EXAONE 4.5 是由 LG AI Research 推出的首款开源权重视觉语言模型(VLM)。该模型基于 EXAONE 4.0 架构,集成了一个 1.2B 参数的视觉编码器,支持 256K 超长上下文及 6 种语言,在文档理解和多模态逻辑推理方面达到了 SOTA 水平。
1. 核心速览 (Executive Summary)
TL;DR:LG AI Research 正式发布 EXAONE 4.5,这是其首个开源权重的视觉语言模型(VLM)。它将 32B 的语言基座与自研的 1.2B 视觉编码器深度融合,支持 256K 超长上下文。在多模态数学推理、工业文档解析以及韩语语义理解等方面,EXAONE 4.5 表现出了惊人的竞争力,甚至在多个指标上超越了参数量大得多的 Qwen3-VL-235B。
背景定位:该模型不仅是 LG 在多模态领域的 SOTA 之作,更是其迈向 视觉-语言-动作 (VLA) 具身智能战略的关键一步,旨在解决制造业质量控制、工程图纸解析等真实工业场景痛点。
2. 痛点与动机 (Problem & Motivation)
在工业环境中,AI 面临的挑战远比通用对话复杂。现有的 VLM 模型在处理高分辨率的工程布线图、复杂的数学公式和长篇技术手册时经常“失焦”:
- 信息流失:为了节省计算资源,前人工作常采用压缩视觉 Token 的方法,但这会丢失识别微小零件缺陷所需的空间细节。
- 推理断层:许多模型能“看到”文字,但无法理解图表中的逻辑关系。
