本文提出了 Executable Video Alignment (EVA),一种通过强化学习对齐机器人视频世界模型的新框架。该方法利用逆动力学模型(IDM)将生成的视频转换为机器人动作,并以动作的可执行性(如平滑度、运动学约束)作为奖励信号进行后训练,显著提升了视频规划在真实机器人上的执行成功率。
TL;DR
在 Embodied AI 领域,用视频模型当“大脑”规划动作已成趋势。但问题是,大脑想出的“画面”往往是现实中机械臂做不到的。EVA (Executable Video Alignment) 框架通过强化学习,给视频模型装上了“物理反馈”。它利用逆动力学模型(IDM)评估视频生成的动作是否顺滑、是否合乎规范,从而有效缩小了视觉生成与物理执行之间的“可执行性间隙”。
背景:视觉上的“合理”等于物理上的“可行”吗?
目前机器人领域流行的解耦框架是:视频模型(视觉规划器) -> IDM(动作解码器)。 视频模型先按照指令画出一套“动作大片”,IDM 再把这套画面翻译成电机的转动指令。
然而,作者发现了一个致命痛点:Executability Gap (可执行性间隙)。 即使是在视觉上看起来非常逼真的视频,其细微的运动学失真(如机械臂长度忽长忽短、瞬间位移)在 IDM 眼里都是毁灭性的灾难,会导致机器人出现剧烈抖动甚至损坏。
