本文提出了 MMaDA-VLA,一种原生大规模离散扩散视觉-语言-动作模型。该模型通过统一的离散 Token 空间,将指令理解、未来场景预测(Goal Observation)和动作执行(Action Chunk)集成在单一的 Masked Token 降噪框架下,显著提升了机器人的长程操作能力。
TL;DR
传统的机器人大模型(VLA)往往像写文章一样“逐字”预测动作,这在处理复杂的物理操作时容易导致“一步错步步错”。本文提出的 MMaDA-VLA 抛弃了传统的自回归范式,引入了**原生离散扩散(Discrete Diffusion)**框架。它不仅能理解指令,还能在脑中预演“未来画面”,并以此为基准,通过多次并行迭代精炼出一整块动作序列。在 CALVIN 等长程任务中,它的表现远超 OpenVLA 等强基线,成功率达到了惊人的 90% 以上。
核心痛点:为什么机器人不该“自回归”?
目前主流的机器人策略模型面临两个核心挑战:
- 顺序偏见(Order Bias):机器人的 7 自由度动作向量各维度之间是空间相关的,并没有严格的先后顺序。强行用自回归(LLM 这种从左到右)的方式预测动作,会引入不必要的逻辑负担。
- 动力学缺失:很多模型只管低头“做动作”,而不抬头“看路”。它们缺乏对动作执行后环境会变成什么样的预判。
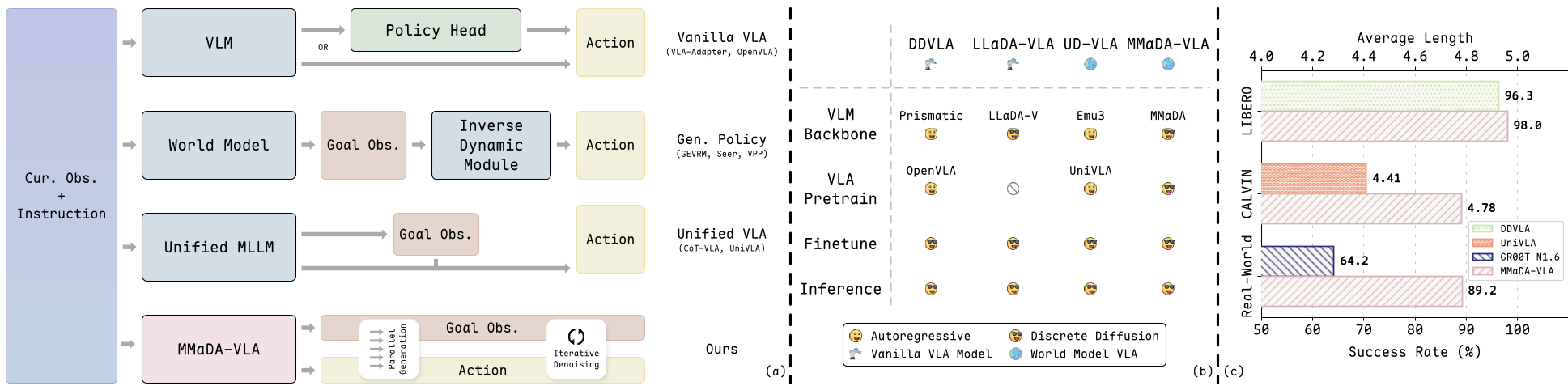 注:左图展示了传统 VLA 与 MMaDA-VLA 在架构上的本质区别:从级联到统一生成的跃迁。