- 长文本瓶颈:传统的上下文扩展通常在 SFT 之后进行,容易破坏跨模态的对齐稳定性。
LG 的研究直觉是:不能为了效率牺牲视觉特征的丰富度。与其用小编码器接大模型,不如训练一个“重型”的视觉编码器,并配合更高效的注意力机制(GQA)来换取精度与速度的平衡。
3. 方法论详解 (Methodology)
架构革新:1.2B 专用视觉编码器
EXAONE 4.5 并没有直接借用现成的 CLIP 方案,而是从零训练了一个 1.2B 参数的视觉编码器。
- GQA (Grouped Query Attention):首次将大语言模型中常见的 GQA 引入视觉编码器,显著降低了视觉 Token 处理时的计算复杂度,提升了硬件利用率。
- 2D RoPE:由于图像是二维空间结构,模型采用了 2D 旋转位置编码,确保模型能精准捕捉图像块之间的空间拓扑关系。
- MTP (Multi-Token Prediction):通过多 Token 预测技术,进一步提升了推理过程中的解码吞吐量。
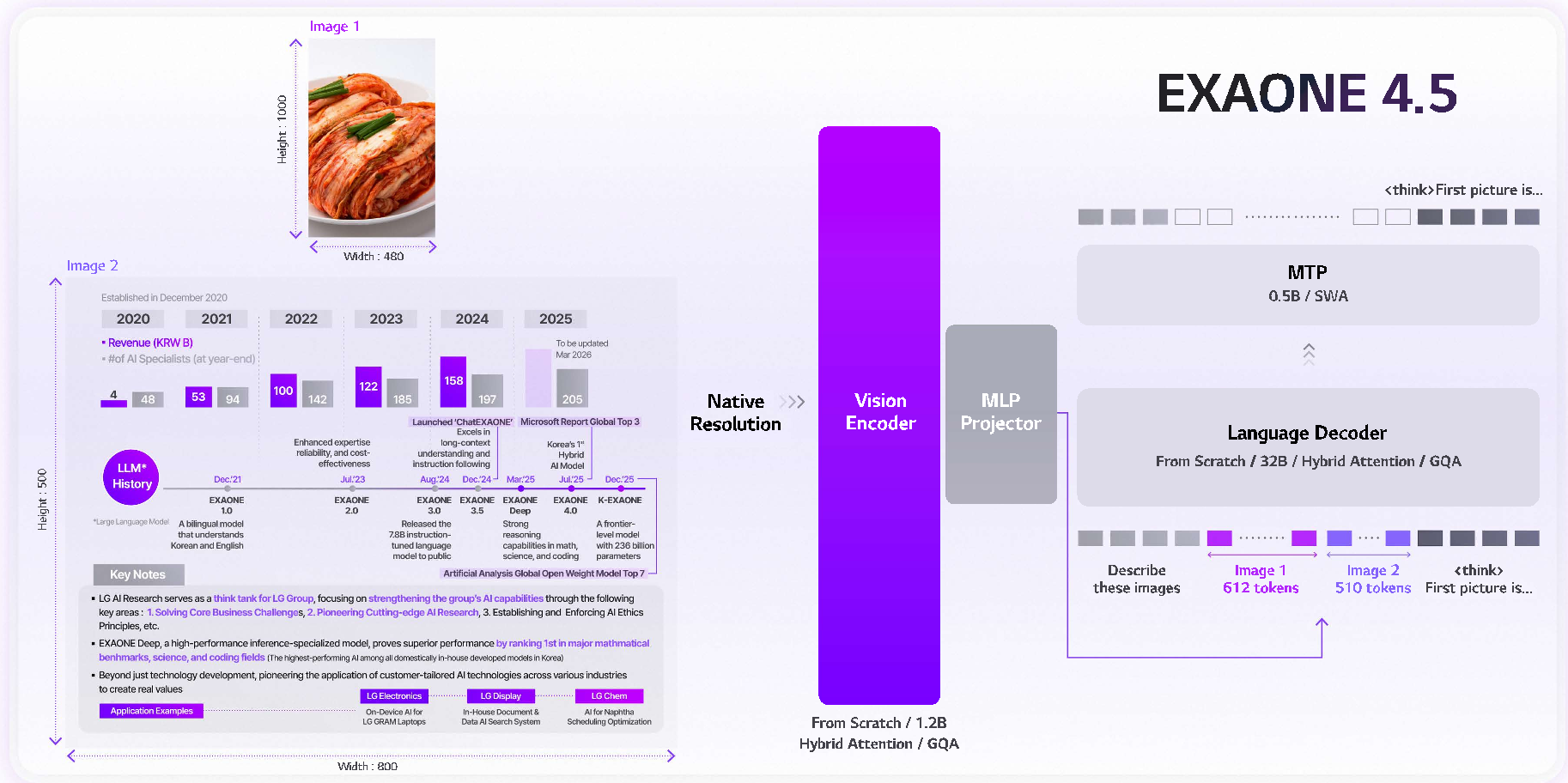
两阶段预训练策略
- 基础对齐阶段:使用大规模图文对、OCR 数据和交织文档进行初步对齐。
- 感知精炼阶段:上采样高质量的 STEM(科学、技术、工程、数学)数据和长链条思维(CoT)数据,强化模型的逻辑推理“内功”。
4. 实验与结果 (Experiments & Results)
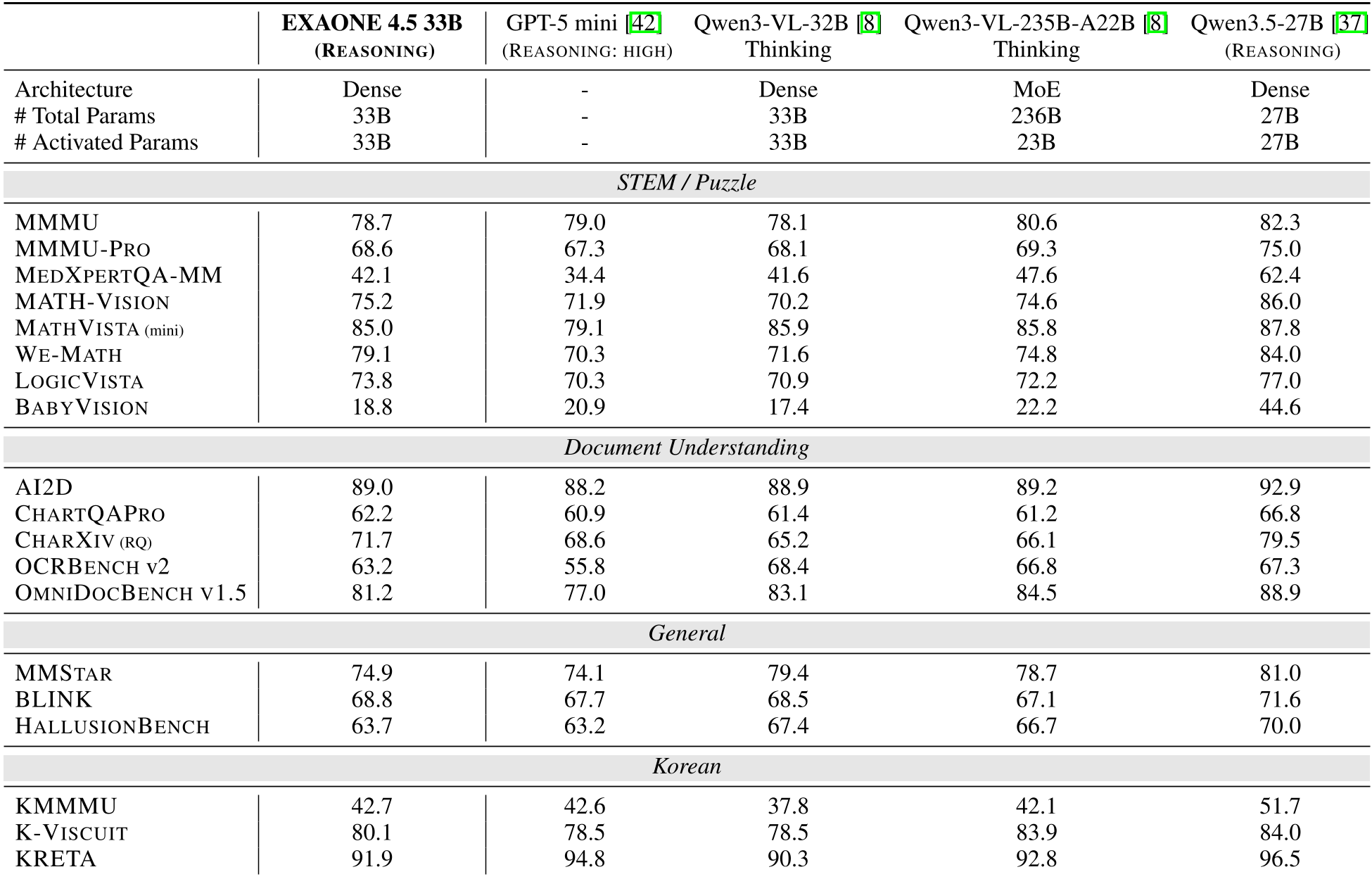
