Lighthouse Attention is a training-only subquadratic attention mechanism that uses a symmetrical hierarchical selection process (pooling Q, K, and V) to handle extreme sequence lengths. It wraps around standard Scaled Dot-Product Attention (SDPA) and achieves SOTA training efficiency, matching or beating full-attention models after a short "recovery" phase while being significantly faster at contexts up to 1M tokens.
TL;DR
Lighthouse Attention is a novel training-time algorithm designed to break the quadratic barrier of Transformer attention without sacrificing model quality. By pooling Queries, Keys, and Values symmetrically and using a discrete "Top-K" selection, it speeds up long-context training (up to 1M tokens) by nearly 2x. Most importantly, it introduces a "Recovery" phase where the model is switched back to full attention, proving that sparse training doesn't have to break inference.
Problem & Motivation: The Saliency Paradox
As LLMs move toward context windows of 128K, 1M, and beyond, we hit a hardware wall. Standard attention (SDPA) scales quadratically (). Current sparse solutions generally fall into two traps:
- Asymmetry: They compress Keys and Values but leave Queries dense. This makes sense for inference (one query at a time) but is inefficient during training where all queries are known.
- Kernel Entanglement: Most sparse methods require custom CUDA kernels that are hard to maintain and don't benefit from the rapid optimizations of stock FlashAttention.
The authors' insight is simple: Queries are as redundant as Keys. If we compress both, we can reduce the problem to "thick" attention over a much smaller, gathered sub-sequence.
Methodology: The Four-Stage Pipeline
Lighthouse wraps the attention layer in a 4-stage process that leaves the core kernel untouched:
- Pyramid Pooling: Q, K, and V are average-pooled into multiple resolution levels (e.g., every 2, 4, or 8 tokens).
- Hierarchical Selection: A parameter-free scorer (using norms) identifies the most "important" entries across all levels. A custom Chunked-Bitonic Top-K kernel handles this selection efficiently on GPUs.
- Gather & FlashAttention: The selected entries are packed into a single, contiguous sub-sequence. Crucially, because this sub-sequence is dense, we can use unmodified FlashAttention.
- Scatter-Back: The result is redistributed to the original sequence positions using a deterministic scatter kernel.
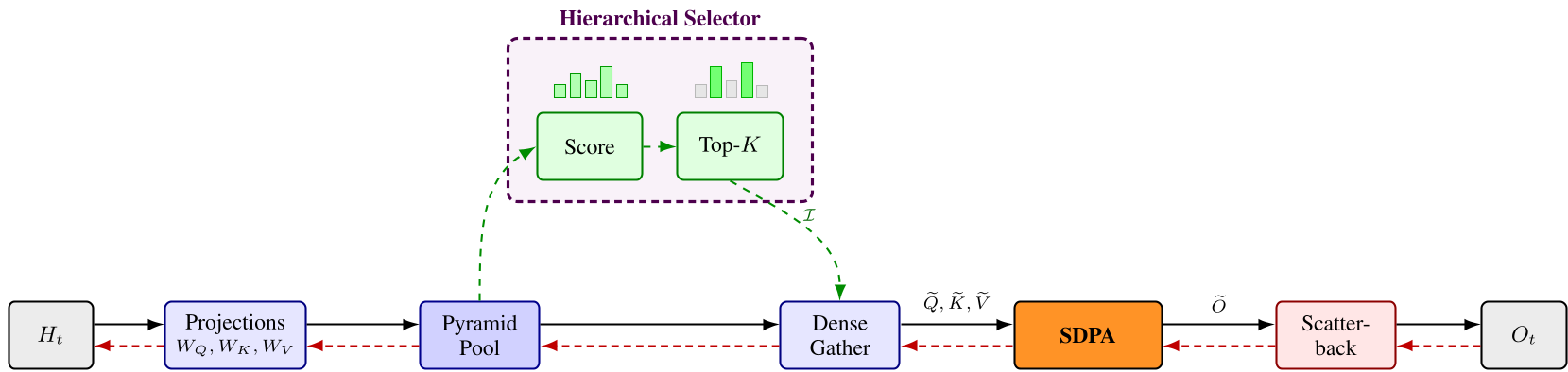
Why No Differentiable Selection?
Lighthouse does not use Straight-Through Estimators (STE) or Gumbel-Softmax. The selection is discrete and non-differentiable. The weights learn to produce values that are useful when selected, rather than learning how to "game" a scorer. This avoids the common optimization instability seen in learned sparse models.
Experiments: Faster Training, Better Recovery
The authors tested Lighthouse on B200 GPUs at various context lengths.
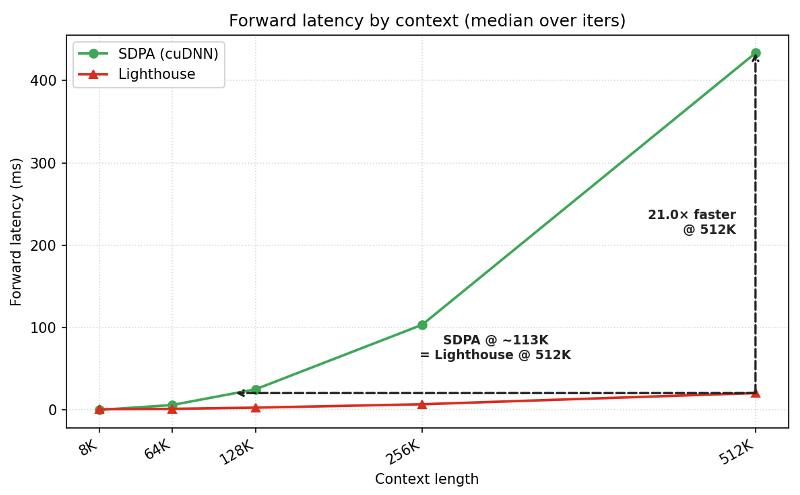
1. Scaling Performance
The performance gap widens as sequences get longer. At 512K tokens, Lighthouse provides a staggering 21x speedup in the forward pass. This efficiency allows for training on contexts that would otherwise lead to Out-Of-Memory (OOM) errors on high-end hardware.
