本文提出了 Geometric Latent Diffusion (GLD) 框架,旨在为多视图扩散模型(Multi-view Diffusion)寻找最优潜空间。通过复用几何基础模型(如 Depth Anything 3)的特征空间而非传统的 VAE 空间,GLD 在新视角合成(NVS)任务中实现了极高的几何一致性和图像逼真度,并在多个基准测试中达到 SOTA 水平。
TL;DR
在 3D 生成和视角合成领域,Latent Space 的选择一直被 2D VAE 所统治。然而,Geometric Latent Diffusion (GLD) 告诉我们:与其在不识几何的潜空间里教模型 3D 规律,不如直接在“几何基础模型”的特征空间里进行扩散。GLD 通过复用 Depth Anything 3 的特征空间,不仅训练速度提升了 4.4 倍,更在无需 T2I 预训练的情况下击败了诸多 SOTA。
1. 动机:潜空间的“几何盲区”
传统扩散模型(如 Stable Diffusion)是在 VAE 压缩的潜空间中工作的。这个空间虽然对语义敏感,但对 3D 结构几乎没有感知。当我们将这种架构迁移到 新视角合成 (NVS) 任务时,模型必须痛苦地学习如何在多个视角之间保持几何一致性,这往往需要成千上万的高质量 3D 数据对和复杂的外部几何注入(如 Depth Warping)。
作者提出了一个直击本质的问题:能否找到一个本身就编码了几何结构的潜空间?
2. 核心贡献:把 DA3 变成“几何 VAE”
GLD 并没有训练一个新的 Autoencoder,而是直接“征用”了 Depth Anything 3 (DA3) 等几何基础模型的特征空间。
2.1 寻找最优边界层 (Boundary Layer)
DA3 的 ViT 骨干网络会提取多层特征。作者发现:
- 极深层 (Level 2/3):虽然 3D 结构感极强,但丢失了太多的纹理和颜色细节(光度信息不足)。
- 极浅层 (Level 0):色彩丰富,但缺乏跨视图的对应关系(PCK 指标低)。
- Level 1:成为了“Golden Mean”,它既保留了足够的 3D 一致性,又能支持高保真的 RGB 重建。
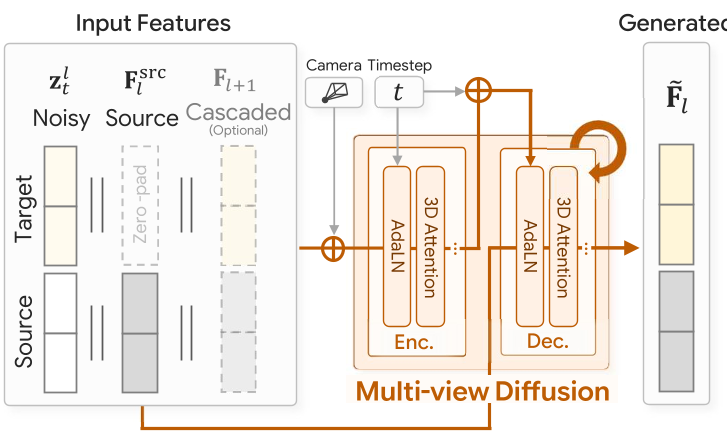 图 1:GLD 框架概览。左侧为级联特征生成流程,右侧为多视图扩散模型内部构造。
图 1:GLD 框架概览。左侧为级联特征生成流程,右侧为多视图扩散模型内部构造。
2.2 级联生成与传播
为了节省计算开销,GLD 并不生成所有层级的特征。它采用了一种巧妙的策略:
- 显式扩散生成 Level 1 特征。
- 将 Level 1 特征通过冻结的 DA3 后半部分网络,自动推导出 Level 2 和 3。
