本文提出了 EntropyCache,一种针对扩散语言模型(dLLMs)的无须训练的 KV Cache 优化方法。通过引入解码 Token 的最大熵作为衡量缓存偏移(KV Cache Drift)的指标,实现了在 LLaDA 和 Dream 等模型上 15.2x 至 26.4x 的推理加速,同时保持了与基线相当的准确率。
TL;DR
扩散大型语言模型(dLLMs)凭借并行生成的潜力正成为自回归(AR)模型的有力竞争者。然而,其**双向注意力(Bidirectional Attention)机制导致传统的 KV Cache 无法无损应用。本文提出的 EntropyCache 另辟蹊径,利用解码过程中 Token 的最大熵(Maximum Entropy)**作为“信号灯”,以极低的开销动态决定何时需要刷新缓存,实现了最高 26.4 倍的惊人加速,且决策开销几乎可以忽略不计。
1. 核心动机:为什么 dLLM 的缓存这么难做?
在标准的 GPT 类模型中,注意力是因果的(Causal),新 Token 不会改变旧 Token 的 KV 值。但在 LLaDA 或 Dream 这种扩散模型中,每个位置都会关注其他所有位置。只要有一个 Token 从 [MASK] 被预测出来,序列中所有位置的隐藏状态都会发生偏移。
为了加速,前人尝试过:
- 静态策略:简单粗暴地冻结部分 KV,但这会极大损伤模型精度。
- 动态策略:如 Elastic-Cache,通过监控每一层注意力权重的偏移(Drift)来决定是否重计算。这种方法准确但“太重”了——决策本身的计算开销甚至随着上下文长度二次增长。
2. 核心直觉:熵是洞察模型局部的“窗户”
作者提出了一个非常深刻的物理直觉:如果模型对某个位置的 Token 预测非常确定(低熵),那么将其固定下来对全局表示的影响就很小;反之,如果预测充满了不确定性(高熵),一旦确定该 Token,就会对整个序列产生巨大的“扰动”。
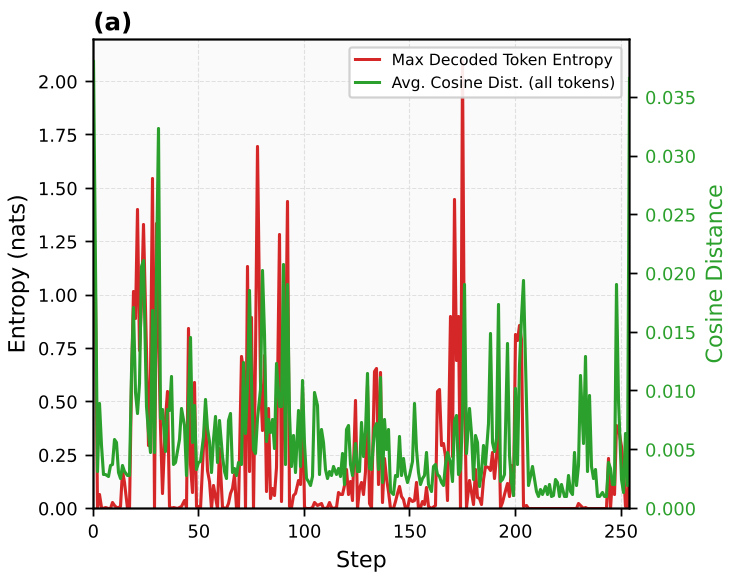 图 1:(a) 展示了熵的峰值与 KV 缓存偏移(Cosine Distance)高度同步;(b) 在对数坐标下展示了两者的强相关性。
图 1:(a) 展示了熵的峰值与 KV 缓存偏移(Cosine Distance)高度同步;(b) 在对数坐标下展示了两者的强相关性。
此外,作者发现 Token 的不稳定性具有“后劲”。Token 被预测后的前几个步长内,其特征向量仍在剧烈波动(Volatility),而非仅仅一瞬。
