本文提出了 LEAFE 框架,旨在通过“回溯与反思”机制提升大语言模型(LLM)作为自主智能体的环境交互能力。该方法在测试集 CodeContests 和 WebShop 等任务上显著提升了 Pass@k 性能,尤其在 Pass@128 指标上比基线模型高出多达 14%。
TL;DR
当前大模型智能体(Agents)训练的一大痛点是“只会做做过的题”。本文提出的 LEAFE 框架通过让模型在训练阶段经历“失败 -> 回溯 -> 反思 -> 纠正”的全过程,并将这种纠错能力通过蒸馏内化到模型参数中。实验证明,这种方法能显著拓宽模型的探索边界,在长程任务(如复杂编程和网页导航)中,通过高频采样获得的性能上限(Pass@128)获得了质的飞跃。
背景定位:奖励的“贫瘠”与分布的“锐化”
在当前的 RLVR(基于验证奖励的强化学习)范式下(如 DeepSeek-R1 使用的 GRPO),我们通常给模型一个最终的成功/失败信号(0 或 1)。虽然这能提升 Pass@1(即模型一击即中的概率),但研究发现这往往会导致 Distribution Sharpening。
- 痛点:模型变得过于保守,只会复现那些它本来就有点把握的成功路径。
- 后果:当任务变得极长、环境反馈极其复杂时,模型一旦踏错一步就全盘皆输,增加采样次数(Pass@k)也无法找回成功路径。
核心机制:LEAFE 的两阶段进化论
LEAFE 的核心直觉是:与其告诉模型“你错了”,不如教它“哪里错了以及如何回溯修正”。
第一阶段:基于树的带回溯经验生成
模型并不只是盲目地进行 Rollout。每隔一段时间或遇到错误,模型会调用一个“反思过程”:
- 定位:识别轨迹中哪一步()导致了偏离。
- 总结:生成一个简短的行动建议 (经验摘要)。
- 分支:重置环境到 点,在 的指导下探索一条新路径。 这构建了一个隐式的“回溯树”,产生了大量包含纠错逻辑的成功轨迹。
第二阶段:经验蒸馏(Internalization)
这是 LEAFE 最关键的一步。它不要求在测试时进行昂贵的反思,而是通过监督微调(SFT)将纠错行为内化:
- 反事实训练:模型被要求在没有显式经验 的情况下,预测出那些在第一阶段通过 才纠正过来的动作。
- 行为排练:保留原始的成功路径,防止模型忘本。
