本文提出了 KARMA,一种自阿里巴巴淘宝团队的个性化搜索对齐框架。该方法通过引入“知识-行动”正则化机制,在不增加推理成本的前提下,利用 LLM 的语义生成能力指导用户兴趣向量的表示学习,实现了搜索全链路(召回、粗排、精排)的 SOTA 性能。
TL;DR
在将大语言模型(LLM)引入搜索和推荐系统时,开发者往往面临一个尴尬的局面:追求性能提升进行判别式微调,却导致 LLM 的语义空间被破坏,变成了只会死记硬背特征的“查表器”。阿里巴巴淘宝团队在本文中提出的 KARMA (Knowledge-Action Regularized Multimodal Alignment) 框架,通过引入“仅训练可见”的辅助解码任务,成功弥补了**知识(预训练语义)与行动(用户点击行为)**之间的鸿沟,在不增加任何线上推理延迟的情况下,大幅提升了搜索的泛化能力。
1. 痛点:为什么 LLM 在搜索系统中会“语义崩溃”?
传统的工业级搜索系统依赖点击率(CTR)等判别式目标进行优化。当我们尝试将 LLM 接入时,由于推理延迟限制,通常将商品历史压缩为连续的 Embedding。
然而,作者深入分析发现,在这种“Embedding-only”的微调下,LLM 出现了严重的语义崩溃(Semantic Collapse):
- 注意力汇聚(Attention Sinks):模型在处理历史序列时,注意力图会呈现出“条形码”状的异常分布,仅盯着少数几个位置(Shortcut),而忽略了商品本身的语义。
- 判别式短路:模型学会了利用 ID 类的统计捷径来区分正负样本,导致 LLM 沦为一个纯粹的 ID 编码器,失去了处理冷启动和长尾数据的通用语义能力。
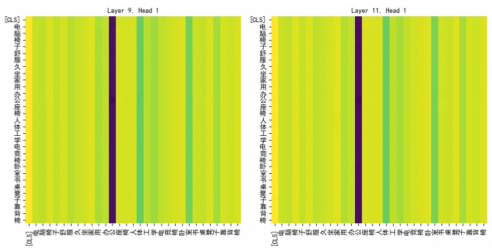 左图显示了原生训练下的异常注意力,右图展现了 KARMA 修复后的分布式语义捕捉能力。
左图显示了原生训练下的异常注意力,右图展现了 KARMA 修复后的分布式语义捕捉能力。
2. 核心方法论:知识与行动的平衡术
KARMA 的核心逻辑在于:强制让模型生成的兴趣向量(Action-aligned Embedding)具备还原出商品原貌的本领(Knowledge Decodability)。
2.1 模型架构详解
KARMA 维持了一个高效的流水线:
- Item Encoder:将多模态商品信息压缩为 Continuous Token(e_i)。