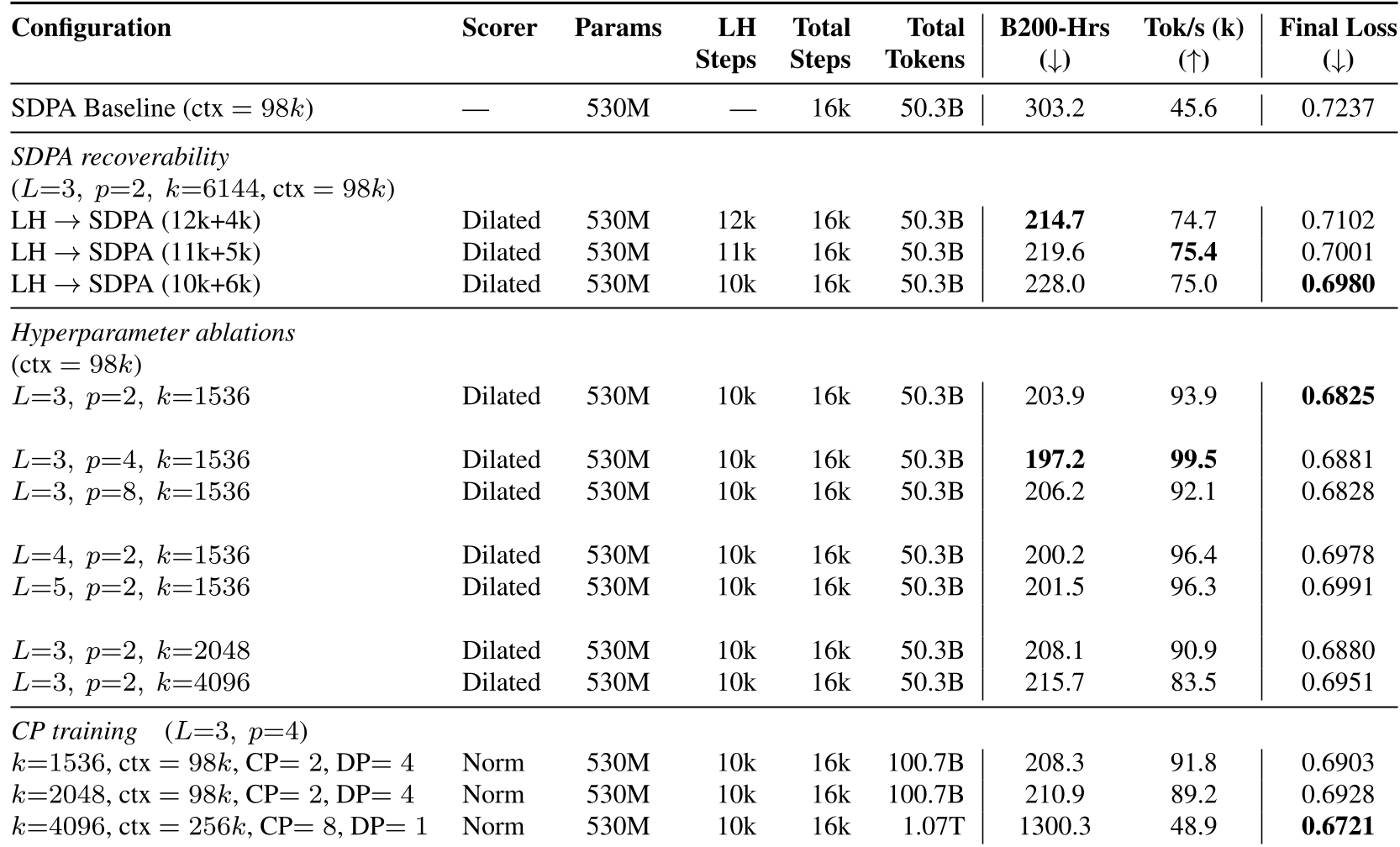
2. The SDPA Recovery Test
A major contribution is the Two-Stage Recipe. After pre-training for ~10k steps with Lighthouse (sparse), the model is switched to full SDPA (dense) for the final ~6k steps.
- Result: The "recovered" models didn't just match the baseline; they often surpassed it in terms of validation loss (0.6980 vs. 0.7237).
- Retrieval: In "Needle-in-a-Haystack" tests, the recovered models showed retrieval capabilities on par with models trained entirely with dense attention.
Critical Analysis & Takeaways
Lighthouse Attention proves that sparsity is a bridge, not a permanent modification.
Pros:
- Kernel Agnostic: Allows researchers to immediately benefit from FlashAttention-3/4.
- Symmetric Efficiency: Compressing Queries significantly reduces FLOPs during the training phase.
- Superior Regularization: Surprisingly, smaller budgets () resulted in lower loss, suggesting the hierarchical selection acts as a useful bottleneck.
Limitations:
- Autoregressive Decoding: The symmetric pooling assumes Queries are known in advance, making this specifically a pre-training optimization rather than a zero-shot inference speedup.
- Complexity: While is fixed, the complexity is sub-quadratic, not strictly linear.
Future Outlook: The multi-scale pyramid approach is naturally suited for multimodal tasks. We should expect to see Lighthouse-style selection applied to vision and audio, where spatial/temporal redundancy is even higher than in text.