本文提出了 Sol-RL,一种专为 text-to-image 扩散模型设计的高效强化学习(RL)对齐框架。该方法引入了 FP4 量化加速 Rollout 探索,并通过“两阶段解耦”架构,在保持 BF16 训练精度的情况下,实现了高达 4.64 倍的收敛加速,显著提升了模型与人类偏好的对齐效果。
TL;DR
在追求扩散模型(Diffusion Models)与人类偏好对齐的路上,Rollout Scaling(增加采样规模) 已被证明是提升性能的“大力出奇迹”良方。然而,面对像 FLUX.1 (12B) 这样的庞然大物,采样成本高得令人发指。NVIDIA 等团队提出的 Sol-RL (Speed-of-light RL) 巧妙利用 NVFP4 量化进行大规模“海选”,再用 BF16 高精度进行“精修”优化。这种硬件与算法的协同设计,在不损失精度的情况下,将对齐速度最高提升了 4.64 倍。
痛点深挖:昂贵的采样与分身乏术的精度
在 RL 训练(尤其是 GRPO 架构)中,为了获得更稳定的梯度信号,我们需要针对每个 Prompt 生成一大批图像(如 96 张),然后从中选出最好和最差的进行对比学习。
这产生了一个尴尬的矛盾:
- 计算瓶颈迁移:训练过程中,原本耗时的反向传播(Backward)反而成了小头,大规模图像采样(Inference/Rollout)占据了超过 70% 的时间。
- 精度死局:既然采样慢,用量化加速行吗?不行。前人研究表明,直接用 FP4 等低精度图像训练模型,会引入虚假的伪影和噪声,导致模型学“歪”了,对齐质量断崖式下跌。
