本文提出了 LensWalk,一个赋予大语言模型(LLM)主动视觉观察能力的智能体框架。通过构建“推理-规划-观察”的闭环,该方法在 LVBench 和 Video-MME 等长视频基准测试中,将 o3 等强基线模型的准确率提升了 5% 以上。
TL;DR
在视频理解领域,目前主流的方法是像“灌药”一样把抽好的帧一股脑塞给模型。然而,真正的智能应该像人类看电影:先大致扫一眼(Scan),发现疑点后盯着细节看(Focus),最后把前后几个关键镜头串起来验证(Stitch)。LensWalk 正是将这种“有目的的观察”引入了 LLM Agent,通过“推理-规划-观察”的动态循环,在不微调的情况下让 o3, GPT-4o 等模型在长视频任务上实现了惊人的性能飞跃。
痛点深挖:为什么静态采样是视频理解的“紧箍咒”?
传统的视频理解 pipeline(如图 1a/1b)存在一个致命的感知-推理脱节:
- 资源浪费与稀释:为了塞进 Context Window,模型必须进行稀疏采样。这导致关键动作(如凶手在第 40 分钟的一个眼神)可能被漏掉,或者被大量无关的背景帧淹没。
- 无法反悔的决策:由于观察在推理前已经完成,如果模型在吃到第 10 步推理时发现需要确认第 5 分钟的一个细节,它无法通过“回头看”来修正。
- 静态表征的局限性:预生成的 Caption 或 Embedding 屏蔽了 raw video 中的原始证据,导致信息在多层转化中严重丢失。
