[Memento-Skills] The Agent as Architect: Achieving Continual Learning Without Gradient Descent
Memento-Skills is a generalist LLM agent system that functions as an "agent-designing agent," autonomously constructing and refining a library of reusable skills (code, prompts, and markdown) to solve complex tasks. Built on the Memento 2 framework, it achieves SOTA performance on GAIA and HLE benchmarks without updating any LLM parameters.
TL;DR
The Memento-Team has introduced Memento-Skills, an agentic system that doesn't just execute tasks—it designs the tools to solve them. By treating "skills" (modular code and prompts) as an evolving external memory, the system achieves massive performance gains (+116% on hard benchmarks) while keeping the underlying LLM (e.g., Gemini 3.1) completely frozen. It effectively replaces a "static model" with a "dynamic library of expertise."
The "Frozen Brain" Problem
Most current LLM agents suffer from a fundamental paradox: they are deployed with fixed parameters (), making them "stateless." Once they hit a task outside their training distribution or fail at a specific workflow, they have no intrinsic way to "remember" the mistake or "learn" a better route for next time.
The authors argue that we shouldn't be "rewriting neurons" (fine-tuning) for every new task. Instead, we should give the agent a writable notebook of executable skills. The challenge, however, is making this notebook more than just a graveyard of past logs—it needs to be a structured, evolving codebase.
Methodology: The Read-Write Reflective Loop
The core of Memento-Skills is the Stateful Reflective Decision Process (SRDP). It breaks down the agent's life into a continuous loop of five steps:
- Observe: Take in the user query.
- Read (Skill Selection): Use a behavior-aligned router to pick the best "skill" (a folder containing code, prompts, and documentation).
- Act: Execute the skill's multi-step workflow.
- Feedback: A "Judge" LLM evaluates the outcome.
- Write (Evolution): If it failed, a failure attribution module identifies the bug and rewrites the skill's code or prompt to add guardrails.
1. The Skill-Centric Architecture
Unlike traditional RAG that retrieves text chunks, Memento-Skills retrieves functional modules.
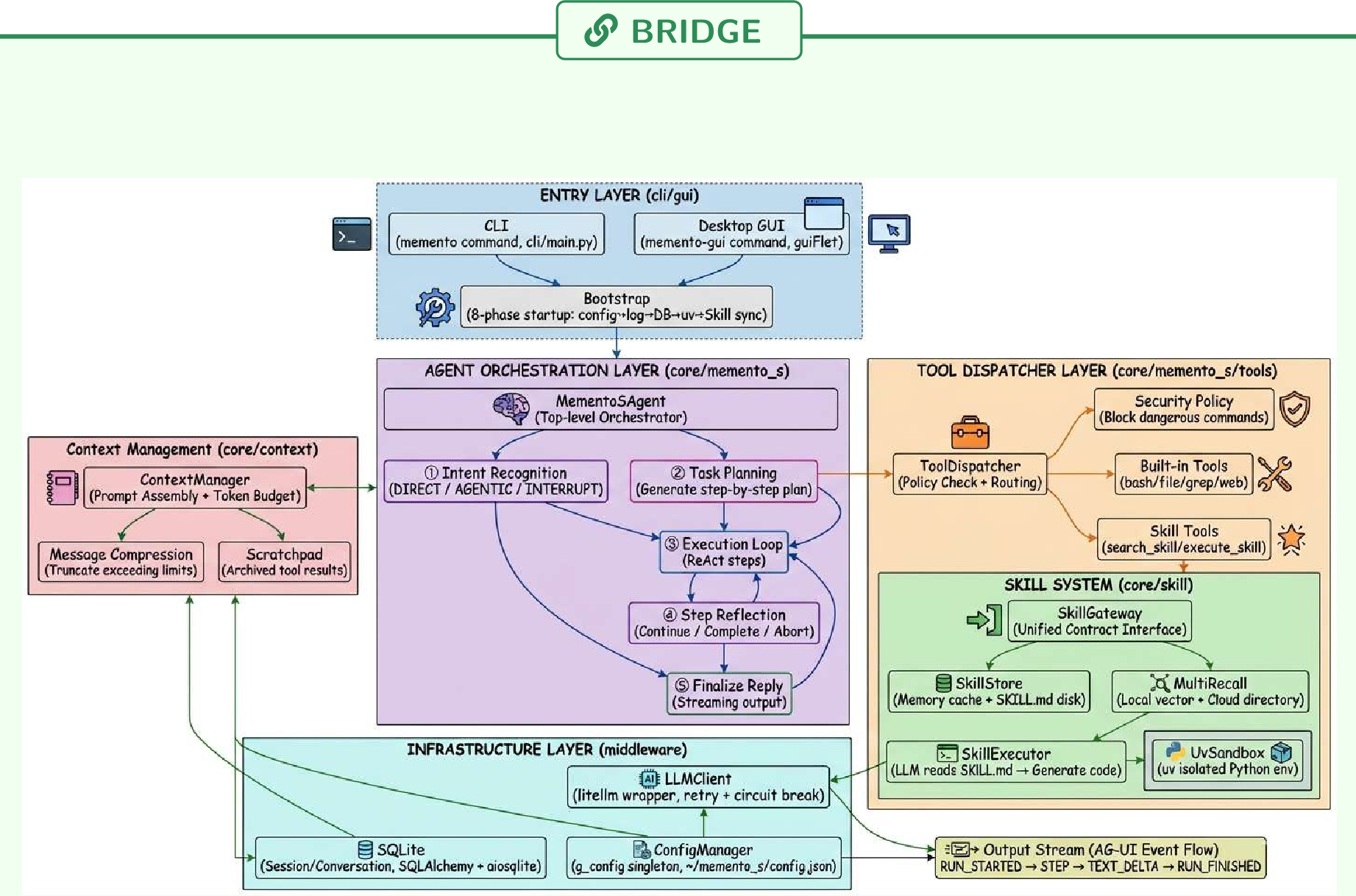 Figure: The system decomposes 30,000 lines of hard-coded "if-else" logic into a clean, modular Skill System managed by an Evolution Engine.