核心直觉:语义的“顽强”与权重的“脆弱”
作者发现了一个关键物理直觉:低精度量化虽然会破坏画面的微观细节(像素级误差),但它能完美保留宏观的语义结构。
换句话说,如果一张图在 BF16 下是“高分好图”,那么在 FP4 下它大概率依然是该组中的“相对好图”。实验证明,FP4 采样的奖励排名与 BF16 的相关性高达 0.927。
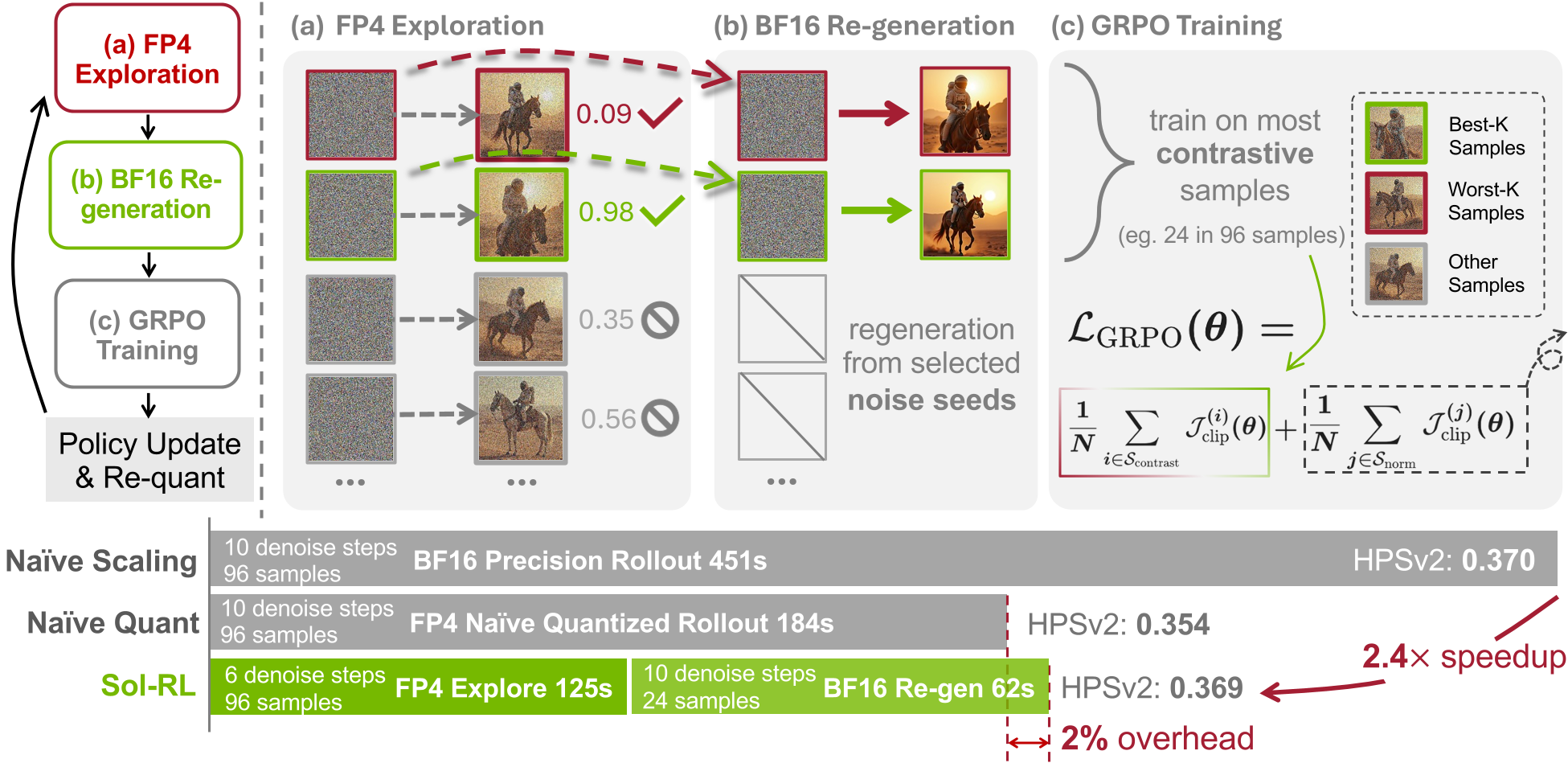
Sol-RL 方法论:两阶段解耦架构
基于上述发现,Sol-RL 设计了一套“海选-精修”流程:
第一阶段:FP4 高通量探索 (The Scout)
- 极速采样:将模型量化为 NVFP4,并将 Denoising Steps 压缩(如从 10 步减至 6 步)。
- 大规模海选:快速生成 96 个候选样本及其初始噪声种子。
- 排名过滤:通过奖励模型(Reward Model)打分,只留下表现最极端(最强和最弱)的 个种子(如 24 个)。
第二阶段:BF16 高保定再生 (The Master)
- 精准打击:利用筛选出的 个优质种子,切换回 BF16 精度重新生成高质量图像。
- 策略优化:模型仅基于这些“精修”后的高对比度样本进行梯度更新。
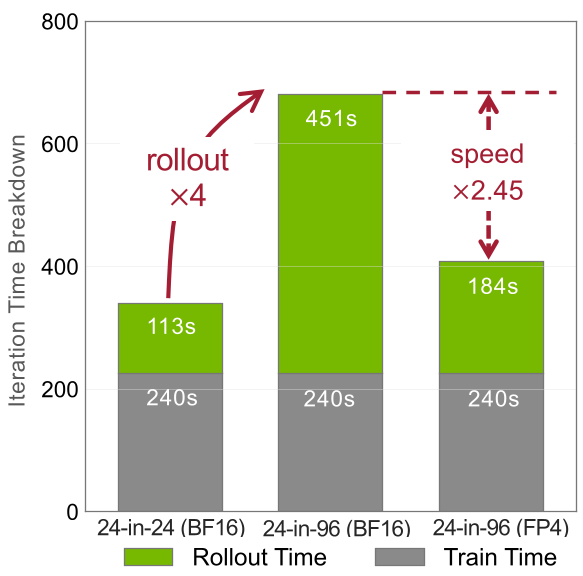
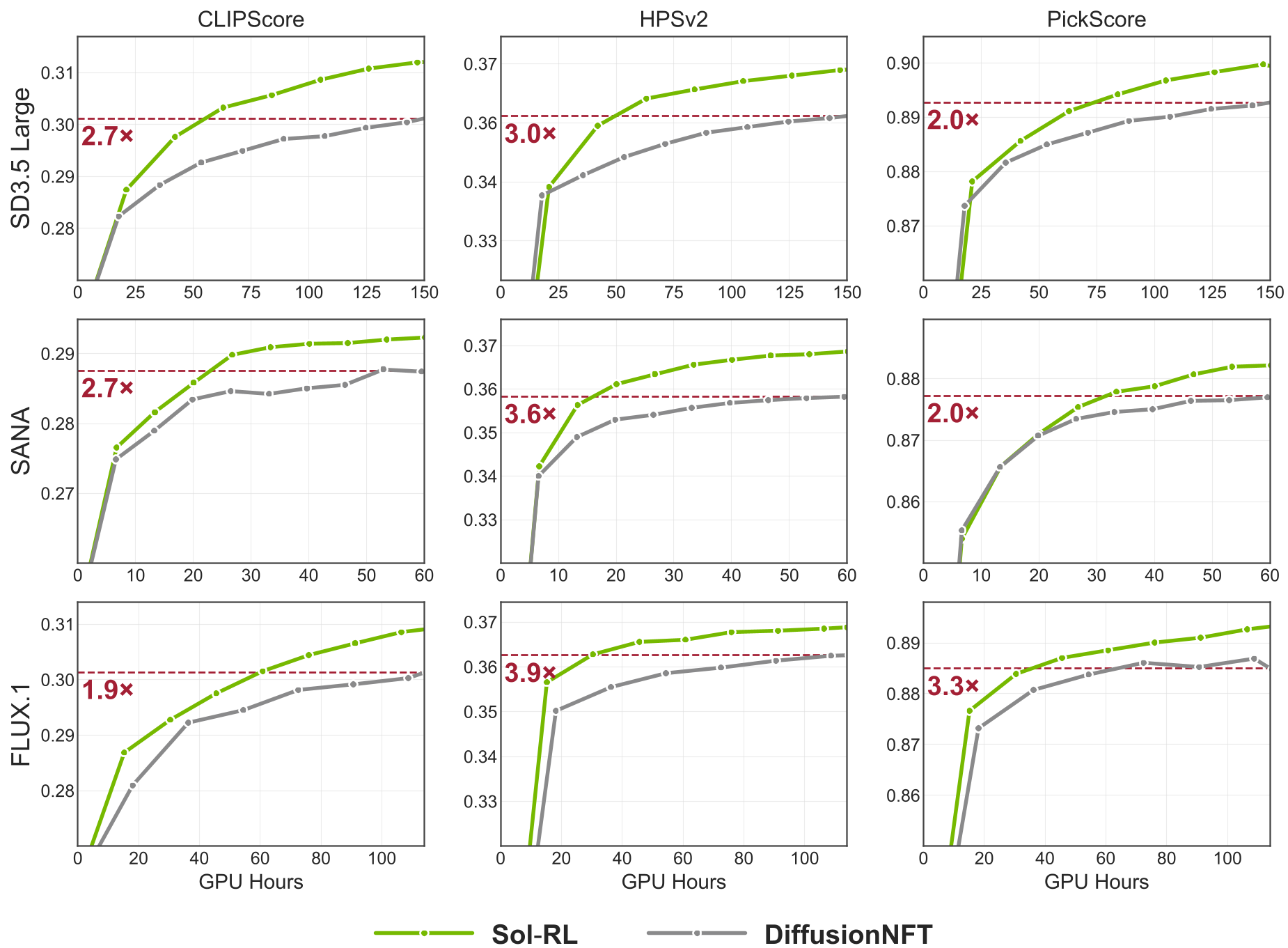
实验与战绩:全方位的降维打击