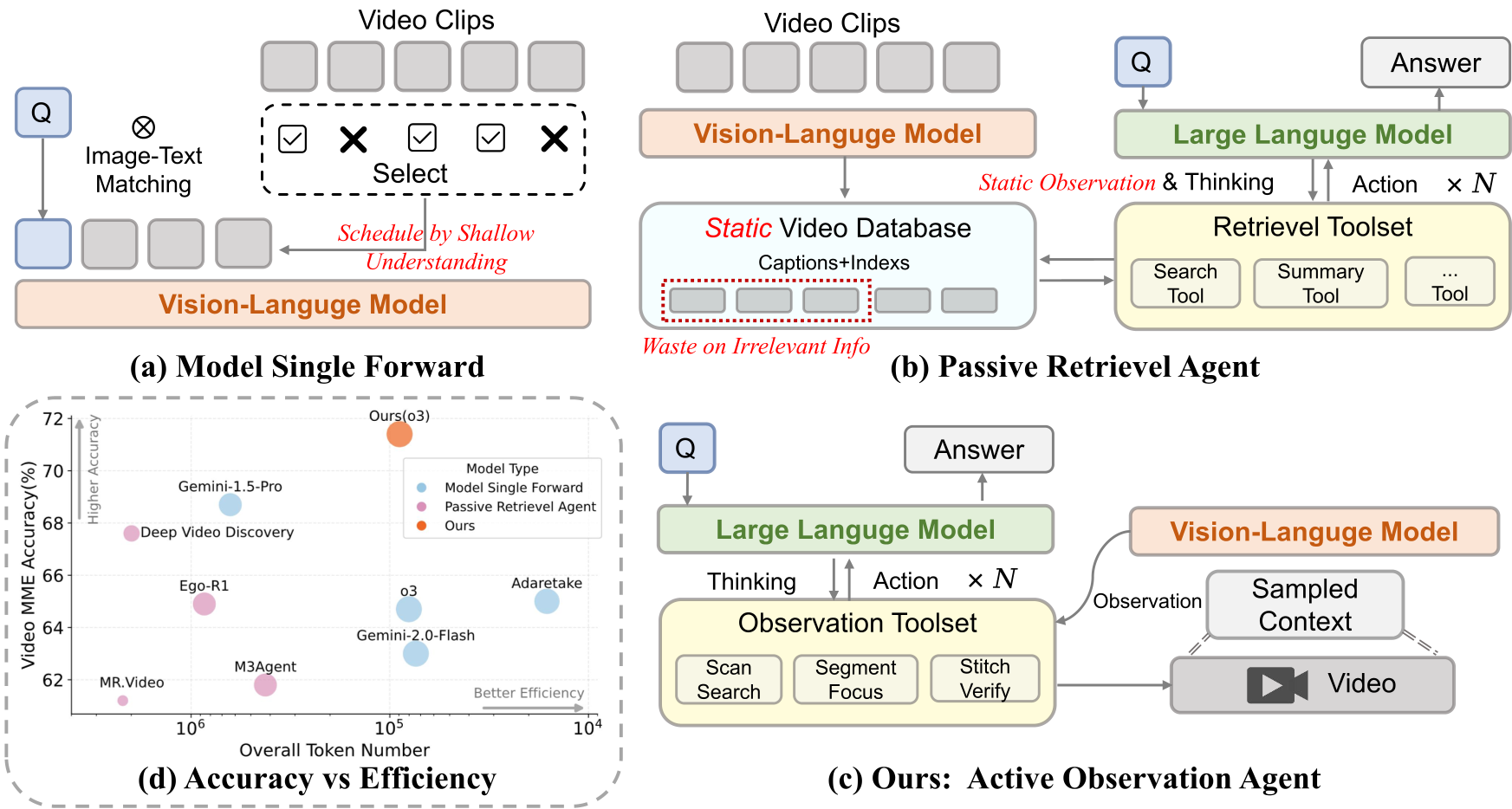 图 1:LensWalk 与传统单次前向、基于检索的 Agent 之对比。LensWalk 的核心在于“自调节观察预算”。
图 1:LensWalk 与传统单次前向、基于检索的 Agent 之对比。LensWalk 的核心在于“自调节观察预算”。
Methodology:LensWalk 的三大核心利器
1. 理由驱动的观察规划 (Reason-Scheduled Observation)
LensWalk 的推理器 不仅仅给答案,它通过生成包含四元组 的 Plan 来控制观察。它决定了:
- Where:看哪个时间段?
- How Dense:采样的 FPS 是多少?
- Tool:用哪种观察方式?
2. 多粒度观察工具包 (Multi-Granularity Toolkit)
作者精心设计了三种符合人类认知的工具:
- Scan Search:大规模并行扫描,用于定位。把视频切成小份,快速查找目标出现的线索。
- Segment Focus:在锁定的区间内高 FPS 抽帧,提取微小的动作或文字细节。
- Stitched Verify:最性感的工具。它能把非连续的片段(如开头和结局)拼在一起给 VLM 看。这对于验证因果关系(如“谁拿走了水杯”)至关重要。
