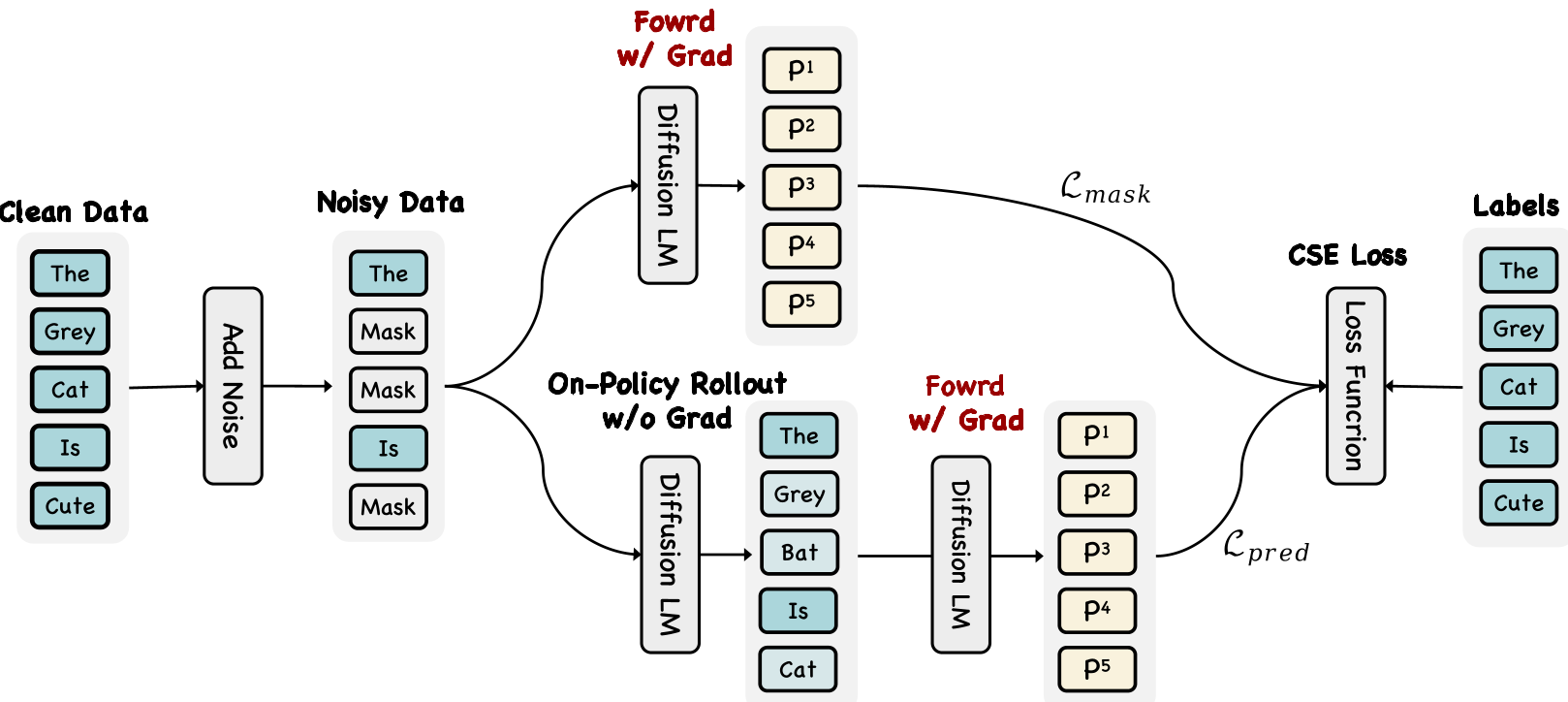
1. On-Policy Uniform Training (OPUT)
Standard Uniform Diffusion (UDLM) training uses random tokens from the vocabulary as noise. DMax identifies a "Train-Inference Mismatch" here: in real decoding, the "noise" isn't random—it's the model's own plausible but slightly wrong predictions.
- The Insight: Train the model on its own "hallucinations." By feeding the model's own top-k predictions back as training input, the model learns the specific geometry of its own errors and how to fix them.
