This paper introduces EffectErase, a state-of-the-art framework for effect-aware video object removal and insertion. By leveraging the new large-scale VOR dataset (60K pairs), it achieves SOTA results in eliminating complex side effects like shadows, reflections, and deformations.
TL;DR
One of the most frustrating issues in video editing is removing an object only to find its "ghost"—a lingering shadow or a reflection—still haunting the scene. EffectErase targets this specific pain point. By introducing the massive VOR dataset (60,000 video pairs) and a reciprocal learning framework that jointly trains on object removal and insertion, it sets a new standard for high-fidelity video editing.
The Problem: Why Simple Inpainting Fails
Most current video inpainting tools treat the task as "fill in the black hole defined by the mask." However, real-world objects don't exist in isolation; they interact with their environment.
- Shadows and Lighting: Removing a car but leaving its shadow on the road looks uncanny.
- Reflections: A person walking past a window leaves a reflection that is usually outside the primary segmentation mask.
- Deformations: A heavy object sitting on a cushion deforms the surface. Removing the object without restoring the original geometry creates visual artifacts.
Previous SOTA methods lacked the data and the architectural mechanism to "see" beyond the mask. EffectErase solves this by explicitly modeling the spatiotemporal correlation between the object and its environment.
Methodology: The Power of Reciprocal Learning
The core intuition of EffectErase is that Insertion and Removal are two sides of the same coin. They both interact with the exact same "affected regions."
1. Task-Aware Region Guidance (TARG)
Instead of just feeding a mask, EffectErase uses a TARG module. It takes a "task token" (representing the intent to remove or insert) and "foreground tokens" (extracted via CLIP from the object) and injects them into a Diffusion Transformer (DiT) backbone via cross-attention. This allows the model to dynamically "look" for areas where the object's presence would logically cause a change.
2. Effect Consistency (EC) Loss
During training, the model performs both tasks. The EC Loss ensures that the attention maps for "removing an object" and "inserting the same object" align perfectly. If the model identifies a shadow region when inserting a cone, the EC loss forces the removal branch to recognize that same region as something that needs erasing.
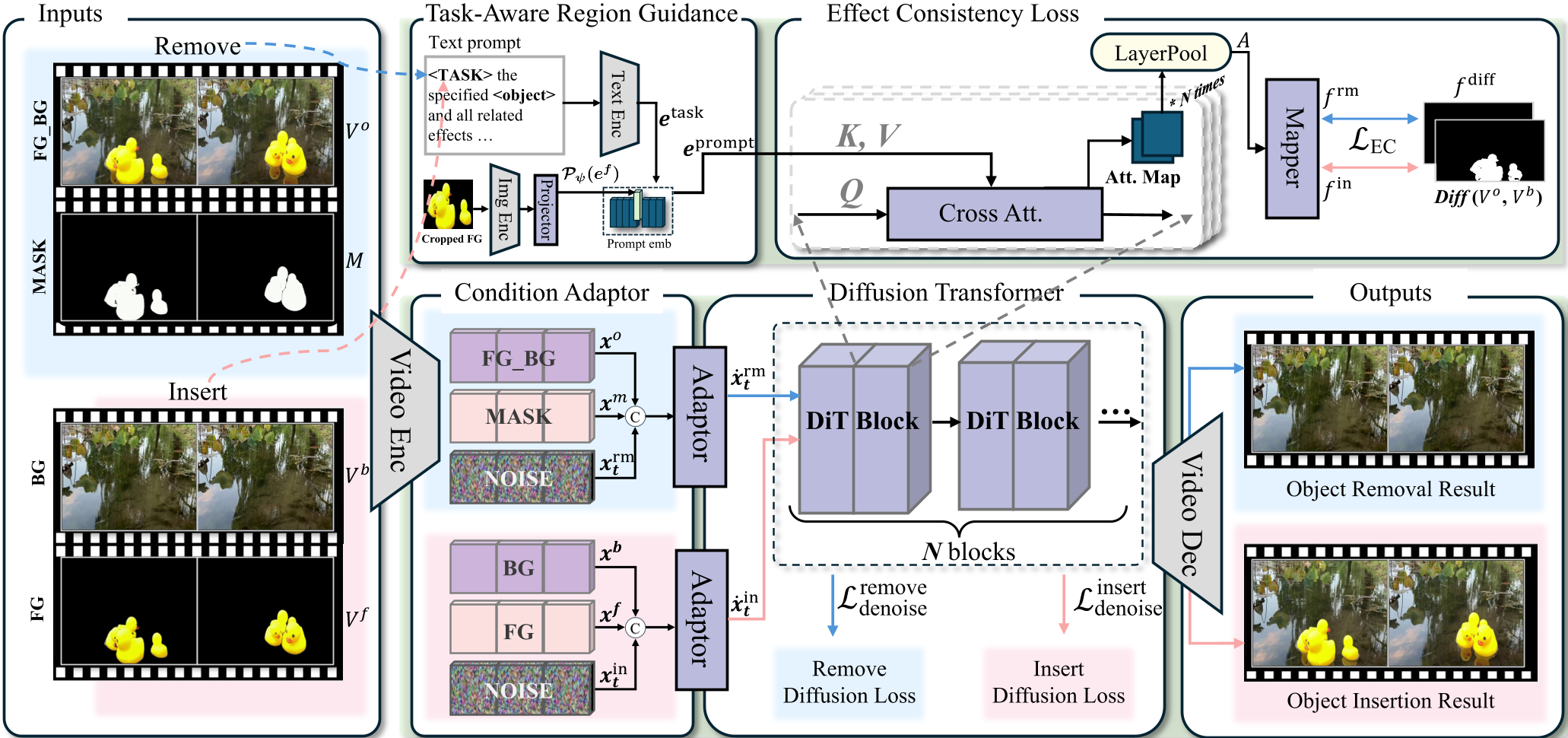 Figure 1: The EffectErase framework, highlighting the joint Removal-Insertion learning pipeline and the EC Loss mechanism.
