LongCoT is a new, large-scale benchmark containing 2,500 expert-designed problems across five domains (Math, Chemistry, CS, Chess, and Logic) designed to measure long-horizon Chain-of-Thought (CoT) reasoning. Frontier models like GPT-5.2 and Gemini 3 Pro achieve less than 10% accuracy, highlighting a massive gap in their ability to maintain coherence over reasoning traces spanning 50K to 128K tokens.
TL;DR
As LLMs move towards autonomous agency, their ability to produce reliable, extremely long "reasoning traces" is the new bottleneck. LongCoT is a benchmark of 2,500 problems that forces models to generate up to 128,000 tokens of Chain-of-Thought (CoT) to reach a single verifiable answer. The result? Even GPT-5.2 hits a ceiling at 9.8% accuracy, revealing that current AI is remarkably fragile when it has to think for a long time.
Background Positioning
We have passed the era where "Hard Math" was the only test. While benchmarks like FrontierMath test esoteric knowledge, and LongBench tests reading long documents, LongCoT tests the "internal stamina" of a model. It sits at the intersection of agentic planning and long-output generation, proving that a model's ability to reason degrades not because of a lack of knowledge, but because of a lack of coherence over time.
The Motivation: Why Long-Horizon Reasoning is Different
Standard reasoning benchmarks usually require a few thousand tokens. In these "shallow" horizons, a model can get lucky or brute-force a path. However, in real-world science or engineering, a task might involve a dependency graph of 50+ steps.
The authors identify four critical abilities that fail at scale:
- State Management: Keeping track of variables defined 40,000 tokens ago.
- Credit Assignment: Identifying exactly which step in a 100-step process caused a final error.
- Backtracking: Recognizing a dead-end and returning to a "save point" in the reasoning chain.
