This paper explores the persistence of hallucinations in LLMs, attributing them to a "discriminative gap"—the inability to distinguish between known and unknown facts. It proposes "Faithful Uncertainty" and "Metacognition" as a solution, where models align their linguistic expressions (hedging) with their internal confidence to preserve utility while maintaining trust.
Executive Summary
TL;DR: Large Language Models (LLMs) continue to hallucinate not just because they lack knowledge, but because they lack "metacognition"—the ability to know what they don't know. Current mitigation strategies force an untenable "utility tax" by demanding models either be 100% right or stay silent. This paper argues for Faithful Uncertainty: a framework where models communicate their internal doubts through linguistic hedging, transforming "confident hallucinations" into "useful hypotheses."
Academic Positioning: This work moves beyond the saturated field of "knowledge expansion" to tackle the structural "discriminative gap." It positions metacognition as the essential control layer for the next generation of autonomous agentic systems.
The Problem: The Unavoidable Utility Tax
The industry has long treated hallucinations as a binary failure of factuality. However, the authors posit a sobering reality: models lack the discriminative power to separate truths from errors.
Even a "well-calibrated" model (one that knows it's right 60% of the time on average) often fails at the instance level. To eliminate a 25% error rate down to 5%, a model might have to refuse to answer 52% of the questions it actually knows correctly. This "utility tax" is why most frontier models still hallucinate; providers are unwilling to sacrifice that much helpfulness for the sake of perfect reliability.
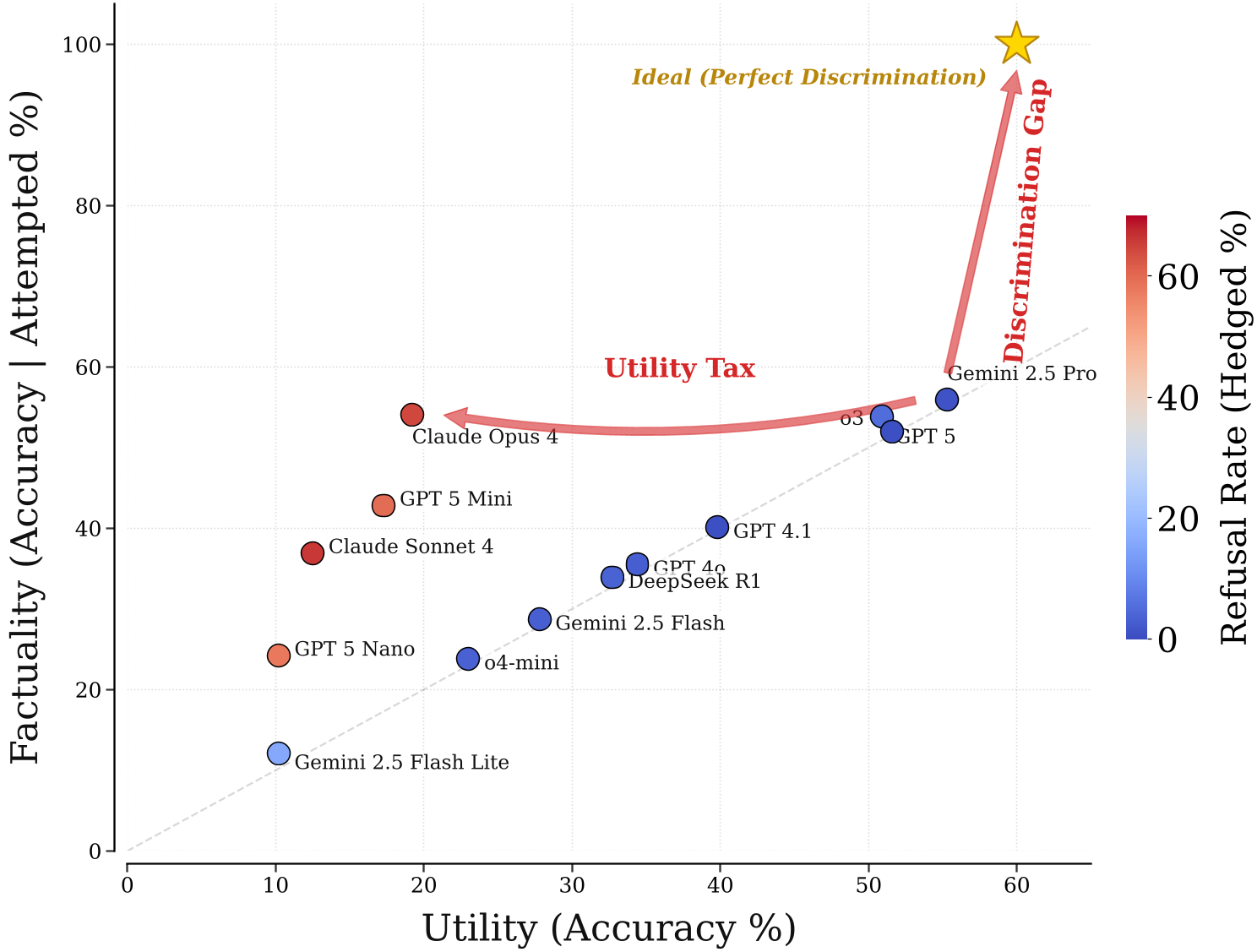 Figure 1: The "ideal" top-right corner of the SimpleQA benchmark remains empty, illustrating that current models cannot achieve high factuality without massive utility loss.