注:左图展示了传统 VLA 与 MMaDA-VLA 在架构上的本质区别:从级联到统一生成的跃迁。
MMaDA-VLA 的解法:万物皆可 Diffusion
MMaDA-VLA 的核心思想非常纯粹:将视觉、语言、动作全部离散化为 Token,然后用一个扩散模型来搞定一切。
1. 统一 Token 空间 (Unified Token Space)
模型使用 MAGVIT-v2 处理图像,用文本 Tokenizer 处理指令,并对连续动作进行量化分箱。这样,所有的输入都变成了模型可以处理的符号序列。
2. 并行降噪与混合注意力
这是本文的“物理直觉”所在。模型在推理时,会先在“未来图像”和“动作序列”的位置填满噪声(Mask Token)。 接下来,模型分多次(如 24 步)进行迭代降噪:
- 在每一次迭代中,动作 Token 会参考正在生成的“未来目标图”。
- 混合注意力机制:同一模态内部使用全向注意力(Bidirectional),确保动作各维度之间互相观测;不同模态间使用因果注意力,确保生成过程受到指令的约束。
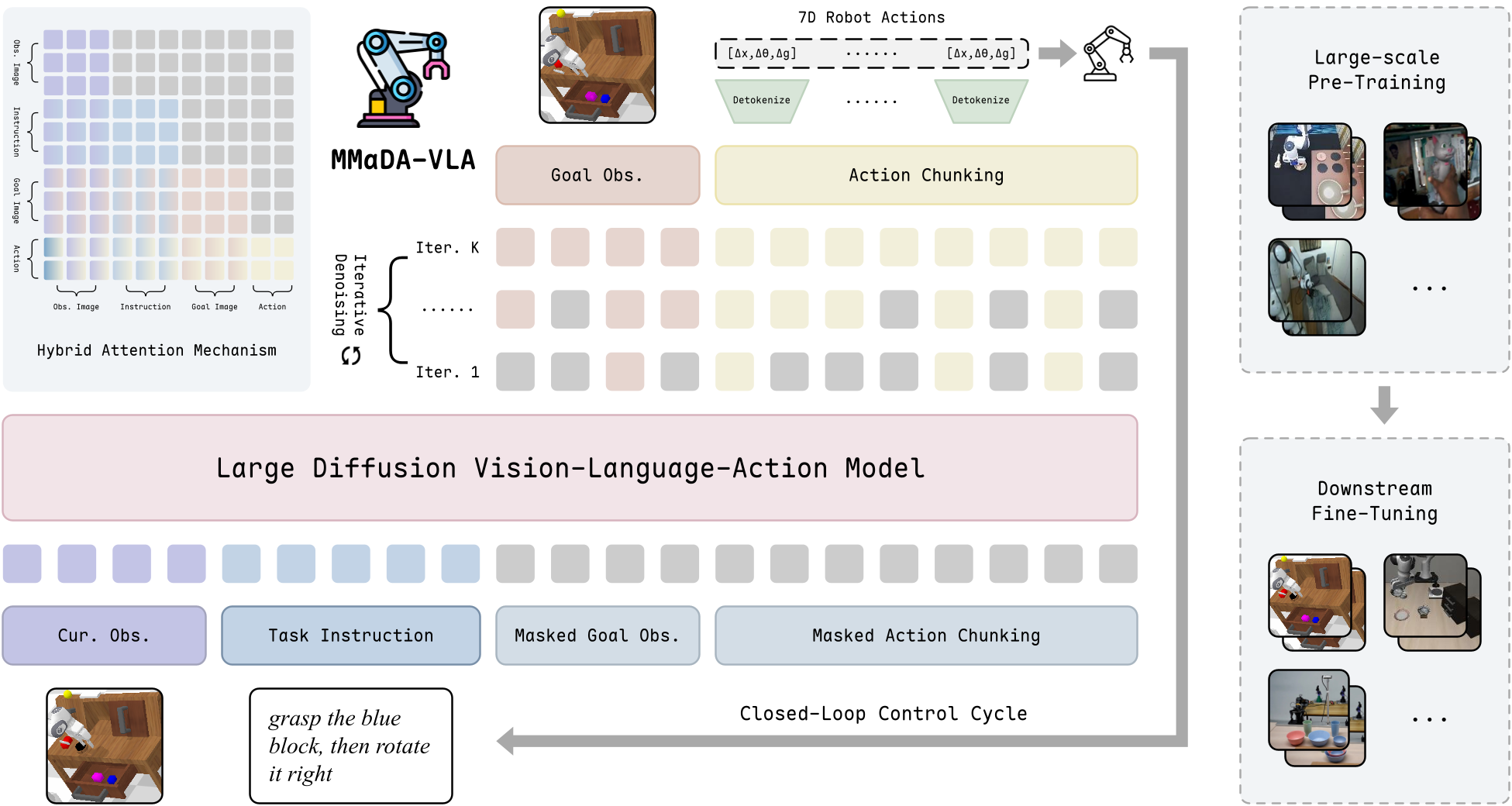 MMaDA-VLA 的全景架构:从多模态输入到并行 token 生成的完整闭环。
MMaDA-VLA 的全景架构:从多模态输入到并行 token 生成的完整闭环。
实验战绩:全方位 SOTA
MMaDA-VLA 在仿真和真机实验中表现出了极强的韧性。
- CALVIN 长程挑战:在最难的 ABC→D 迁移设置下,它能连续完成近 5 个子任务,平均执行长度为 4.78,几乎解决了这一基准。
