本文提出了 EvoIdeator,一个旨在提升大语言模型(LLM)自动化科学设想生成能力的框架。该方法通过将强化学习(RL)训练目标与基于清单(Checklist)的细粒度语言反馈相对齐,使仅 4B 参数量的模型在科学严谨性指标上显著超越了包括 Gemini 3 Flash 在内的巨型模型。
TL;DR
科学创新的核心在于不断的迭代与修正。华为诺亚方舟实验室与阿姆斯特丹自由大学的研究者提出了 EvoIdeator,通过将 强化学习(RL) 与 细粒度语言反馈 在训练阶段深度耦合,让一个 4B 参数的小模型能够在科学设想生成的严谨性上击败像 Gemini 3 Flash 这样的百倍级参数对手。其核心奥秘在于:不仅教模型写得好,更教模型如何“听取意见”。
痛点深挖:RL 与反馈的“双重鸿沟”
在自动科研探索领域,现有 LLM 往往面临两个尴尬境地:
- 反馈缺失感:传统的强化学习使用标量分数(比如 0.8 分)作为奖励,但模型不知道这 0.2 分丢在了哪里,缺乏改进的“抓手”。
- 训练推理脱节:许多方法在推理时给 LLM 喂反馈(Refinement),但模型在训练阶段从未见过这种结构化的批评,导致它对反馈的理解停留在表面,无法真正“内化”科研逻辑。
EvoIdeator 的研究直觉非常明确:如果能在训练时就模拟“草稿-评审-修改”的闭环,并用科学评估指标强制对齐奖励,模型就能学到科研进化的本质。
方法论详解:词典奖励与语言反馈的协奏
EvoIdeator 的核心架构由三部分组成:
1. 结构化科学清单(Checklist)
作者设计了一个包含 9 个维度的“科研裁判”量表,分为:
- 初级目标(硬指标):依据性(Grounding)、可行性(Feasibility)、问题定义、风险识别、方法严谨性。
- 次级目标(软指标):写作、创新度、长度合规性。
2. 词典排序奖励 (Lexicographic Rewards)
在多目标优化中,创新往往会牺牲可行性。EvoIdeator 采用了词典排序机制:模型必须先满足初级目标(如科学上站得住脚),才会获得奖励去优化次级目标(如写得更漂亮)。这防止了模型变成一个只会说大话但无法落地的“科幻作家”。
3. 可执行语言反馈 (Actionable Language Feedback)
裁判模型不仅打分,还会生成 Span-level 反馈:直接指出哪一段写得有问题,原因是什么,该如何修改。
