M2RNN (Matrix-to-Matrix RNN) is a novel non-linear RNN architecture designed for scalable language modeling, featuring matrix-valued hidden states and expressive non-linear transitions. It achieves perfect state-tracking generalization and outperforms state-of-the-art hybrid models like Gated DeltaNet and Mamba-2 by 0.4–0.5 perplexity points in hybrid settings.
TL;DR
M2RNN resurrects non-linear RNNs for the LLM era by replacing the classic vector hidden state with a high-capacity matrix. By combining non-linear state transitions (to solve complex logic) with outer-product expansion (to store massive context), M2RNN outperforms Mamba-2 and Gated DeltaNet in both efficiency and accuracy, particularly in "hard" tasks like entity tracking and code execution.
The Motivation: Why Linear RNNs and Transformers Fail at Logic
The AI community has recently flocked to Linear RNNs (SSMs) like Mamba for their efficiency. However, there is a hidden cost: Expressivity.
Theoretical analysis shows that Transformers and Linear RNNs (with diagonal transitions) reside in the TC0 complexity class. This means they are fundamentally incapable of solving certain state-tracking problems, such as evaluating complex code or tracking nested entities, which require NC1 complexity.
Non-linear RNNs (like LSTMs) have the required complexity but were abandoned because:
- Tiny States: Their vector states are too small to compete with the KV-caches of Transformers.
- Hardware Unfriendly: Non-linearities prevent the use of "Parallel Scan" algorithms, making them slow to train on GPUs.
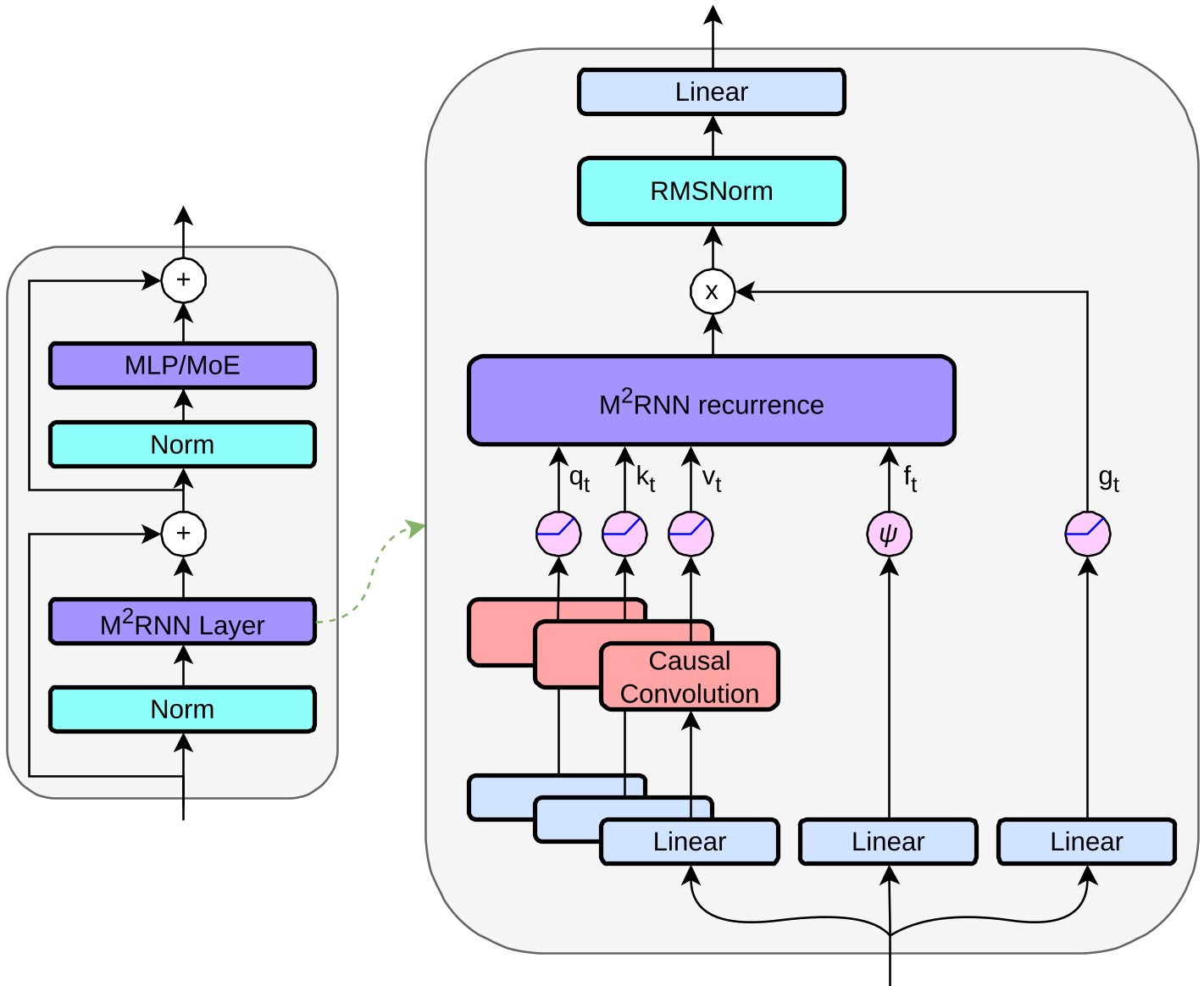
The Core Innovation: Matrix-to-Matrix Recurrence
M2RNN solves this by upgrading the hidden state to a matrix .
1. The Recurrence Equation
Instead of a simple vector addition, M2RNN uses a non-linearity wrapped around a matrix-valued update:
Here, is an outer product that allows the model to "write" new information into the matrix state efficiently, mimicking the high capacity of Linear Attention while maintaining a non-linear transition.
2. Specialized Hardware Kernels
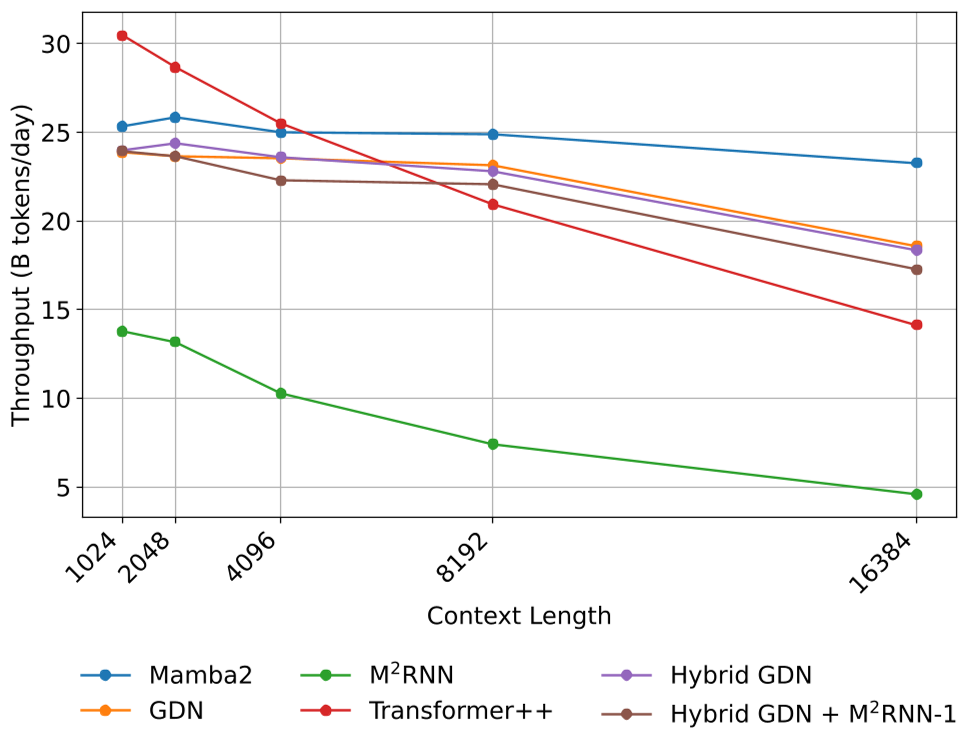
The authors address training inefficiency by noticing that since the state is a matrix, the recurrence update becomes a GEMM (General Matrix Multiply). Unlike vector RNNs that waste 75% of FLOPs on padding to keep Tensor Cores busy, M2RNN's matrix dimensions naturally fit the hardware (e.g., ), allowing for peak GPU utilization even with small batch sizes.