研究人员在 SANA-1.6B、FLUX.1-dev 和 SD3.5-Large 等模型上进行了严苛测试。
- 速度提升:在 FLUX.1 上,Sol-RL 实现了 1.62x 的端到端加速;在收敛效率上,最高达到了 4.64x 的提升。
- 对齐ceiling:不仅快,而且好。由于实现了更大规模的探索(Exploration Scale),Sol-RL 最终达到的 ImageReward 分数显著高于传统的 DiffusionNFT。
深度洞察:为什么这很重要?
Sol-RL 的成功在于它深刻理解了 Exploration (探索) 和 Optimization (优化) 在 RL 中的不同需求。
- 探索阶段:需要的是“直觉”和“速度”,对像素级的精度容忍度高。
- 优化阶段:需要的是“真理”和“细节”,对数值稳定性要求极高。
这种“软硬结合”的思路(利用 NVIDIA B200 的 NVFP4 硬件特性)预示了未来大规模生成模型训练的新常态:模型训练将不再是单一精度的齐头并进,而是根据任务模块的鲁棒性进行动态精度分配。
局限性与展望
尽管在 T2I 任务上表现优异,但这种基于“排名一致性”的假设在视频生成(T2V)等更复杂的长序列采样中是否依然成立,仍需进一步验证。此外,如何自动化地在不同训练阶段动态调整海选池大小()与精度步数,也是一个值得探索的方向。
总结: Sol-RL 证明了在算力为王的时代,聪明的算法架构设计可以在不烧更多钱的前提下,触达原本遥不可及的对齐性能边界。