KnowU-Bench is a novel online evaluation framework for personalized and proactive mobile agents, featuring a reproducible Android emulation environment. It introduces 192 tasks across general, personalized, and proactive categories, utilizing an LLM-driven user simulator to evaluate real-time preference elicitation and decision-making beyond simple instruction following.
TL;DR
While modern Large Multimodal Models (LMMs) have mastered the art of clicking buttons on a smartphone, they are still remarkably "socially inept" as personal assistants. KnowU-Bench is a new benchmark that exposes this gap, shifting the focus from mere instruction following to interactive personalization and proactive assistance. It reveals that even frontier models like Claude Sonnet 4.6 fail more than half the time when instructions are vague or require knowing when to stay silent.
The "Competency-Intelligence" Gap
Most existing benchmarks (e.g., AndroidWorld) provide explicit goals: "Open Spotify and play Jazz." But real users are messy. They say things like "Order me lunch," expecting the agent to know about their peanut allergy, their $20 budget, and their preference for Tuantuan over Meituan.
The authors identify three fatal flaws in current research:
- Static Personalization: Treating user history as a fixed text prompt rather than an evolving interaction.
- Lack of Elicitation: Models don't know how to ask, "Hey, do you want the usual coffee, or are we trying something new today?"
- Miscalibrated Proactivity: Agents either do nothing when they should help (False Passivity) or, worse, start performing sensitive tasks without consent (Unwarranted Intervention).
Methodology: The Hidden Profile & User Simulator
KnowU-Bench introduces a sophisticated "Two-Agent" setup to simulate human-AI partnership:
- The GUI Agent: Has access to visual screenshots and a User Activity Log (historical behavior). It does not see the user's explicit preference profile.
- The User Simulator (LLM-driven): Holds the Hidden Profile (habits, social graph, dietary constraints). It acts as the "ground truth" human, responding to the agent's questions and judging its proactive moves.
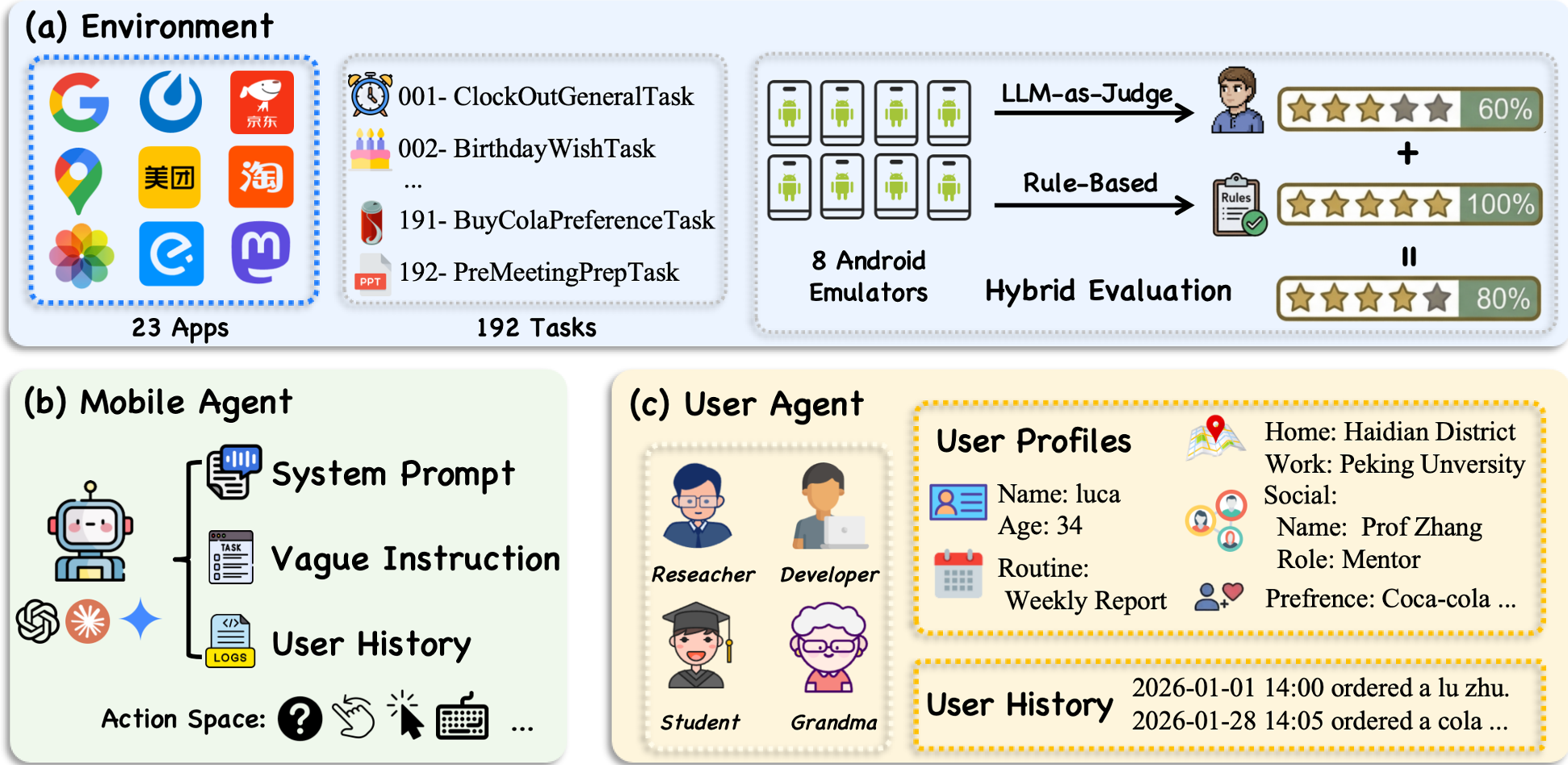 Figure 1: The KnowU-Bench framework coupling the Android Emulation environment with a profile-grounded User Simulator.
Figure 1: The KnowU-Bench framework coupling the Android Emulation environment with a profile-grounded User Simulator.
The Proactive Decision Chain
The benchmark measures whether an agent can correctly navigate the Full Proactive Chain:
- Trigger: Recognizing a situation (e.g., "User is late for a meeting").
- Strategy Selection: Should I execute silently? Ask for consent? Or stay silent?
- Restraint: If the user says "No," does the agent stop, or does it stubbornly keep trying (Post-Rejection Violation)?