在 33B 这个参数量级上,EXAONE 4.5 的表现堪称“降维打击”:
- 数学与逻辑:在
MATH-VISION测试中拿到 75.2 分(Qwen3-VL-235B 为 74.6),在MMMU-PRO上也超越了 GPT-5 mini。 - 文档理解:针对工业文档设计的
CharXiv和OmniDocBench表现稳健,充分体现了其在处理表格、复杂排版上的优势。 - 编程能力:在
LiveCodeBench v6中以 81.4 的高分位居开源模型前列。
5. 深度洞察与总结 (Critical Analysis & Conclusion)
价值总结 (Takeaway)
EXAONE 4.5 的成功经验在于其数据策展的精准性。LG 重点针对工业场景(OCR、图表、多步推理)进行数据灌浆,这比单纯追求模型参数的堆叠更具商业实用价值。其开源策略(Hugging Face 与 GitHub 同时公布)也将极大推动工业级视觉助手领域的发展。
局限性与展望
尽管在逻辑推理上表现优异,但技术报告也坦诚:模型在某些情况下仍会出现幻觉,且对最新实时信息的掌握有限。未来,LG 计划将此模型作为基础,开发能够执行具体物理动作的 VLA (Vision-Language-Action) 模型,真正让 AI 走出实验室,走入工厂车间。
本文由资深学术主编重构。EXAONE 4.5 现已在 Hugging Face 开源,感兴趣的开发者可以前往体验:LGAI-EXAONE/EXAONE-4.5-33B