Experiments: Scaling to 7B MoE
The researchers tested M2RNN at the 410M (Dense) and 7B (MoE) scales.
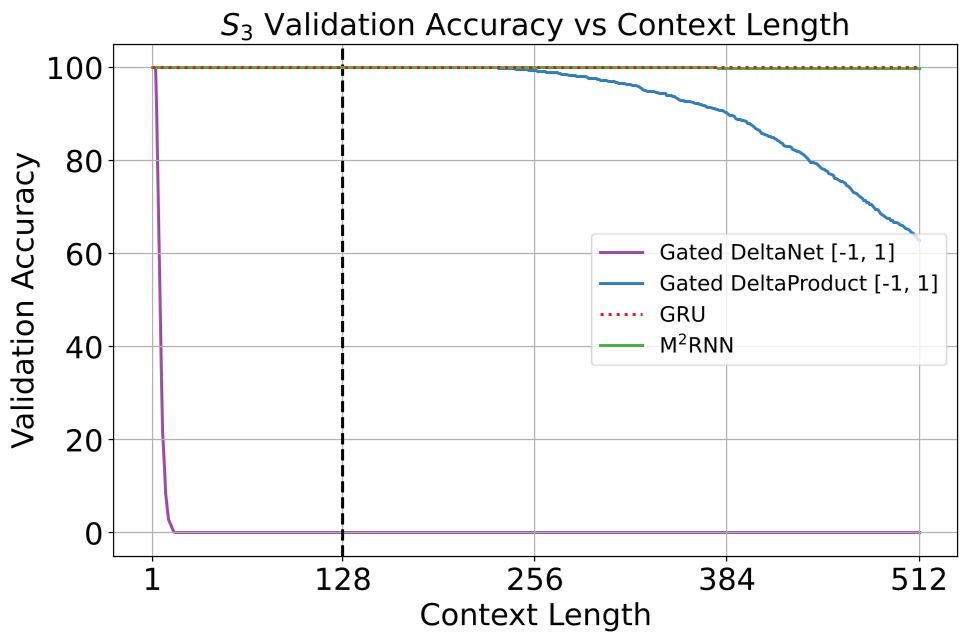
- Logic Master: In the S3 permutation task (a proxy for hard logic), M2RNN achieved perfect generalization to sequence lengths 4x longer than seen in training, whereas linear models failed completely.
- The Power of Hybrids: While a pure M2RNN is strong, it shines brightest as a Hybrid. Interleaving M2RNN layers with Attention and Linear RNNs yields the best results.
Long-Context Generalization
On LongBench, adding even a single M2RNN layer to a Gated DeltaNet hybrid resulted in a massive 8-point jump in accuracy. This suggests that M2RNN layers act as "logic anchors" in a sea of linear retrieval layers.
Conclusion: A New Building Block for LLMs
For years, we believed we had to choose between the expressivity of non-linear RNNs and the scalability of linear models. M2RNN proves this is a false dichotomy. By simply expanding the state from a vector to a matrix and optimizing the GPU kernels, we can build models that are both hardware-efficient and logically rigorous.
Key Limit: Non-linear layers are still more expensive than linear ones. However, as the authors show, you don't need many of them—one M2RNN layer every 8-16 layers might be the "secret sauce" for the next generation of reasoning-heavy models.