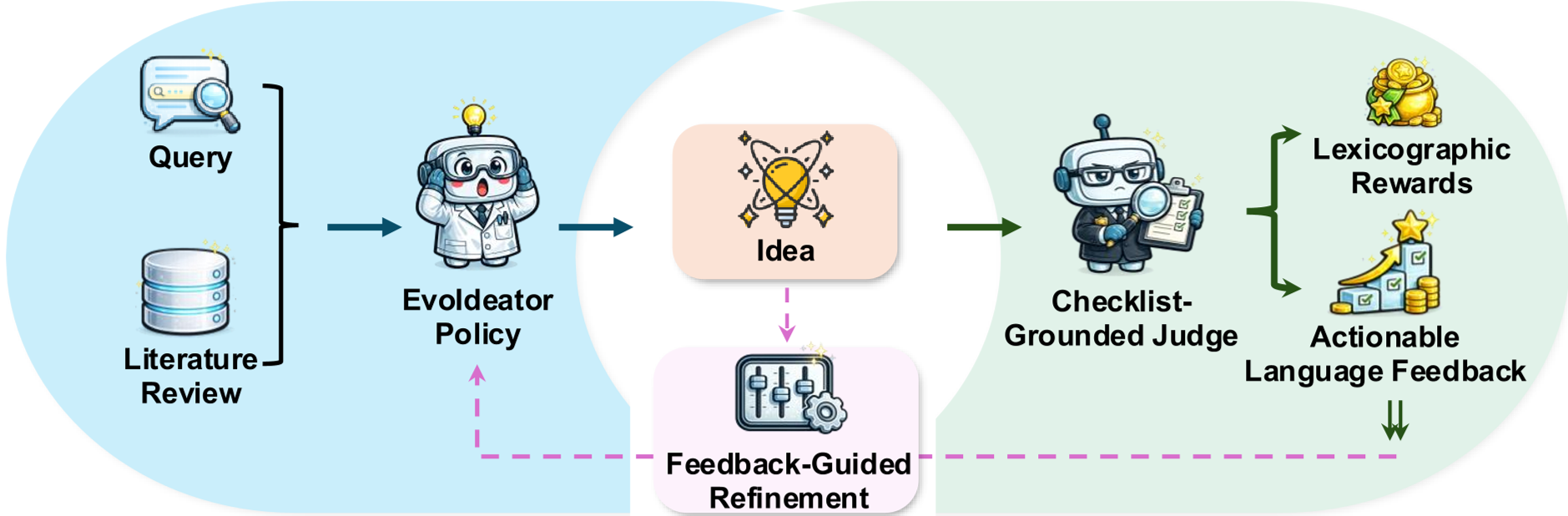 图 1:EvoIdeator 整体流程。从初始设想生成,到裁判给出双重信号,再到 RL 策略更新,形成闭环。
图 1:EvoIdeator 整体流程。从初始设想生成,到裁判给出双重信号,再到 RL 策略更新,形成闭环。
实验结果:4B 模型的华丽逆袭
研究团队基于 Qwen3-4B 进行了训练,并在一个包含 1000 篇最新研究趋势的测试集上进行了验证。
关键战绩:
- 全面超越 SOTA:在“依据性”和“问题定义”这两个核心科研指标上,EvoIdeator 经过一轮反馈后的表现优于 DeepSeek-V3.2 和 Gemini 3 Flash。
- 1+1 > 2:实验证明,单纯靠 RL 训练(提升天花板)或单纯靠推理侧反馈(提升迭代斜率)都不够,只有两者对齐,模型才能在迭代中取得最大增益。
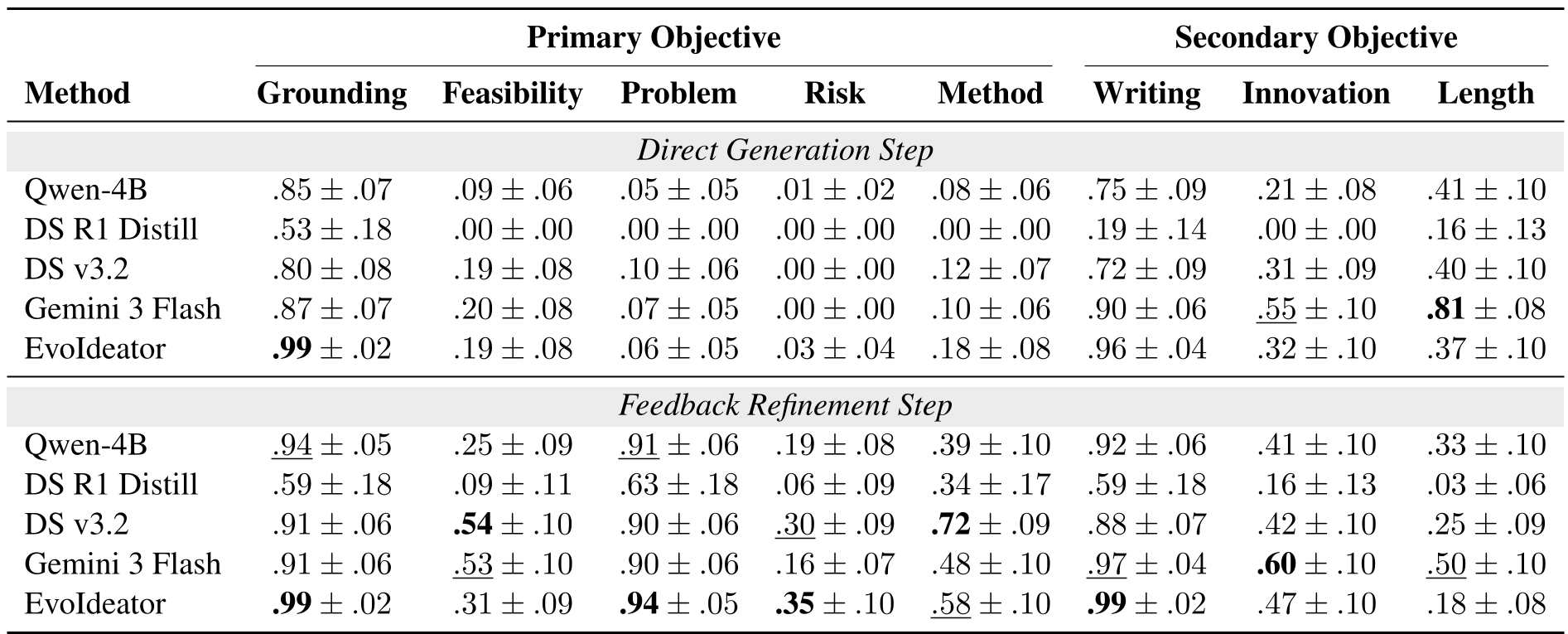 表 1:EvoIdeator 与各大家族模型的性能对比。可以看到在 Refinement Step 后,其核心科学指标遥遥领先。
表 1:EvoIdeator 与各大家族模型的性能对比。可以看到在 Refinement Step 后,其核心科学指标遥遥领先。
跨“裁判”的通用能力
一个有趣的发现是,EvoIdeator 在训练时使用的是 DeepSeek 的反馈,但在推理阶段换成其他的评委(如 GPT 系列),它依然能保持很强的改进能力。这说明模型学到的是 “处理科研反馈的逻辑”,而非单纯的 Prompt 模板对齐。
深度洞察与总结
核心价值 (Takeaway)
EvoIdeator 为自动科研发现(Autonomous Discovery)提供了一个可扩展的范式:模型越小,越需要精准的反馈对齐。 它证明了通过细粒度的反馈协议,可以用极低的计算成本训练出在专业领域具有极高逻辑严密性的模型。
局限性 (Limitations)
- 创新 vs. 严谨的权衡:目前的词典排序奖励可能过于偏向严谨性,导致模型生成的设想有时显得较为保守(Innovation 指标略逊于 Gemini)。
- 对反馈方言的敏感度:尽管具有一定的跨模型通用性,但如果裁判的写作风格(Dialect)与训练时差异过大,性能仍有波动。
未来展望
这项技术可以平移到任何需要高精度迭代的领域,如自动化软件工程、复杂法律文书撰写以及多模态科研设想(如制药分子设计)的演化建模。未来的 AI 科学家,可能不再是单纯的“大模型”,而是像 EvoIdeator 这样懂得在批评中进化的“专业模型”。