Figure: The system decomposes 30,000 lines of hard-coded "if-else" logic into a clean, modular Skill System managed by an Evolution Engine.
2. Behavior-Aligned Routing
One of the paper's key insights is that Cosine Similarity is not enough. Just because a task sounds like a "refund request" doesn't mean the "refund skill" is the best behavior if the user is actually asking for a "password reset" to access the refund page. The team trained a Memento-Qwen router using single-step offline RL. Instead of matching strings, it fits a -function that predicts execution success.
Experimental Results: From Sparsity to Density
The researchers tested this on GAIA (general tasks) and Humanity's Last Exam (HLE) (hard academic reasoning).
- GAIA: Accuracy jumped from 52.3% to 66.0%.
- HLE: Accuracy more than doubled, from 17.9% to 38.7%.
The "HLE" results are particularly telling. Because HLE has structured domains (Biology, Humanities, etc.), a skill learned to solve one "Biology" question was frequently reused to solve others.
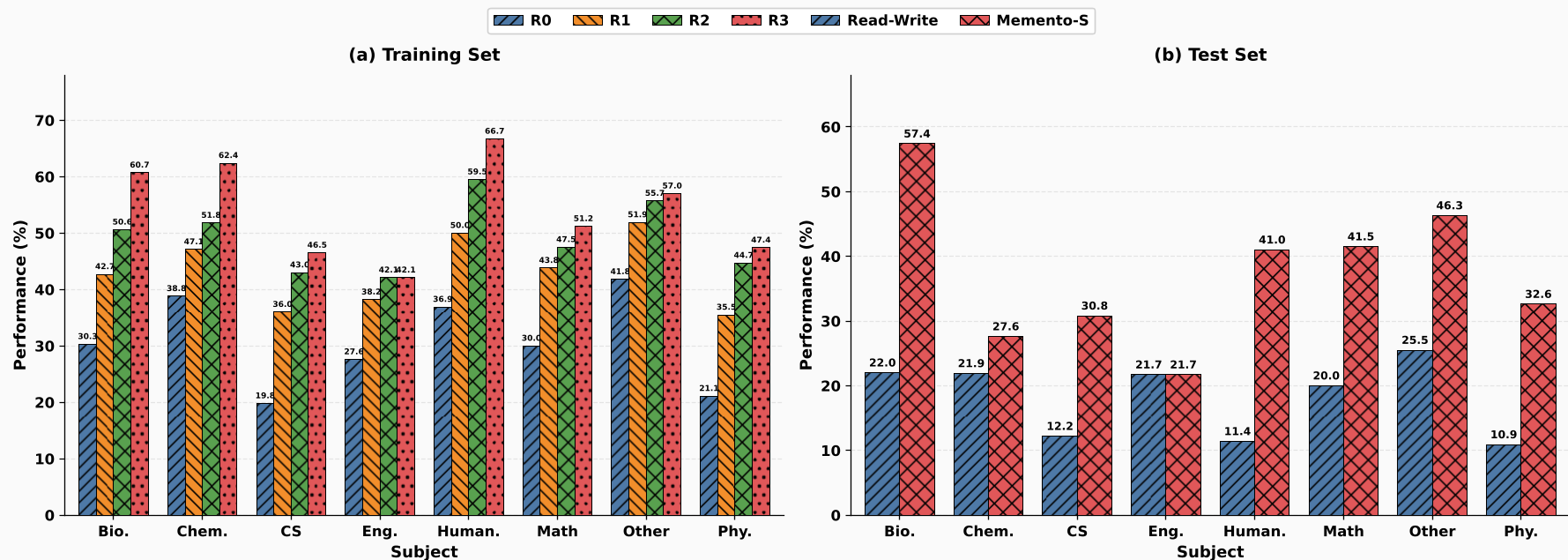 Figure: Success rates across training rounds (R0 to R3) show clear convergence as the skill library matures.