- 通过一个轻量级的级联模型 $M_{1 o 0}$ 生成最细节的 Level 0。
3. 实验战绩:不靠大模型先验的降维打击
GLD 最令人惊讶的结论是:即便它从零开始训练(From Scratch),其表现也优于那些在数亿张文本-图像对上预训练过的模型。
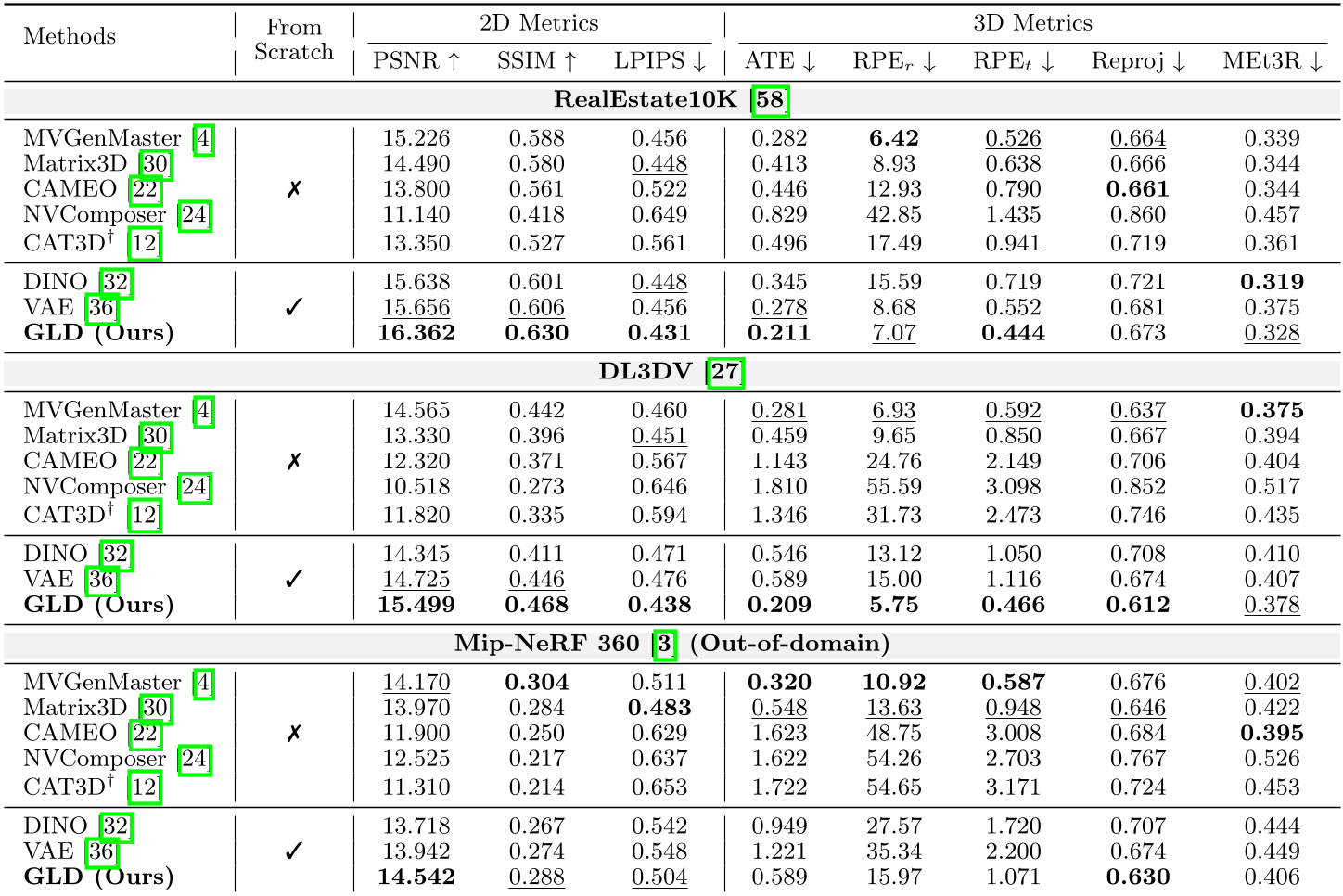 表 1:在 RealEstate10K 和 DL3DV 数据集上的测试。GLD 在几何一致性指标(ATE, RPE)和图像质量指标(PSNR)上全面领先。
表 1:在 RealEstate10K 和 DL3DV 数据集上的测试。GLD 在几何一致性指标(ATE, RPE)和图像质量指标(PSNR)上全面领先。
- 几何鲁棒性:在 DL3DV 数据集上,GLD 的位姿误差(ATE)比 VAE 基线低了 2.8 倍。这说明由于潜空间本身自带几何约束,模型即便面对稀疏输入也能“脑补”出正确的视角。
- 零成本的几何副产品:由于是在几何特征空间生成的,生成的 Latent 可以直接扔进原生的几何解码器,瞬间输出一致性极高的深度图和 3D 点云,且无需任何额外微调。
 图 2:GLD 生成的点云(右)相比 Matrix3D(左)具有更少的重影和更好的结构闭合性。
图 2:GLD 生成的点云(右)相比 Matrix3D(左)具有更少的重影和更好的结构闭合性。
4. 深度洞察:为什么有效?
作者通过分析扩散过程中的内部 Attention Map 发现(见原文附录 D.1),在 DA3 潜空间中训练的模型,其 3D Self-Attention 层天然表现出极强的跨视图对应性(Correspondence)。
这意味着,几何基础模型的特征空间为扩散模型提供了一个“降采样后的流形”,这个流形过滤掉了那些不符合几何规律的噪声,使得扩散过程在一种受到物理约束的通道中演化。这解释了为什么 GLD 的收敛速度能有 4.4 倍的恐怖提升。
5. 总结与局限
GLD 成功地将“表征学习”和“生成建模”在 3D 领域进行了深度耦合。它的价值在于证明了:Latent Space 不应当是通用的数据压缩器,而应当是任务感知的结构先验容器。
局限性:采样速度是目前的一个短板,由于采用了级联生成的两阶段采样,其生成耗时大约是直接在 VAE 空间生成的两倍(约 66 秒)。未来如何通过蒸馏或一致性模型(Consistency Models)加速其几何特征的生成,将是一个重要的研究方向。
Senior Editor's Note: 此工作的真正意义在于挑战了“只要预训练数据够大,模型就能学到几何”的迷信。GLD 用精巧的架构设计告诉我们,正确的归纳偏置(Inductive Bias)往往比盲目的 Scaling 更高效。