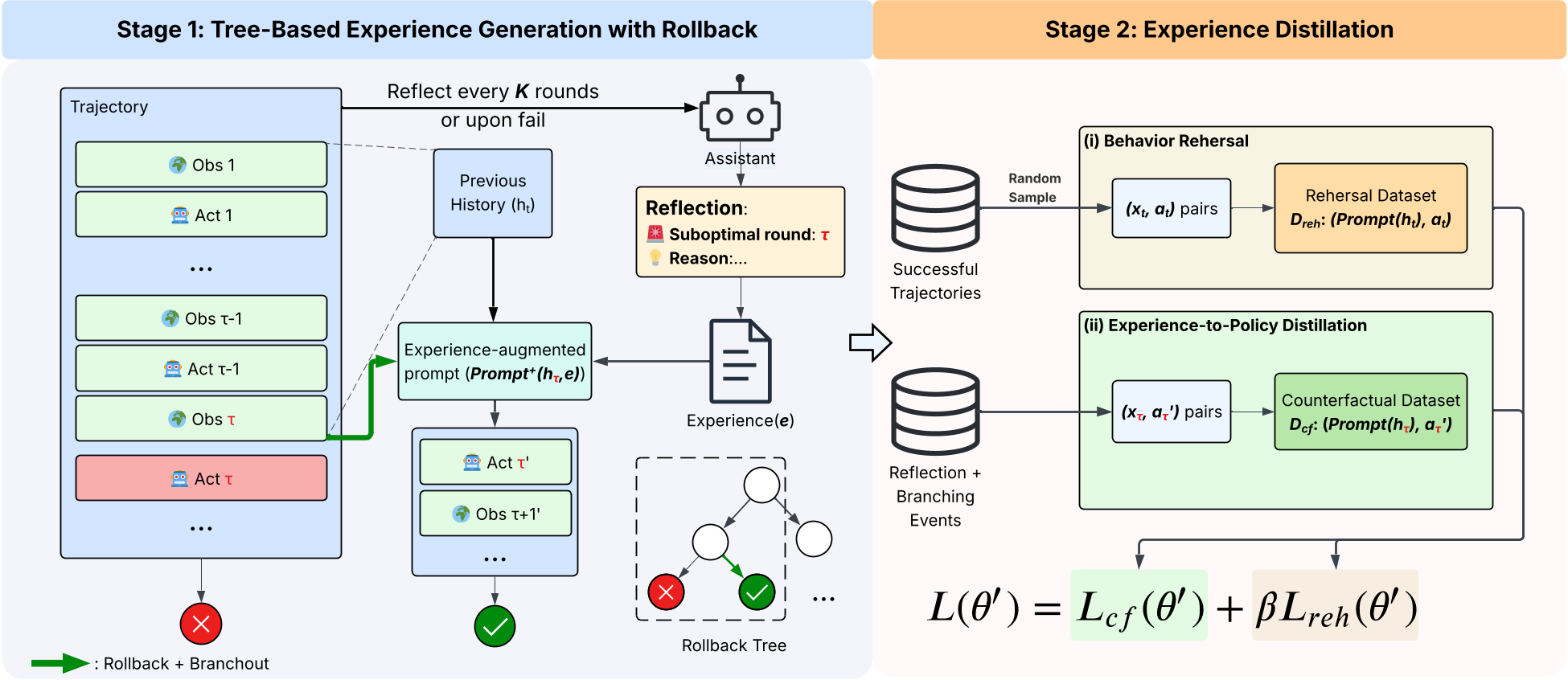 图 2:LEAFE 框架示意图,展示了从回溯探索到参数蒸馏的过程。
图 2:LEAFE 框架示意图,展示了从回溯探索到参数蒸馏的过程。
实验战绩:突破能力 ceiling
LEAFE 在 CodeContests (编程)、WebShop (导航)、Sokoban (推箱子) 等任务上进行了全面评估。
- SOTA 的新高度:在 Qwen2.5-72B 上,LEAFE 将 CodeContests 的 Pass@128 从基线的 33.9% 提升至 47.9%。
- 样本效率:观察图 3 的 Scaling 曲线可以发现,LEAFE 在采样次数增加时,其成功率的增长斜率远高于 GRPO。这意味着 LEAFE 训练出的模型更有“韧性”,能够通过多几次尝试解决极其困难的问题。
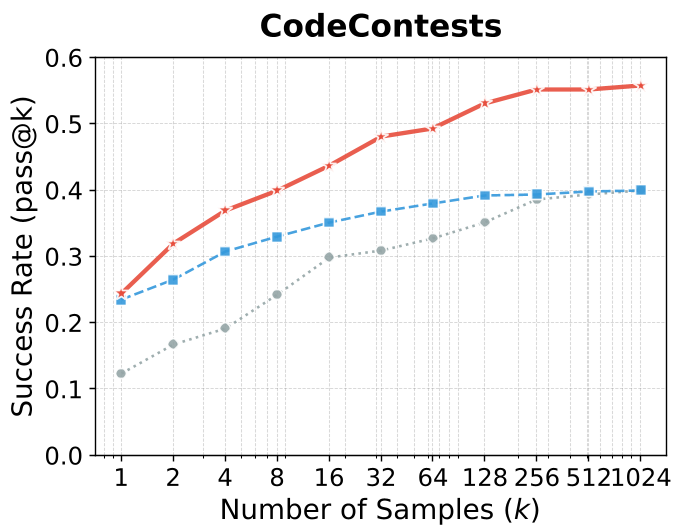 图 3:随着采样次数 k 的增加,LEAFE(红色曲线)展现出显著优于基线的探索效率。
图 3:随着采样次数 k 的增加,LEAFE(红色曲线)展现出显著优于基线的探索效率。
深度洞察:为什么回溯比盲目 Reinforce 有效?
LEAFE 的成功证明了:智能体性的核心在于对反馈的响应能力。 普通的 RL 只是给成功路径加权重,而 LEAFE 提供了“决策级”的监督。它显式地告诉模型:“当你在第 3 步遇到这种编译器报错时,你应该回滚到第 2 步重新考虑算法逻辑”。这种从失败中学习的能力,比单纯奖励成功要丰富得多。
此外,消融实验(Ablation Study)显示,LEAFE 处理 OOD(分布外)任务的健壮性更好。这是因为模型学习的是一种“通用的纠错逻辑”,而不是特定的数据集答案。
局限性与展望
尽管表现强劲,LEAFE 仍依赖于一个前提:环境必须是可重置或可回溯的。这在模拟环境(代码、游戏)中很容易,但在一些不可逆的现实物理场景中仍具挑战。
总结而言,LEAFE 为 LLM Agent 的后训练提供了一个新范式:不要只通过奖励来“对齐”答案,要通过蒸馏反思过程来“强化”智能。
关键词:LLM Agents, Rollback, Reinforcement Learning, Internalization, Pass@k