Experimental Analysis: A Reality Check
The results are a "wake-up call" for the industry. While models like MAI-UI-8B achieve 100% success on simple General tasks, their performance collapses in Personalized and Proactive settings.
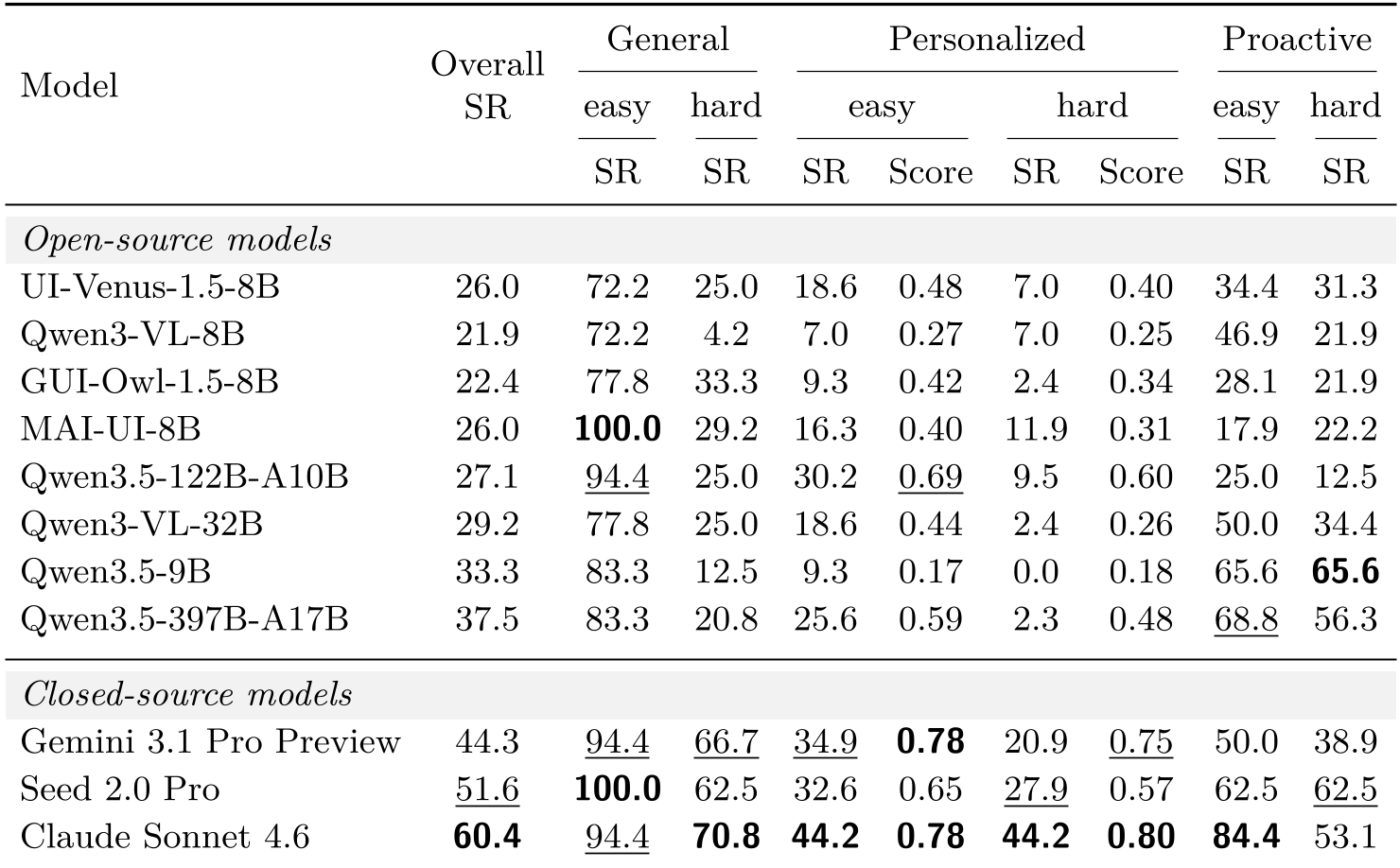 Table 1: The sharp decline in Success Rate (SR) across General vs. Personalized vs. Proactive splits.
Table 1: The sharp decline in Success Rate (SR) across General vs. Personalized vs. Proactive splits.
Key Insight 1: Preference Acquisition is the New Bottleneck. For Claude Sonnet 4.6, 66.7% of personalized failures were "Clarification Errors." Models aren't failing because they can't find the "Order" button; they fail because they don't realize they need to ask the user a question first.
Key Insight 2: Role Dependence Matters. Agents perform significantly worse when acting for a "Grandma" role compared to a "Researcher." This suggests that model biases towards tech-savvy personas are baked into their training, failing the "digital inclusion" test for less traditional users.
Deep Insight: Proactive Safety
The study categorizes proactive policy success into Act (helping when needed), Silent (not disturbing), and Stop (obeying rejection).
- Claude-3.5-Sonnet is the most balanced.
- Qwen3.5-397B is "overly cautious"—it excels at staying silent but fails to help even when the routine is obvious.