- Error Propagation: In a long chain, a 1% error rate per step leads to a nearly 0% success rate at the end.
Methodology: Scalable Graph-Based Complexity
The core innovation of LongCoT is its use of Compositional and Procedural templates.
- Compositional (Explicit): These are Directed Acyclic Graphs (DAGs) where the output of "Problem A" is the input to "Problem B."
- Procedural (Implicit): These involve search spaces like Chess puzzles or Sudoku, where the "graph" is hidden within rules and constraints.
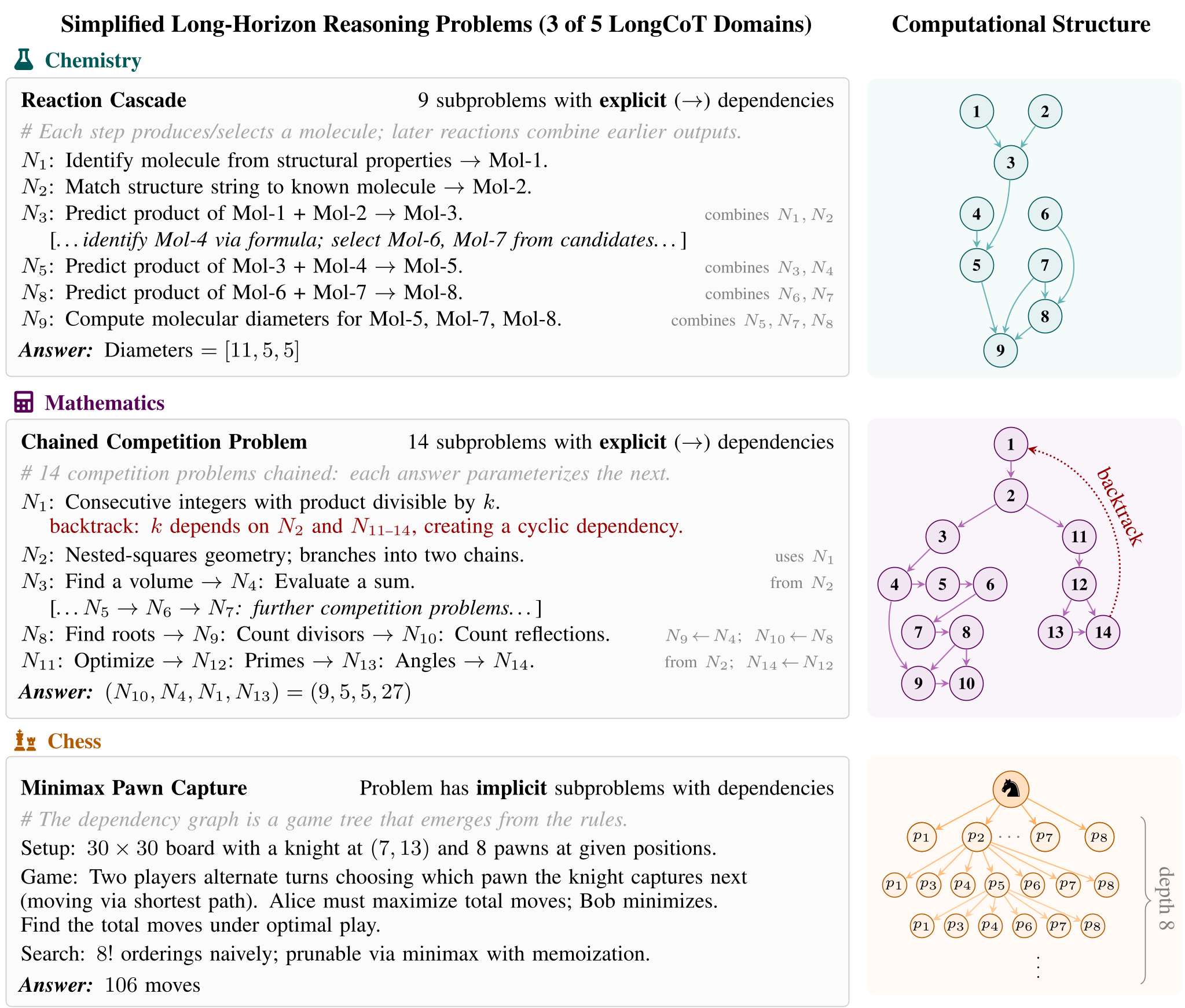 Figure 1: LongCoT problems require traversing a computational dependency graph in a long CoT, involving search trees, cyclic graphs, and execution traces.
Figure 1: LongCoT problems require traversing a computational dependency graph in a long CoT, involving search trees, cyclic graphs, and execution traces.
Crucially, the authors ensured that each individual node is easy. If you provide a model with just one step, it succeeds. The failure only occurs when the model has to link dozens of these "easy" steps together in one go.
Experiments: The Great Convergence at Zero
The evaluation of frontier models (GPT-5.2, Gemini 3 Pro, Claude 4.5) on LongCoT is a "bloodbath" for current SOTA:
- GPT-5.2: 9.83% accuracy (utilizing ~62K tokens/problem).
- Gemini 3 Pro: 6.08%.
- Open-Source (DeepSeek V3, Kimi K2): Near 0% on the main benchmark, though they show life on the "LongCoT-mini" subset (~8%).
Accuracy vs. Horizon Length
As the number of nodes in the problem graph increases, performance doesn't just dip—it dives. The data shows that after 15-20 reasoning steps, the probability of the model maintaining a correct state approaches zero.
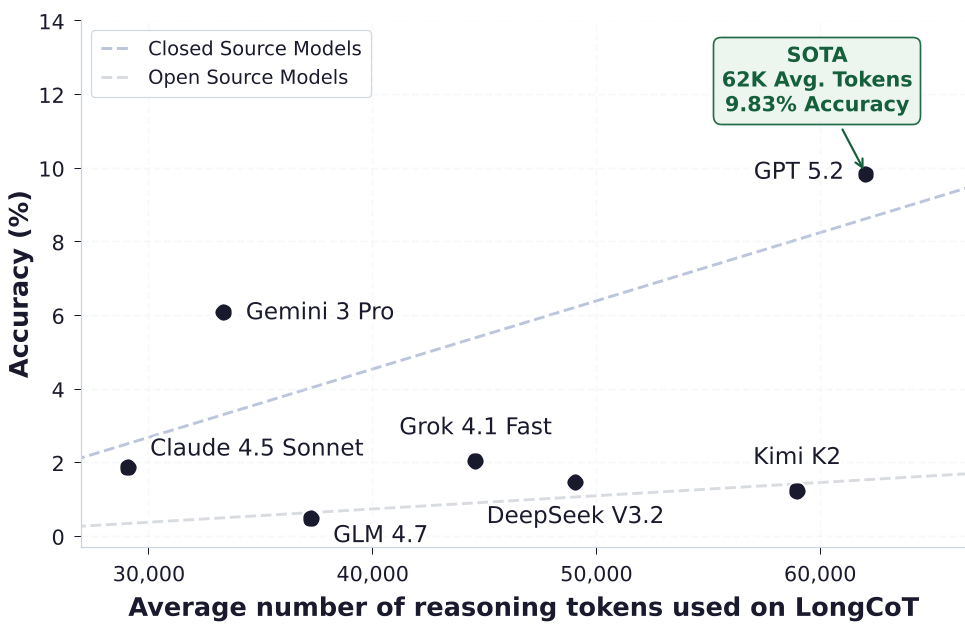 Figure 2: Performance scales with token usage, but even at 100K tokens, accuracy remains below 10%.