Figure: Success rates across training rounds (R0 to R3) show clear convergence as the skill library matures.
The "Muscle Memory" of Agents
As the agent learns, it fills its "embedding space" with skills. The paper uses t-SNE projections to show how a library grows from 5 atomic seeds to a dense cloud of 235 specialized skills. This "densification" reduces the "memory coverage radius," meaning the LLM has to do less "guessing" and more "following proven patterns."
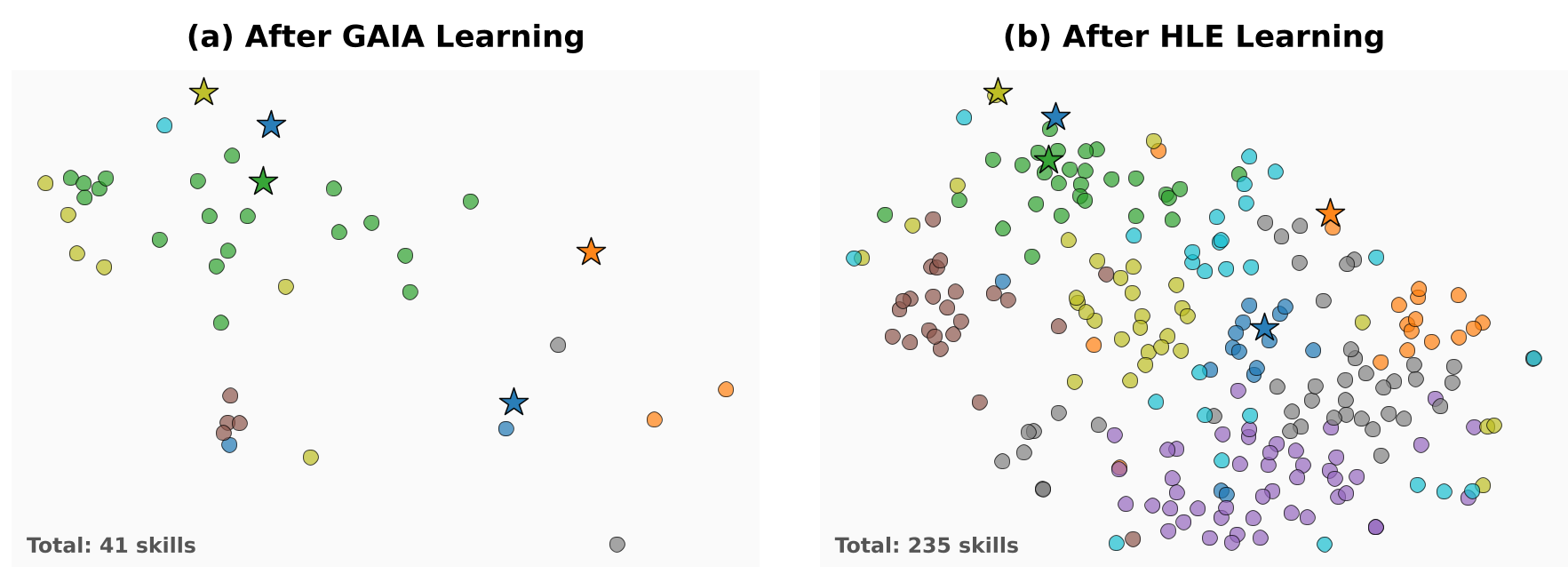 Figure: t-SNE projection showing the evolution from sparse seed skills (red) to a dense, domain-specific library (blue).
Figure: t-SNE projection showing the evolution from sparse seed skills (red) to a dense, domain-specific library (blue).
Critical Insight: The Three Independent Knobs
The paper concludes with a powerful theoretical framework. The gap between a "perfect" agent and a current agent can be closed by turning three independent levers:
- LLM Quality: Swap for a better base model to reduce generalization error.
- Memory Density: Run more "episodes" to add more skills and shrink the coverage gap.
- Retrieval Accuracy: Improve the router to reduce selection error.
By separating these, Memento-Skills provides an engineering-friendly roadmap for building agents that actually get smarter every day they spend in "production," without ever needing a GPU cluster for retraining.
Conclusion
Memento-Skills proves that a "frozen" LLM is not a "static" LLM. By moving the learning process from the model weights to an externalized skill library, we gain transparency, safety (via code unit tests), and continuous improvement. As one of the characters in the paper's witty dialogue notes: "The diminishing returns aren’t a bug; they’re a sign the system is converging."