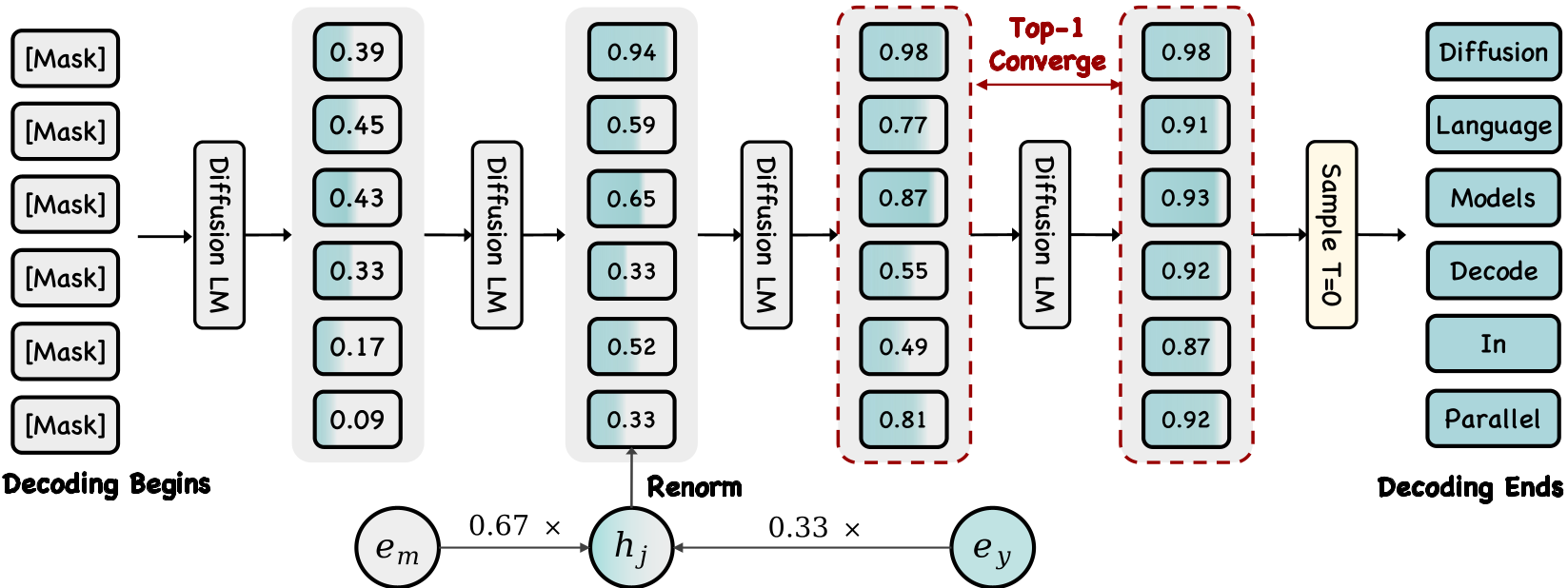
2. Soft Parallel Decoding (SPD)
Instead of forcing a hard choice between [MASK] and Token, SPD operates in the Embedding Space.
- Hybrid Embeddings: An intermediate token is represented as:
- Uncertainty Propagation: High-confidence predictions look like tokens; low-confidence ones stay "mask-like." This allows the model to "hedge its bets" and revise tokens in subsequent passes without being locked into a wrong discrete choice.
Experiments: Performance without Compromise
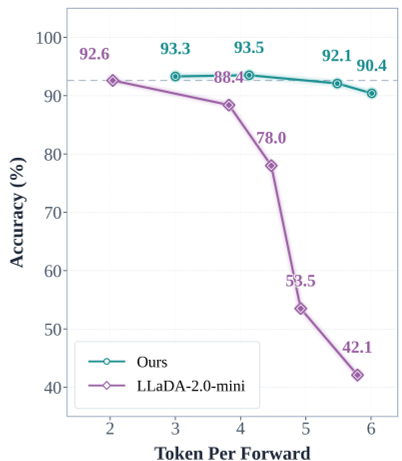
The results are striking. Across math (GSM8K) and code (MBPP) benchmarks, DMax maintains high accuracy even as the number of tokens generated per forward pass (TPF) increases.
- Efficiency: DMax achieves 5.48 TPF on GSM8K, compared to 2.04 for the original LLaDA-2.0-mini.
- Robustness: As shown in the trade-off curves, while the original LLaDA's accuracy drops to near zero under aggressive decoding, DMax stays flat and reliable.
Critical Insight & Conclusion
The genius of DMax lies in realizing that MDLMs and UDLMs are two sides of the same coin. By unifying the stable initialization of masking with the corrective flexibility of uniform denoising, DMax provides a blueprint for the next generation of real-time LLMs.
Limitations: While DMax is extremely fast, it requires a "double forward" pass during OPUT training, which increases training FLOPs. However, this is a one-time cost for a permanent inference-time speedup.
Takeaway: If you want a model that generates 1000+ tokens per second on consumer-grade (tensor-parallel) hardware without losing its "intelligence," DMax's self-revising embedding approach is the way forward.