Figure 1: The EffectErase framework, highlighting the joint Removal-Insertion learning pipeline and the EC Loss mechanism.
The VOR Dataset: A New Gold Standard
A major contribution of this work is the VOR (Video Object Removal) Dataset. Unlike previous datasets that were either too small or visually simplistic, VOR offers:
- 145+ Hours of Video: 60,000 paired sequences.
- Hybrid Sources: Combines physical realism from camera-captured data with the complexity of multi-object 3D rendered scenes.
- Five Effect Categories: Systematically covers Occlusion, Shadow, Lighting, Reflection, and Deformation.
Experimental Triumphs
The performance leap is quantified through standard metrics (PSNR, SSIM) and specialized video metrics like FVD (Fréchet Video Distance). EffectErase achieves a significant reduction in FVD compared to the previous best, ROSE, indicating much smoother and more coherent background restoration.
 Table 1: Quantitative comparison showing EffectErase leading across ROSE-Benchmark and VOR-Eval.
Table 1: Quantitative comparison showing EffectErase leading across ROSE-Benchmark and VOR-Eval.
The qualitative results are even more striking. In "In-the-Wild" scenarios involving fast-moving sports or complex nighttime lighting, EffectErase successfully erases secondary light splashes and reflections that other models completely miss.
 Figure 2: Real-world performance on VOR-Wild, demonstrating robust removal in mirror reflections and nighttime scenes.
Figure 2: Real-world performance on VOR-Wild, demonstrating robust removal in mirror reflections and nighttime scenes.
Critical Insight & Future Outlook
EffectErase proves that structural symmetry in learning tasks (Removal Insertion) provides an inductive bias that is far more effective than simply scaling the model. By forcing the internal attention mechanisms to be consistent across inverse operations, the model learns the "physics" of the scene—how light and geometry change when an object is removed.
Limitations: The current iteration still requires a manual mask. The next logical step for this technology is instruction-based erasing (e.g., "Remove the red dog and its shadow"), combining these high-fidelity visual results with natural language interfaces.
Conclusion: EffectErase is not just another inpainting model; it is an effect-aware editor that understands environmental context. For the industry, this means significantly reduced manual clean-up time in film post-production and more realistic AR/VR object manipulation.