Figure 1: The "ideal" top-right corner of the SimpleQA benchmark remains empty, illustrating that current models cannot achieve high factuality without massive utility loss.
The Solution: Faithful Uncertainty & Metacognition
If we redefined a hallucination as a "confident error" rather than just an "error," a third path emerges. A model doesn't need to be omniscient; it just needs to be honest.
1. Intrinsic vs. Linguistic Uncertainty
The authors define Faithful Uncertainty as the alignment between two states:
- Intrinsic Uncertainty: The model's internal statistical confidence (e.g., how likely it is to generate the same answer twice).
- Linguistic Uncertainty: The words the model uses to express that confidence (e.g., "I am 90% sure" vs. "I might be mistaken").
2. The Metacognitive Control Layer
In agentic systems, this metacognition becomes the "brain" for tool use. A model that understands its own uncertainty knows when to search Google and how much to trust the search results over its own internal memory. Without this, agents either overuse tools (inefficiency) or ignore them (sycophancy).
 Figure 2: Metacognition serves as the API between the raw LLM and the agent harness, regulating behavior based on internal doubt.
Figure 2: Metacognition serves as the API between the raw LLM and the agent harness, regulating behavior based on internal doubt.
Methodology: Crossing the Discriminative Gap
The paper identifies that the "discriminative gap" (AUROC between 0.70 and 0.85) is the primary bottleneck. At these levels, the overlap between the confidence of correct answers and incorrect ones is too high.
The proposed methodology focuses on Faithfulness—ensuring the model maps its internal parameters to its output string. This is a "closed-loop" problem that is fundamentally more solvable than mapping parameters to the infinite, ever-changing external world.
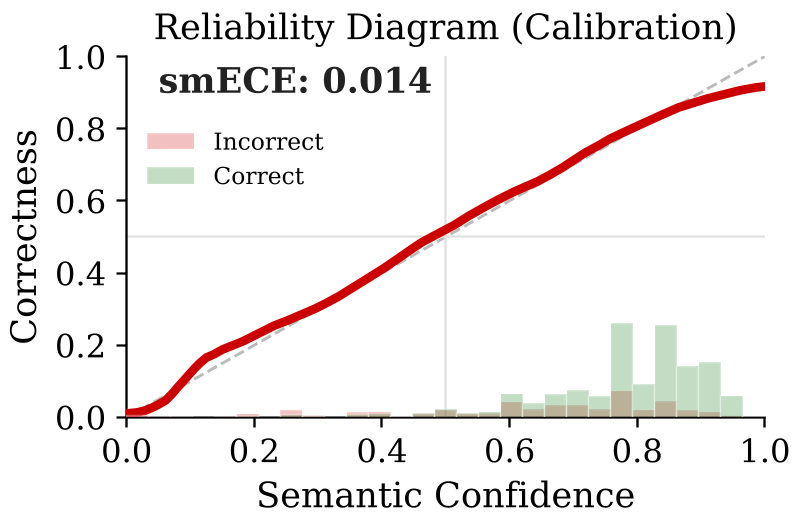 Figure 3: High calibration does not equal high discrimination. The overlapping distributions of correct/incorrect answers create the utility-error tradeoff.
Figure 3: High calibration does not equal high discrimination. The overlapping distributions of correct/incorrect answers create the utility-error tradeoff.
Critical Insight: The "Bootstrapping Paradox"
A fascinating challenge highlighted is how we train these models. Most LLMs are trained on authoritative internet text (Wikipedia, etc.) that rarely hedges. If we fine-tune a model to say "I don't know" for a fact it actually knows (a static label), we break its internal calibration.
The community needs "uncertainty-preserving" alignment algorithms—methods that allow models to follow instructions and stay safe without erasing the subtle internal signals that indicate doubt.
Conclusion: A New Call to Action
The authors urge the research community to stop measuring single-point accuracy and start:
- Visualizing the Utility-Error Trade-off: Show the curve, not just a single ECE score.
- Prioritizing Discrimination over Calibration: It's more important for a model to separate right from wrong than to be right on average.
- Embracing Reliable Utility: A doctor who says "I think this is the diagnosis, but it’s a hypothesis we need to test" is more helpful and trustable than one who is either silent or falsely confident.
By shifting the goal from "Never be wrong" to "Know when you might be wrong," we can finally build AI systems that users can truly rely on.