The paper introduces SAGE-GRPO (Stable Alignment via Exploration), a novel reinforcement learning framework designed to align video generation models with human preferences. By formulating video RL as a manifold-constrained exploration problem, it achieves SOTA alignment results on HunyuanVideo1.5, significantly improving visual quality and temporal consistency.
TL;DR
Post-training alignment for video generation has long been the "wild west" of Generative AI, plagued by temporal jitters and artifacts. SAGE-GRPO (Stable Alignment via Exploration) tames this by ensuring that reinforcement learning exploration never leaves the "safe zone" of the pre-trained video manifold. By introducing a curvature-corrected SDE and a dual-anchor trust region, it achieves massive gains in motion quality and semantic consistency.
The "Off-Manifold" Problem: Why Video RL Fails
In Large Language Models (LLMs), GRPO is a proven tool for alignment. However, when applied to video via Flow Matching models, a critical failure occurs. To explore different solutions, researchers convert deterministic ODE samplers into stochastic SDE samplers.
The problem? Previous methods (like FlowGRPO) use first-order approximations for noise injection. In the high-dimensional space of video, this "linear" noise is too blunt—it pushes the generated frames far away from the valid data manifold, resulting in "noisy" rollouts that confuse the reward model. If the samples are bad, the reward is meaningless, and the model never learns.
Micro-Level: Precision Noise Injection
SAGE-GRPO fixes this at the mathematical foundation. Instead of a simple area-based variance approximation, the authors derive a Precise Manifold-Aware SDE.
The Logarithmic Correction
By integrating diffusion coefficients over each step and adding a logarithmic curvature correction , the exploration noise stays tangent to the flow trajectory. This keeps the "exploration ellipsoid" tight and manifold-consistent.
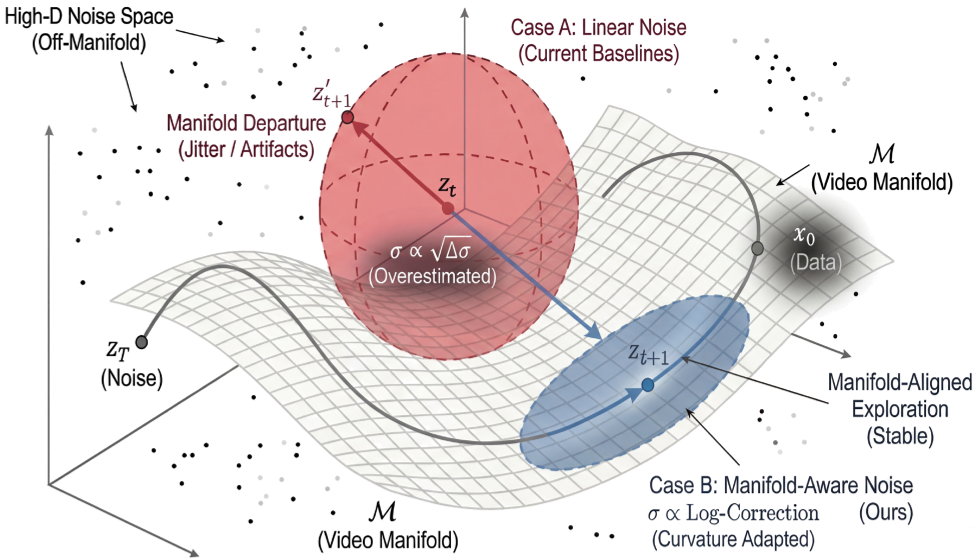 Figure: Note how the blue ellipsoid (SAGE) stays aligned with the manifold , while the red sphere (FlowGRPO) drifts into "illegal" data space.
Figure: Note how the blue ellipsoid (SAGE) stays aligned with the manifold , while the red sphere (FlowGRPO) drifts into "illegal" data space.
Gradient Norm Equalization
Diffusion models suffer from a massive gradient imbalance: gradients vanish at high noise () and explode at low noise (). SAGE-GRPO introduces a Gradient Norm Equalizer that normalizes optimization pressure, ensuring that structural updates (high noise) and textural details (low noise) are learned with equal priority.
Macro-Level: The Dual Trust Region
Even with perfect noise, a model can "drift" over thousands of updates, eventually losing its ability to generate realistic videos (the stability-plasticity gap).
SAGE-GRPO implements a Position-Velocity Controller strategy:
- Velocity Control (Step-wise KL): Limits how much the policy can change in a single step, ensuring smooth transitions.
- Position Control (Periodical Moving Anchor): Every steps, a reference anchor is updated. This prevents the model from wandering too far from the initial manifold while allowing enough "plasticity" to maximize the reward.
Experimental Results: Setting a New Standard
The researchers tested SAGE-GRPO on the powerful HunyuanVideo1.5 model. Compared to current baselines like DanceGRPO and FlowGRPO, SAGE-GRPO showed dominant performance across the board.