Figure 2: Performance scales with token usage, but even at 100K tokens, accuracy remains below 10%.
Critical Analysis: Why Do They Fail?
The authors performed a qualitative "Reasoning Trace Analysis." By classifying chunks of reasoning into Setup, Planning, Solving, and Backtracking, they found:
- Inefficient Early Planning: Models commit to a path in the first 1,000 tokens and refuse to change it 50,000 tokens later.
- Lack of Backtracking: Incorrect traces showed twice as much "looping" or "stuck" behavior compared to successful traces.
- Context Exhaustion: Models often "give up" or start guessing as they approach their output token limit (e.g., 128K).
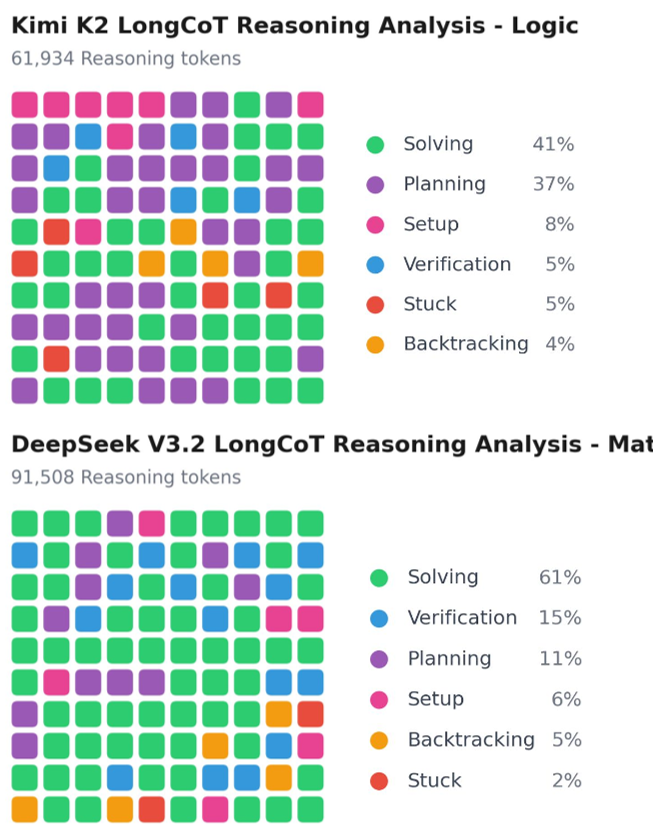 Figure 3: Visualization of reasoning traces. Green represents "Solving," but the red/orange "Stuck" and "Backtracking" segments dominate in failures.
Figure 3: Visualization of reasoning traces. Green represents "Solving," but the red/orange "Stuck" and "Backtracking" segments dominate in failures.
Professional Conclusion
LongCoT proves that System 2 thinking in LLMs is still in its infancy. Scaling context windows is not enough; we need to scale "Reasoning Stability."
Takeaway for the Field: The next leap in AI won't just come from more parameters, but from architectural or training breakthroughs (like Reinforcement Learning for CoT) that allow a model to "debug" its own thoughts over indefinitely long horizons. Until then, autonomous agents will remain limited to shallow, short-burst tasks.