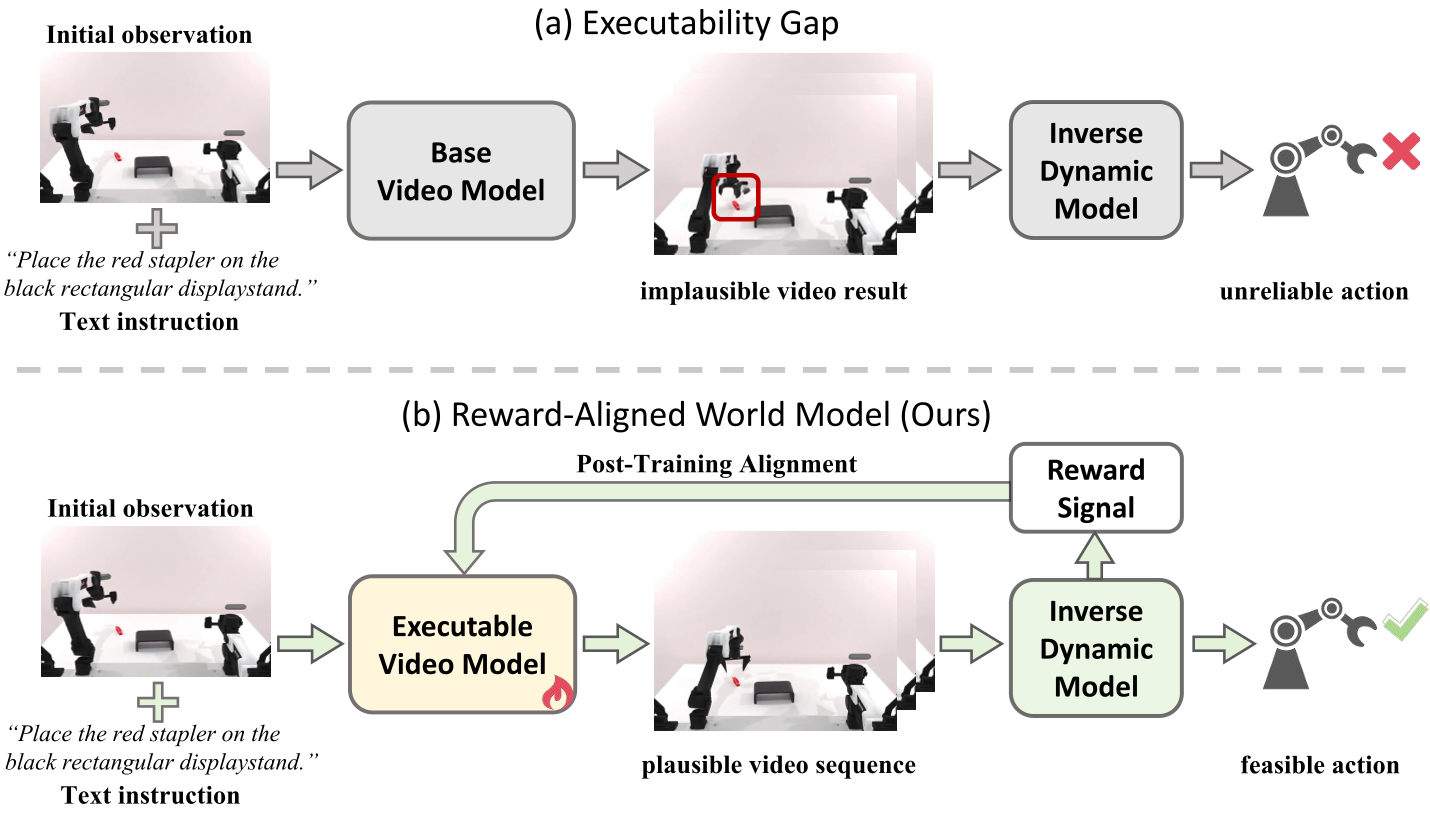
核心动机:将 IDM 从解码器“晋升”为裁判
既然 IDM 知道生成的视频好不好走,为什么不直接让它来教视频模型? 作者的研究直觉很简单:利用生成的动作质量作为奖励函数,通过强化学习微调视频模型。
技术亮点:如何定义“可执行性奖励”?
EVA 的核心在于一套基于动作空间的密集奖励系统。它不看像素像不像,而是看动作:
- 运动学惩罚:使用 Huber Penalty 惩罚过大的加速度(Acceleration)和加加速度(Jerk),确保动作“纵享丝滑”。
- 边界约束:如果生成的动作超出了机器人的物理极限(速度、关节角),直接给差评。
- RL 算法选择:采用了 DeepSeek 系列中名声大噪的 GRPO (Group Relative Policy Optimization),通过组内样本对比,绕过了复杂的 Value Function 学习,直接优化 Flow-matching 模型的飘移向量(Drift)。
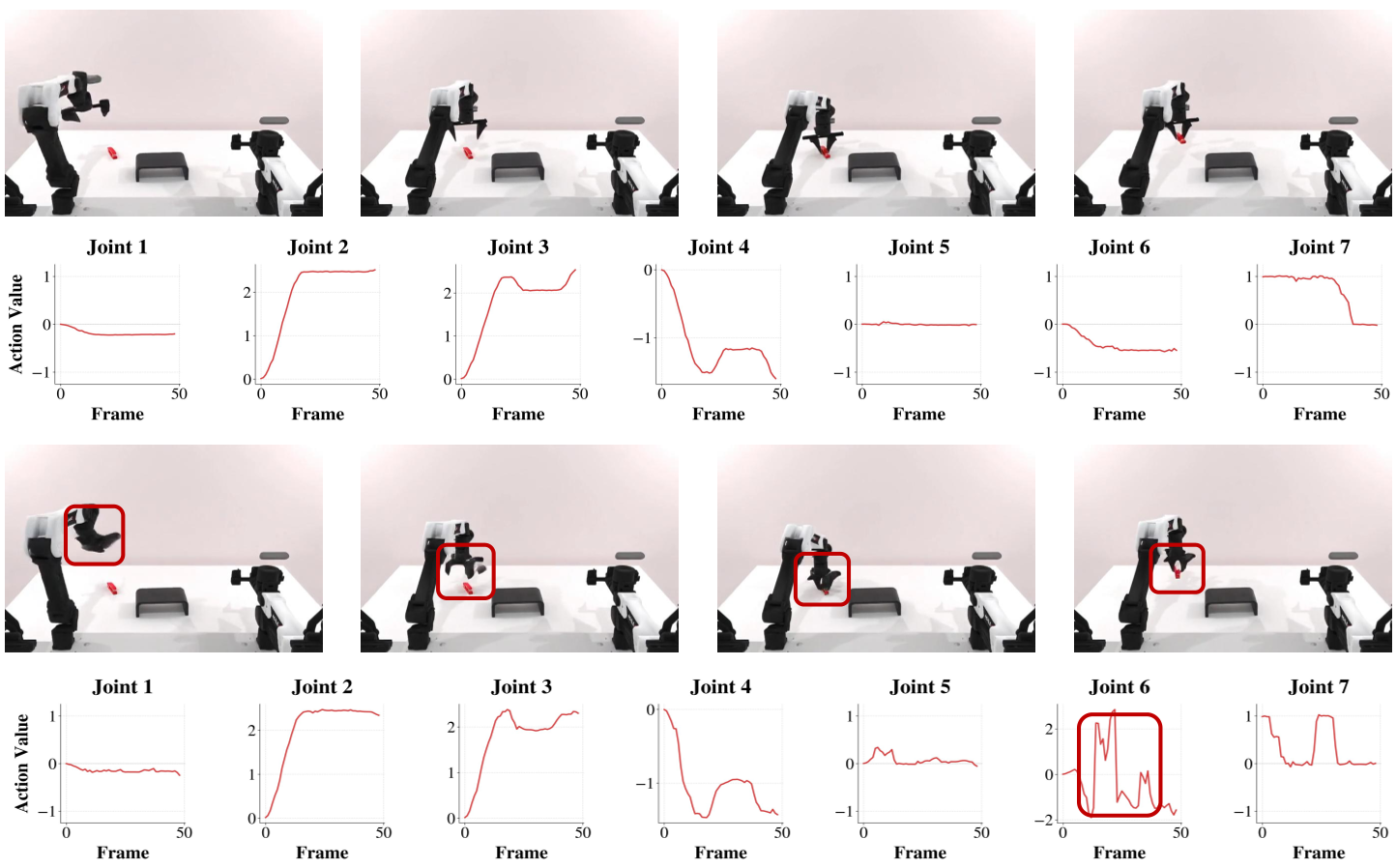
实验战果:更真实的视频,更稳的机器人
在 RoboTwin 2.0 仿真环境下,EVA 展现了极强的统治力:
- 画质质变:通过人类主观评估,EVA 在“运动学合理性”上比未对齐的模型高出 20.9%。
- 效率与鲁棒性:在双臂协作任务中,EVA 的平均成功率超越了 ACT、 以及 RDT 等强力 Baseline。
- 真实世界表现:即便是在从未见过的 OOD 任务中(如倒水、折衣服),EVA 的成功率依然保持在 60% 左右,体现了强大的泛化能力。

深度洞察:奖励黑客(Reward Hacking)的代价
有趣的是,作者在实验中也发现了 RL 的经典问题——奖励黑客。 如果训练时间过长,模型会为了“高分”而演化出奇怪的策略:比如让机器人完全静止不动(静止的动作一定是最顺滑的),或者生成虽然动作顺畅但完全错误的目标交互。这提示我们,后续的研究需要更精细地平衡“可执行性”与“任务完成度”。
总结
EVA 标志着视频世界模型从“只会看”进阶到了“懂行(懂物理)”。它的价值不仅在于提升了任务成功率,更在于它为自动生成高质量合成数据开辟了可能。未来,我们可以利用这种对齐的模型大规模生成“无病句”的机器人轨迹数据,进一步加速具身智能的进化。
主编点评:EVA 有效地将基础模型的 RL 对齐技术搬到了机器人物理空间。IDM 作为“桥梁”的角色转变令人惊艳——它不仅是翻译官,更是严厉的导师。