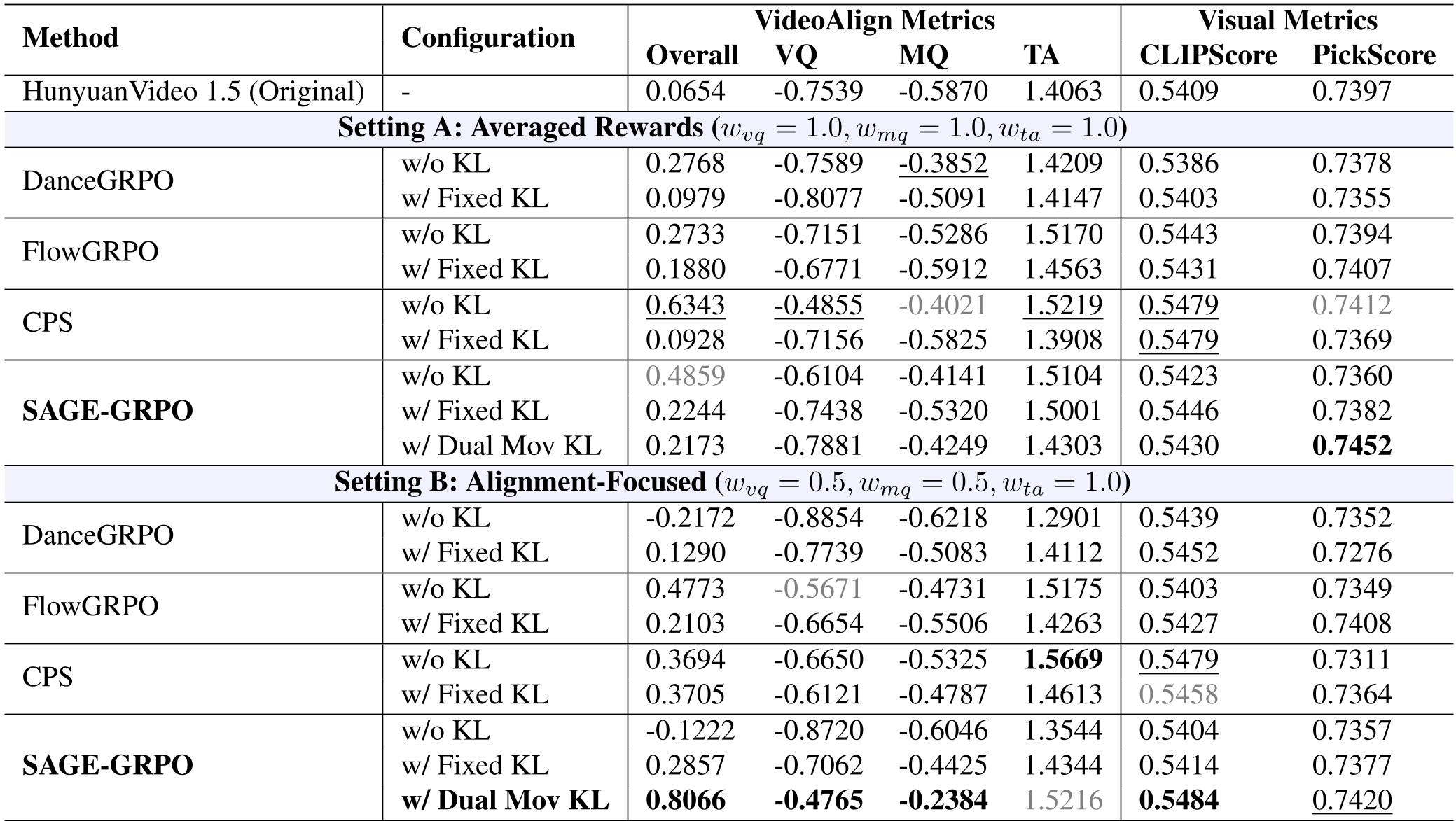 Table: SAGE-GRPO (Dual Mov KL) achieves an Overall score of 0.8066 in the alignment-focused setting, nearly doubling the performance of previous SOTA methods.
Table: SAGE-GRPO (Dual Mov KL) achieves an Overall score of 0.8066 in the alignment-focused setting, nearly doubling the performance of previous SOTA methods.
Qualitative Impact
Visually, this translates to videos that follow complex prompts (like "a soldier's features etched with fatigue") with far greater emotional depth and fewer temporal artifacts.
 Visual comparison: SAGE-GRPO (bottom right) preserves complex textures and lighting better than fixed-anchor or unconstrained versions.
Visual comparison: SAGE-GRPO (bottom right) preserves complex textures and lighting better than fixed-anchor or unconstrained versions.
Conclusion: A Manifold-First Future
SAGE-GRPO proves that the secret to successfully aligning complex generative models isn't just "more data" or "better rewards"—it's geometric awareness. By forcing the RL agent to stay within the boundaries of what the model already "knows" (the manifold), we can finally achieve stable, high-fidelity video alignment.
Future Outlook: This manifold-aware approach is likely to be adapted for other continuous-flow domains, such as audio generation and robotic trajectory planning, where stability is paramount.