- User Decoder:基于 Qwen3 等 LLM 背景的解码器对用户历史进行建模,生成当前兴趣向量 。
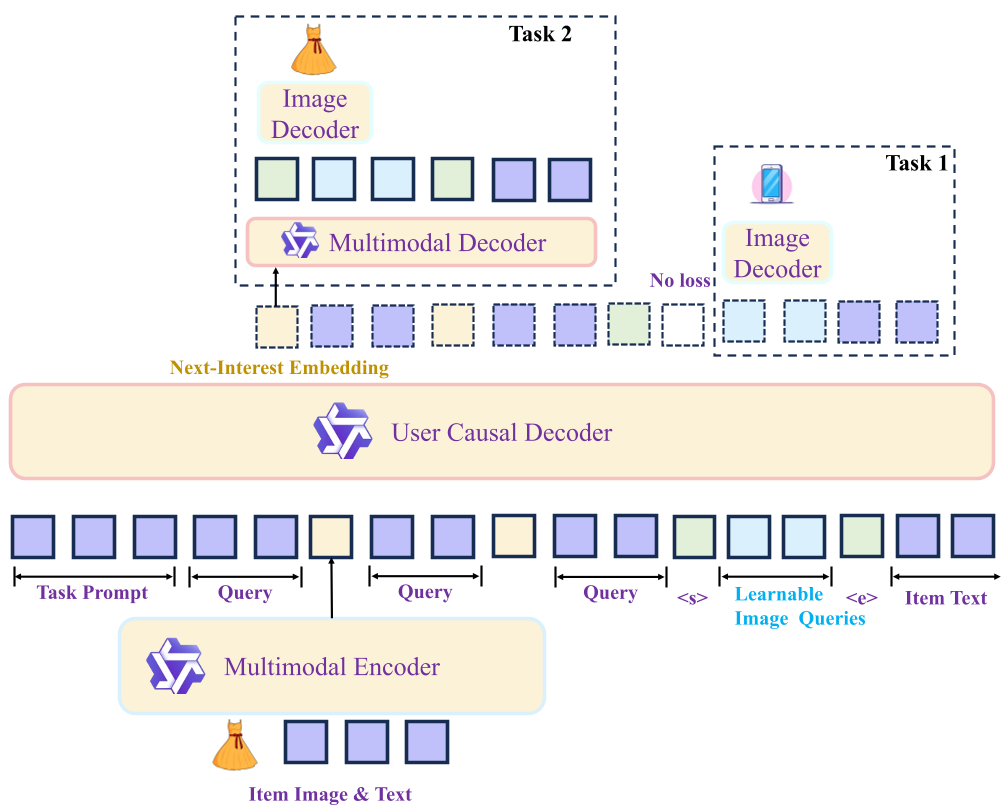
2.2 双路径解码正则化
为了防止语义崩溃,KARMA 创新性地在训练阶段挂载了两个“解码头”:
- 路径一:历史条件生成 (Task 1) 直接根据用户历史预测下一个真实商品的文本 Token。这保证了 LLM 的骨干网络不会忘记如何“听人话”。
- 路径二:向量条件重构 (Task 2) 要求仅凭最终生成的 向量,也要能把商品的文本和视觉特征还原出来。这把 变成了一个“语义瓶颈”,逼迫它必须承载足够的语义干货,而不是简单的 ID 映射。
值得注意的是:这些解码头在 Inference(线上推理)阶段是完全拆卸掉的,因此实现了真正的“训练重、推理轻”。
3. 实验发现:为什么不用 Diffusion 做检索?
在多模态实验中,作者分享了一个非常有趣的洞察:关于 趋模态(Mode-seeking)vs. 趋均值(Mean-seeking)。
作者尝试使用 Diffusion(扩散模型)直接生成检索用的兴趣向量 ,结果发现效果并不理想。
- 原因分析:Diffusion 的目标是生成尽可能真实、具体的“点”(Mode-seeking),而检索任务需要向量作为一个“中心点”(Mean-seeking),去召回周围一圈可能感兴趣的物品。
- 结论:Diffusion 更适合作为语义重构的正则项,帮助捕捉复杂的视觉分布,而非直接作为生成检索向量的引擎。
4. 落地战绩
KARMA 在淘宝庞大的流量池中展现了全方位的统治力:
- 召回(Recall):HR@5000 提升达 +2.51。
- 精排(Ranking):CTR AUC 提升 +0.25,并在 14 天的线上 A/B 测试中斩获了 0.5% 的点击增长。
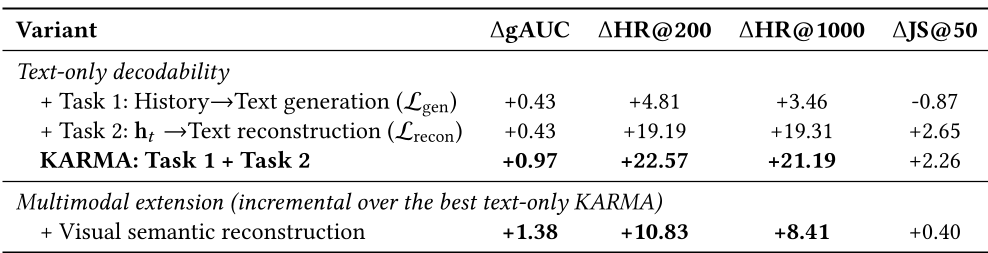
- 消融分析:如表 1 所示,单纯加入向量重构(Lrecon)就为模型带来了质的飞跃,证明了“语义瓶颈”约束的必要性。
5. 总结与启示
KARMA 的成功告诉我们,在 LLM 落地工业界的过程中,性能与泛化并非不可得兼。通过巧妙地利用 Train-only Regularizers,我们可以把训练时的强监管转化为模型深层的语义直觉,从而在不损耗推理毫秒数的前提下,释放 LLM 的知识红利。这一思路不仅适用于搜索,对于推荐系统、多模态对话等领域同样具有强大的参考价值。