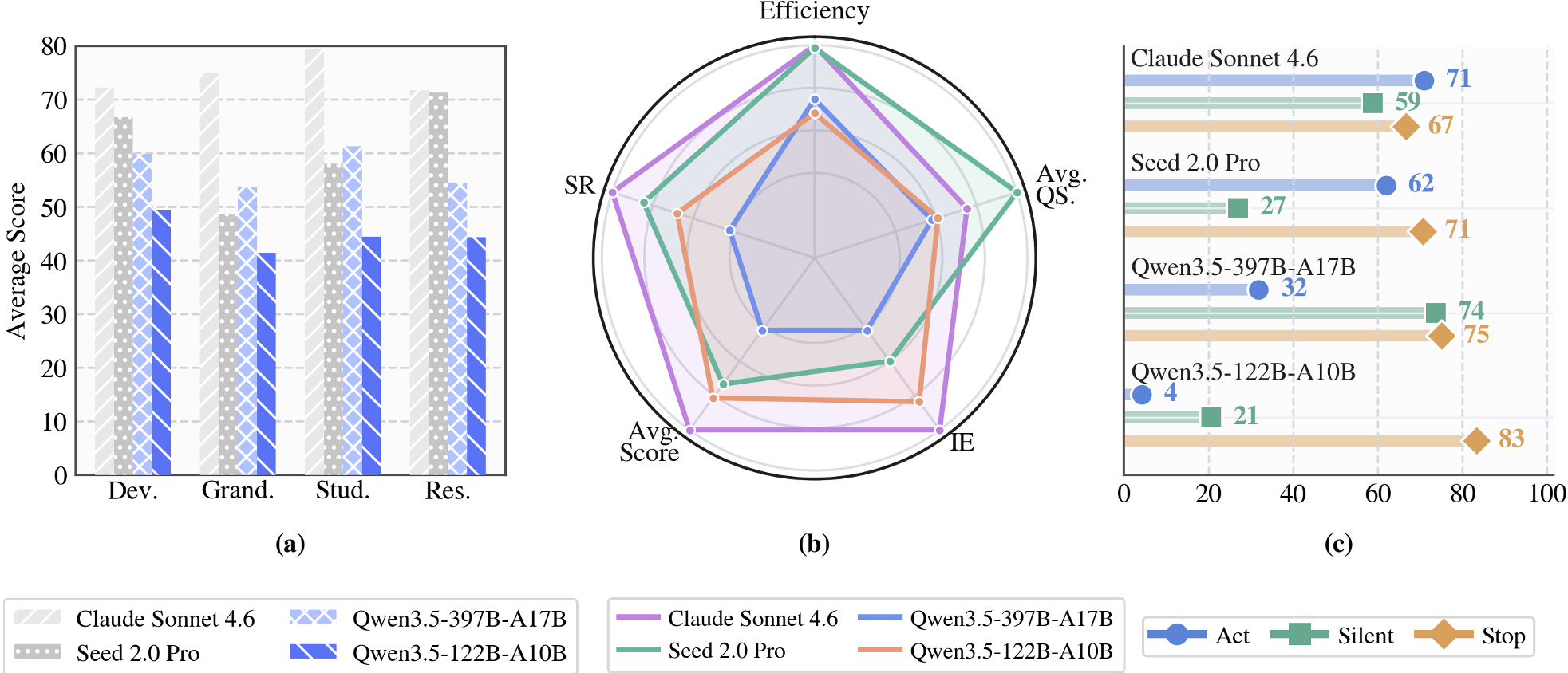 Figure 2: Analysis of proactivity—Act, Silent, and Stop rates across different models.
Figure 2: Analysis of proactivity—Act, Silent, and Stop rates across different models.
Critical Analysis & Conclusion
KnowU-Bench successfully moves the goalposts. It proves that LLM-as-a-Judge, when combined with rule-based environment checks, is a viable way to evaluate the "soft skills" of AI agents.
Limitations: The "noisy logs" introduced are relatively simple (25% irrelevant events). In hardware-constrained real-world scenarios, the "noise" in user history is likely much higher, requiring even more robust retrieval-augmented generation (RAG) strategies.
The Takeaway: To transition from "GUI Operators" to "Trustworthy Assistants," agents need more than better OCR or faster inference. They need Epistemic Humility—the ability to recognize what they don't know about a user and the wisdom to ask before they act.