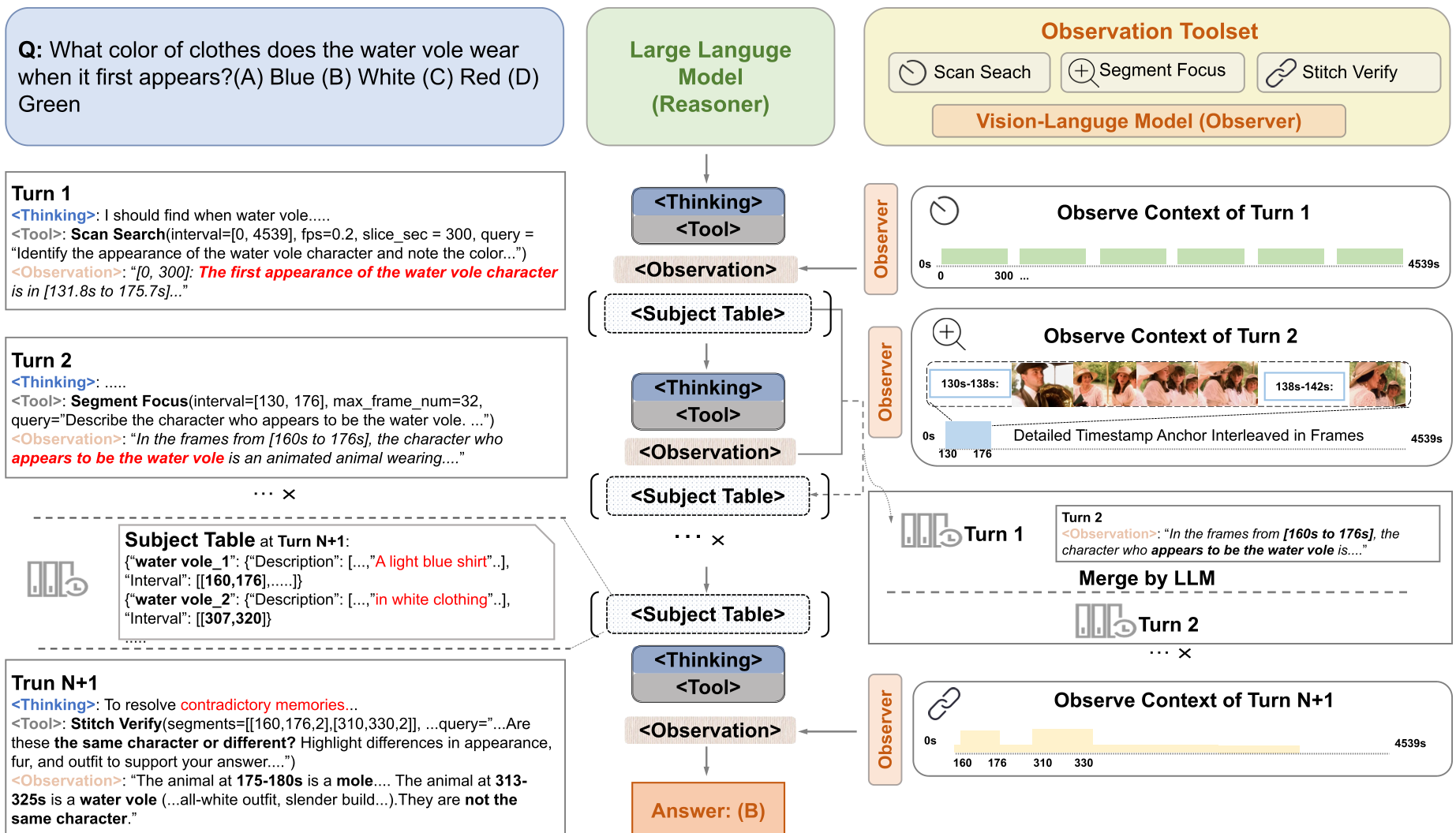 图 2:LensWalk 在真实场景下的运行轨迹。注意它如何通过多次工具调用修正最初将“鼹鼠”误认为“水豚”的错误。
图 2:LensWalk 在真实场景下的运行轨迹。注意它如何通过多次工具调用修正最初将“鼹鼠”误认为“水豚”的错误。
3. 长程推理的“地基”:记忆与锚点
为了防止 Agent 在多轮对话中“迷失”,LensWalk 引入了:
- Timestamp Anchors:在观察文本中嵌入精准时间戳。
- Subject Memory Table:像一张全局角色表,记录视频中出现的实体及其关系,避免反复重读历史。
实验选录:SOTA 级的表现与“免费的午餐”
LensWalk 展现了强大的适配性。即便使用 GPT-4.1 或 Qwen2.5-VL 这种已然很强的模型作为底座,LensWalk 依然能榨取更多性能。
| Method | Video-MME Long (Acc) | LVBench (Acc) | | :--- | :---: | :---: | | o3 (Base) | 64.7 | 57.1 | | LensWalk (o3) | 71.4 (+6.7) | 68.6 (+11.5) | | DVD (Previous SOTA) | 67.3 | 74.2 |
注意:虽然 DVD 在 LVBench 略高,但它需要数小时的离线预处理,而 LensWalk 是在线的、Plug-and-play 的。