3. 方法论:EntropyCache 的三阶跳
EntropyCache 的工作流程非常优雅,分为三个相位:
- 熵触发决策(Entropy-based Skipping): 在每一步,计算新生成 Token 分布的最大熵 。如果 (阈值),则认为模型“成竹在胸”,跳过全局重计算。这个检测开销仅为 (V 是词表大小),与序列长度无关。
- 局部刷新(Recent Token Recomputation): 即便跳过了全局计算,为了修正上述的“特征波动”,算法会强制重计算最近解码的 个 Token 的 KV 值。
- 自适应更新: 通过维护一个解码历史记录,确保计算资源集中在最不稳定的 Token 上。
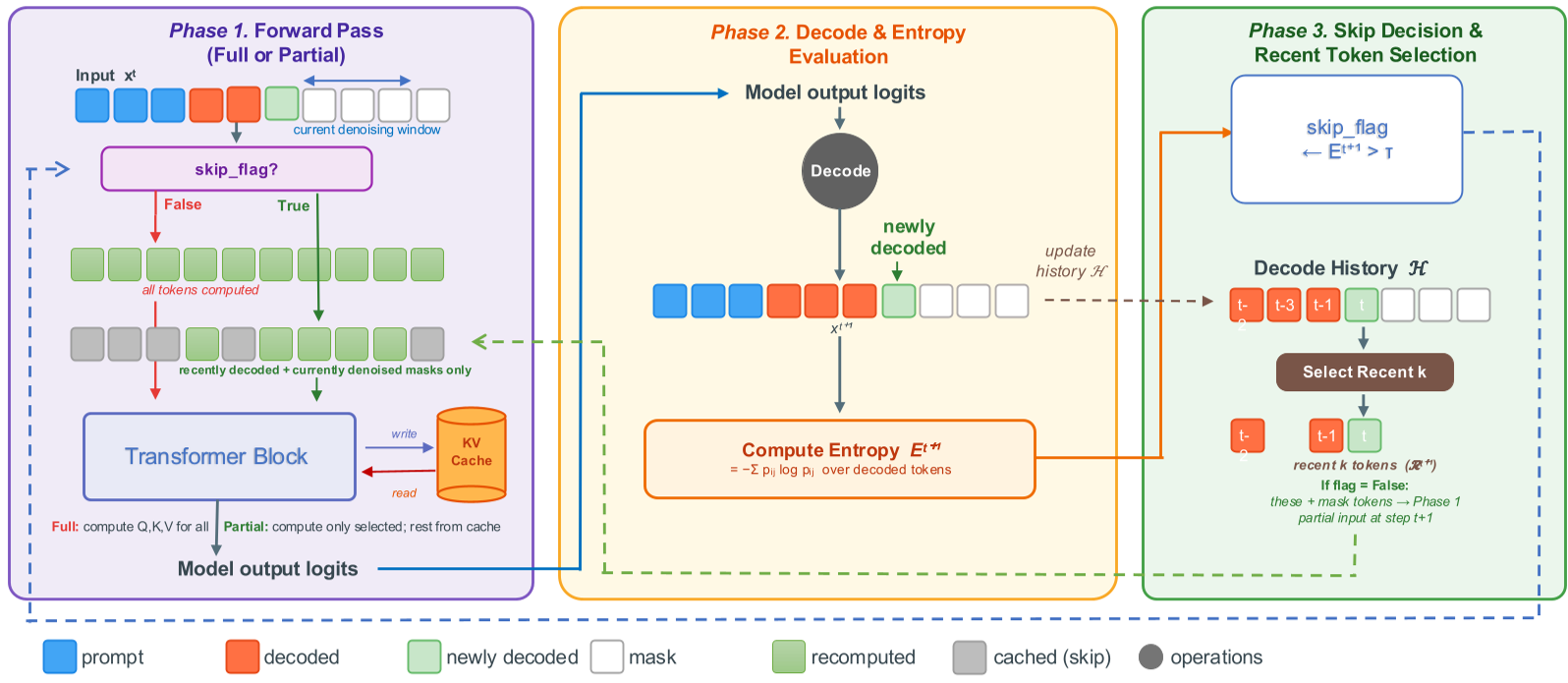 图 2:EntropyCache 的单步推理流程。
图 2:EntropyCache 的单步推理流程。
4. 实验结果:速度与精度的双赢
在 LLaDA-8B 和 Dream-7B 上的实验表明,EntropyCache 在各类任务(数学、代码、推理)上均表现优异。
- 加速比:在 GSM8K 等数学任务上达到 15x-18x,在链式思考(CoT)任务上由于长序列和多低熵步长,加速比甚至突破 100x(BBH 3-shot 任务)。
- 决策开销:如下表所示,EntropyCache 的决策耗时远低于同类动态方法,真正做到了“轻量级”。
 表 1:在 LLaDA 和 Dream 模型上的性能对比。
表 1:在 LLaDA 和 Dream 模型上的性能对比。
5. 深度洞察
EntropyCache 的成功在于它抓住了语义重要性与计算稳定性之间的桥梁。在 HumanEval 编程测试中,该方法甚至比基线更准确。有趣的是,作者发现高熵通常出现在逻辑连接词或关键公式的算子位置。这意味着,熵不仅是数学上的不确定度,更是模型生成过程中的“逻辑拐点”。
局限性与展望
虽然 EntropyCache 在 7B/8B 模型上表现强劲,但在更大规模(如 70B+)或更多模态下的表现仍需验证。此外,对于某些代码生成的特定任务,熵的预测能力会略微下降,可能需要更精细的阈值调优。
总结
EntropyCache 为扩散语言模型的大规模部署扫清了计算开销的障碍。它告诉我们,与其死磕复杂的注意力权重对比,不如听听模型自己对预测结果有多“纠结”。