- 真机鲁棒性:在面对人体干扰、目标物突然位移时,MMaDA-VLA 展现出了惊人的“纠错”能力。这得益于扩散模型的非顺序特性,它可以在发现错误后通过后续的 Denoising 步尝试拉回正确的轨迹。
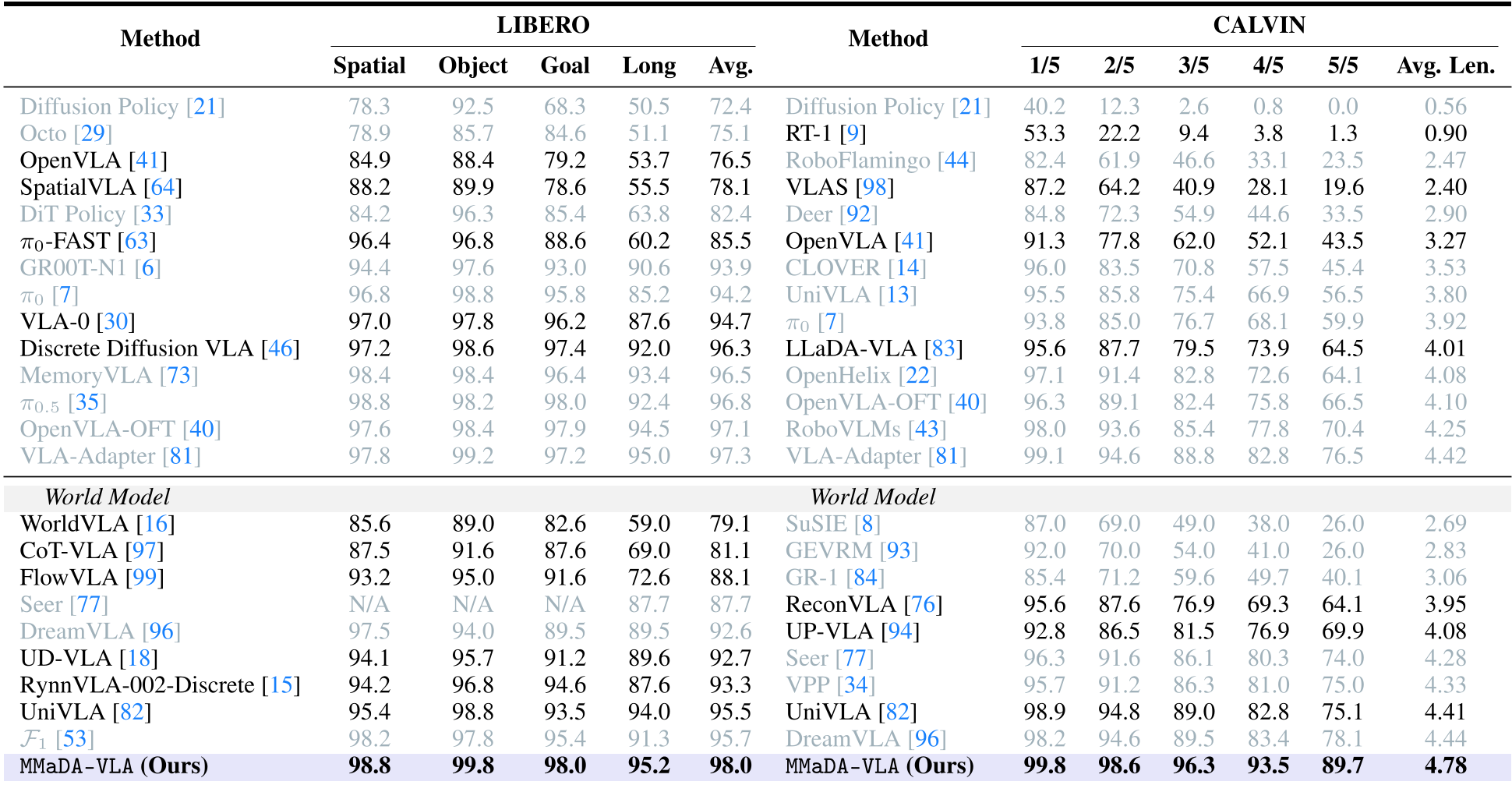 结果分析:在几乎所有维度上,MMaDA-VLA 均显著优于基于流匹配(Flow-based)或简单行为克隆的模型。
结果分析:在几乎所有维度上,MMaDA-VLA 均显著优于基于流匹配(Flow-based)或简单行为克隆的模型。
深度洞察:不仅仅是预测,更是“想好了再做”
作者在分析中指出,即便生成的“未来图”在像素层面不够精细,但它捕捉到的任务语义(Task Dynamics)——比如夹爪应该在哪个位置闭合——对于动作的执行至关重要。
此外,为了解决扩散模型采样慢的问题,模型引入了类似大模型 KV Cache 的优化,通过自适应缓存更新,在保证精度的前提下大大提升了实时控制的频率。
总结与局限
MMaDA-VLA 代表了具身智能模型的一个重要趋势:原生化与生成化。 局限性:尽管它非常强大,但受限于离散 Token 的分辨率,目前在处理极其精密的工业操作(微米级对齐)时,可能仍需进一步优化高效率的 Tokenizer。
未来的研究方向可能会集中在如何让这种扩散 VLA 具备更强的实时推理能力,以及在更具挑战性的开放世界场景中通过 Pre-training 涌现出更强的泛化性。