本文系统研究了生成式推荐(GR)模型相比传统 ID 模型的泛化能力,提出了名为 MemGen-GR 的分析框架。研究通过 TIGER(语义 ID 路径)与 SASRec(唯一 ID 路径)的对比,证明 GR 模型在泛化任务上具有显著优势,而 ID 模型在记忆任务上更强。
TL;DR
生成式推荐(Generative Recommendation, GR)在近两年学术界风头无两,大家普遍认为它取代传统的 SASRec 是因为“泛化能力强”。但本文通过对 7 个真实数据集的精细化拆解发现:GR 模型的所谓“泛化”,其实是“Token 级的记忆”换了个马甲。 研究表明,GR 擅长组合新模式,而传统的 Item ID 模型在忠实记忆历史上表现更佳。基于此,作者提出了一个“自适应集成”方案,实现了 1+1>2 的性能突破。
背景定位
本文是推荐系统领域对 GR 范式的一次深度“审计”。它不满足于 SOTA 刷榜,而是从数据动力学的角度,精准划定了 GR 模型(如 TIGER)与 ID 模型(如 SASRec)的势力范围。
痛点深挖:记忆还是泛化?
在序列推荐任务中,我们通常根据用户的历史行为 [i1, i2, ...] 预测下一个项 it。
- 记忆 (Memorization):如果训练集里存在
i_{t-1} -> it的转换,模型只需死记硬背。 - 泛化 (Generalization):如果这个转换从未出现,模型必须通过传递性(Transitivity)、对称性(Symmetry)或多跳关联来推断。
以往的对比往往只看总分,导致我们忽略了 GR 模型在某些简单记忆场景下其实是不如传统 ID 模型的。
核心机制:Token 级别的显微镜
为什么 GR 表现出更好的泛化性?作者通过 Prefix N-gram Memorization 这一概念给出了物理直觉:
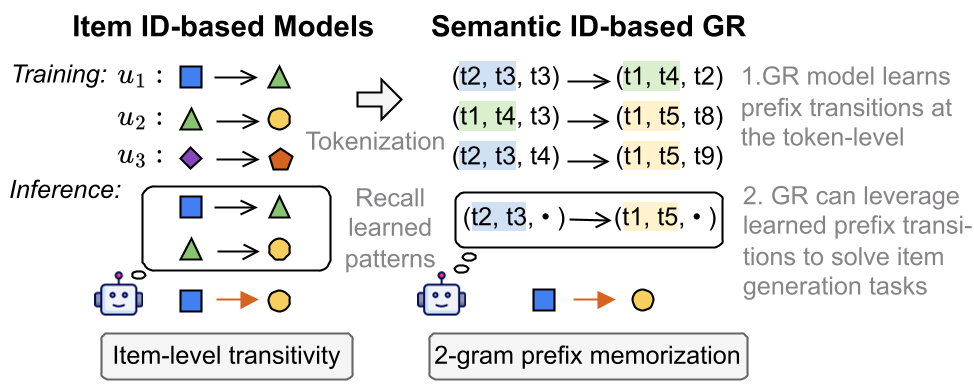
核心洞察:
- 项级泛化 = Token 级记忆:虽然
Item A -> Item B的转换在训练集中没见过,但Item A的语义前缀(Token)到Item B的语义前缀转换可能出现过成千上万次。GR 模型通过学习这些子项 Token 的规律,“拼凑”出了对新项转换的预测能力。 - 稀释效应 (Dilution Effect):当模型过度关注共享的 Token 前缀时,它对特定项的独特性记忆反而下降了。这就解释了为什么在热门推荐(高频项转换)上,GR 有时会被简单的 SASRec 吊打。
实验战绩
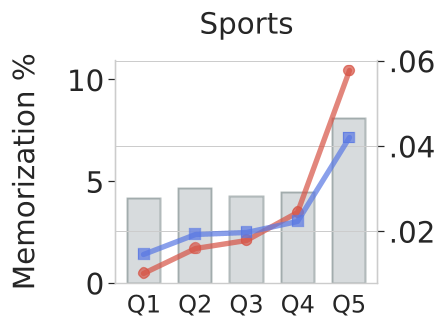
作者在 Sports、Beauty、Steam 等 7 个数据集上进行了大规模消融实验:

- 关键发现 1:在所有数据集上,TIGER 在泛化子集(Generalization Groups)上均保持领先。
- 关键发现 2:在跳数(Hops)增加的情况下,SASRec 的性能崩塌速度远快于 TIGER,证明了生成式架构对长距离抽象关联的处理能力。
深度洞察:自适应集成 (Adaptive Ensemble)
既然两种 paradigm 各有千秋,能不能既要又要? 作者提出了一个由 MSP (Maximum Softmax Probability) 驱动的指标。
- 当模型对某个预测非常“自信”(MSP 高)时,通常意味着这更倾向于一个记忆任务,此时调高 SASRec 的权重;
- 反之,权重向 TIGER 倾斜。
这种“因材施教”的方法在几乎所有指标上都刷新了基准。
总结与局限
Takeaway: 生成式推荐不是万灵药,它的强大源于对语义空间的“碎片化记忆”。
局限性: 当前框架主要基于语义 ID。如果未来引入多模态(图片/文本)作为 Token,这种记忆与泛化的分界线可能会进一步模糊。此外,如何设计更高效的 Tokenizer 以平衡“稀释效应”和“泛化收益”,仍是亟待解决的工业界难题。