观察偏好的涌现
更有趣的是,LensWalk 展现出了“感知成本意识”。分析发现(见图 4):
- 对于简单问题,Agent 直接调用 Direct Inquiry,省去抽帧成本。
- 面对复杂推理,Agent 会展现出 Progressive Zoom-in(先全局扫,再局部盯)或 Strategic Reflection(此路不通,换个地方重扫)。
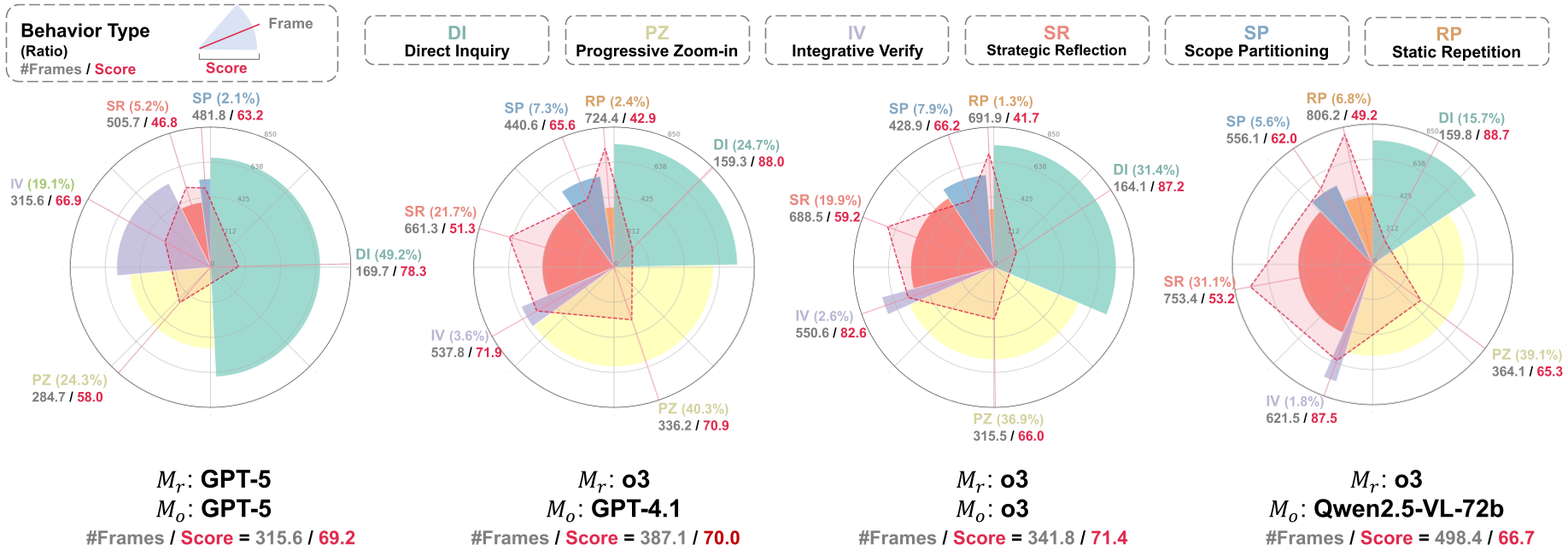 图 4:Agent 的行为模式分析。难度越大的题目,其观察轨迹越长且越复杂。
图 4:Agent 的行为模式分析。难度越大的题目,其观察轨迹越长且越复杂。
深度洞察与总结
LensWalk 的成功揭示了一个深刻的本质:视频理解不仅仅是特征提取,更是一种主动的认知策略。
局限性分析: 虽然表现强劲,但 LensWalk 仍受限于底座推理器的效能。如果 Reasoner 的逻辑能力不足(如文中提到的部分开源模型),它可能陷入 Static Repetition(原地打转)或 Premature Conclusion(过早下结论)的怪圈。
未来展望: 随着原生多模态推理模型(如 o3)的进化,LensWalk 这种将感知权交给推理大脑的架构,将成为处理超长视频任务、甚至是具身智能中“动态视觉寻证”的标准范式。未来的 AI 不再只是被动接受像素,而是能学会“如何为了思考而去观察”。