本文介绍了 MolmoWeb,一系列全开源的视觉 Web Agent(4B 和 8B 参数量),以及大规模训练数据集 MolmoWebMix。MolmoWeb 仅凭屏幕截图即可执行复杂的浏览器任务,在 WebVoyager 等多个 benchmark 上超越了同规模的 Fara-7B,甚至击败了基于 GPT-4o 的闭源感知 Agent。
TL;DR
长期以来,能在网页上像人一样自由穿梭的 AI 代理(Web Agent)一直被 GPT-4o 或 Gemini 等巨头垄断。近日,Allen Institute for AI (AI2) 发布的 MolmoWeb 彻底打破了这一格局。这套全开源的系统证明了:无需臃肿的 HTML 代码,仅凭屏幕截图(Vision-only),一个 8B 大小的模型就能在网页任务处理上超越顶尖闭源模型。
痛点深挖:HTML 的“诅咒”与黑箱困境
在 MolmoWeb 出现之前,主流 Web Agent 方案主要面临两个死锁:
- 输入过载 (Token Bloat):传统的 Agent 需要阅读页面的 AxTree(可访问性树),这往往消耗数万个 Token,推理成本高昂且速度缓慢。
- 闭源不透明:商业模型虽然强大,但其训练数据和操作逻辑是黑箱,研究者无法复现,也难以针对垂直业务(如内部办公系统)进行优化。
作者的 Insight 非常激进: 人类使用网页只需眼睛看,不看源代码。AI 也应该如此。通过模拟人类的视觉感知,Agent 可以摆脱对底层 DOM 结构的依赖,增强模型对动态内容的鲁棒性。
方法论详解:如何炼就“火眼金睛”?
MolmoWeb 的核心不在于复杂的架构(它基于现有的 Molmo2 视觉语言模型),而在于其史诗级的训练集 MolmoWebMix。
1. 导师机制 (AxTree-to-Pixel)
为了教模型如何在像素层面操作,作者利用一个“懂 HTML”的强力模型(如 Gemini Flash)在界面上行走。导师看到的是代码,但系统会同步记录下当时的屏幕截图和点击的像素坐标。
- 创新点:将“点击元素 ID”转化为“点击 X, Y 坐标”,强制模型学习视觉定位(Grounding)能力。
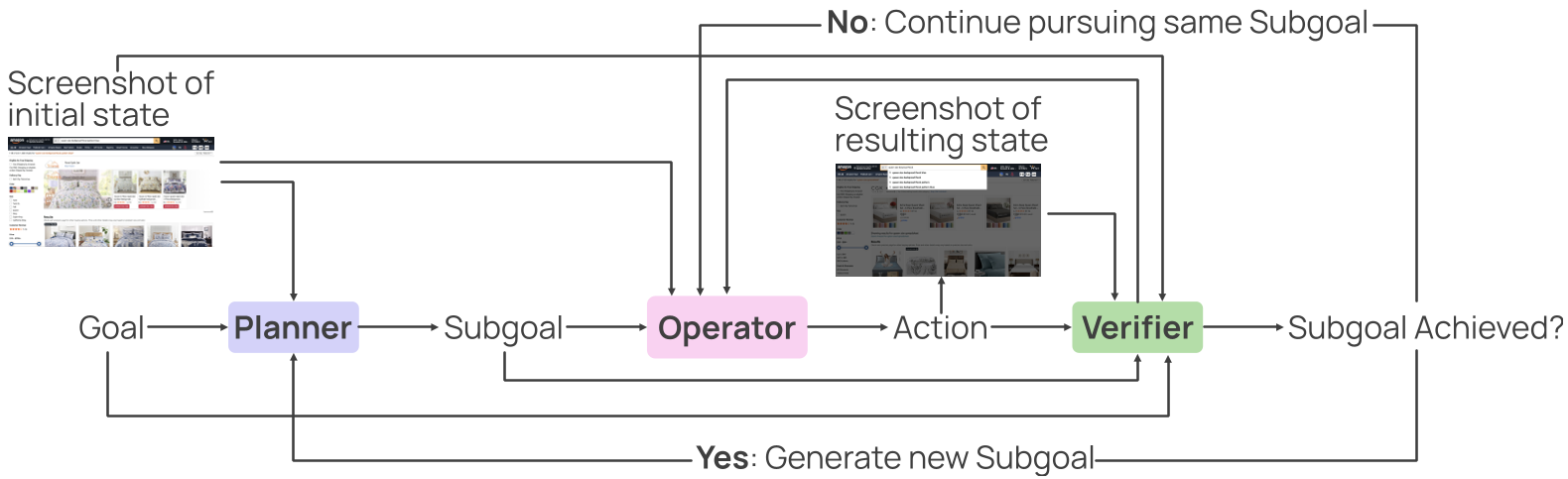
2. 多智能体协作流水线 (Multi-agent Pipeline)
为了生成比普通 LLM 更具逻辑性的操作序列,作者设计了一个三重架构:
- Planner:负责拆解目标(如:先搜索,再过滤,最后下单)。
- Operator:负责执行具体的单步点击。
- Verifier:每一步后观察截图,验证该步骤是否成功。
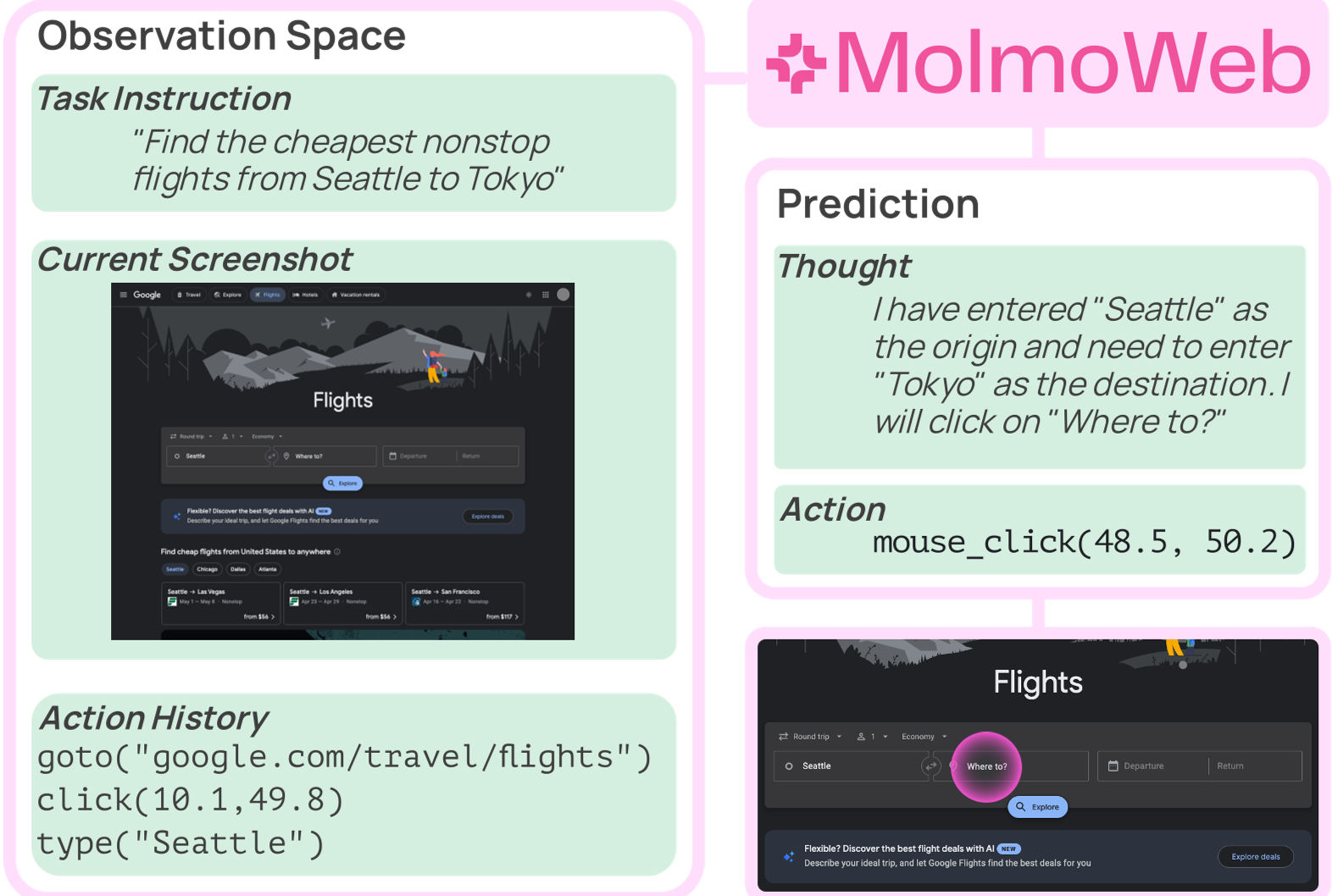
3. 操作空间定义
模型不仅输出动作,还会先输出一段自然语言“思考”(Thought),这种类似 Chain-of-Thought 的机制显著提升了在长流程任务中的逻辑连贯性。
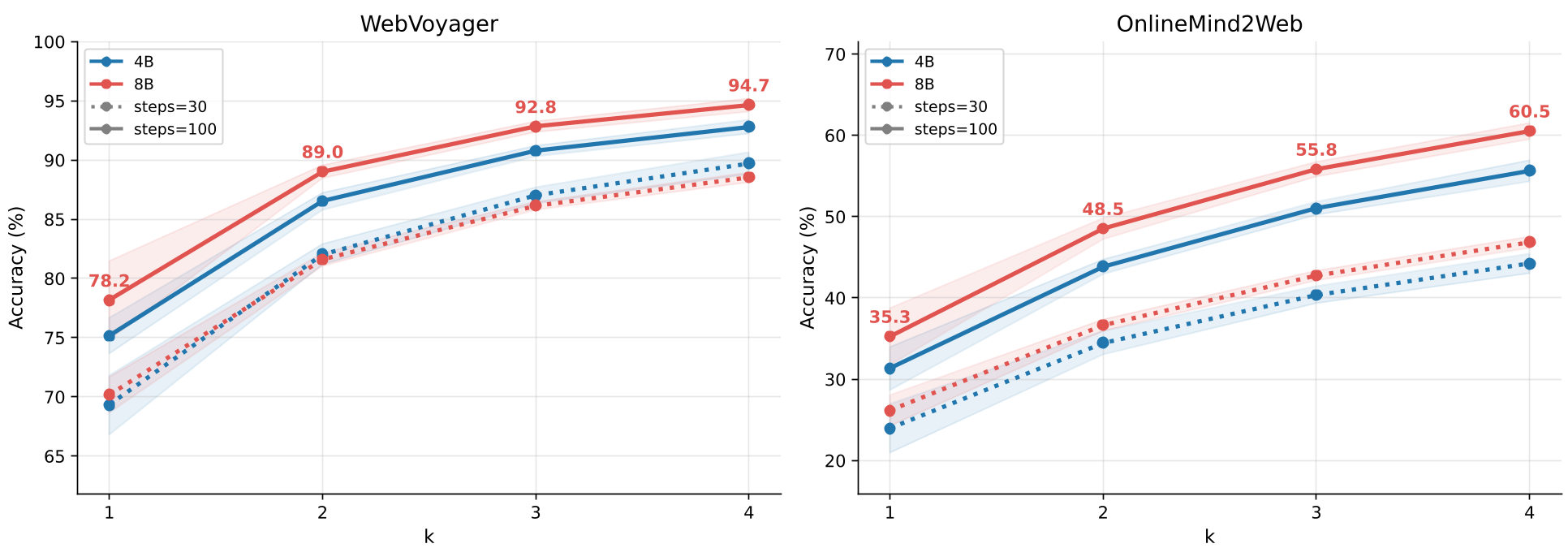
实验与结果:小模型的大反扑
实验结果令人振奋。在主流的 WebVoyager 榜单上:
- MolmoWeb-8B 的 Pass@1 达到了 78.2%,显著高于同级别的 Fara-7B (73.5%)。
- 并行缩放 (Pass@4):当你让模型跑 4 次并让 VLM 判定最好的结果时,成功率直接飙升至 94.7%!
深度洞察:合成数据 VS 人类数据 有趣的是,实验发现单纯使用人类演示数据的效果反而不如合成数据。原因在于: 人类在浏览网页时会有很多冗余的探索(乱点、犹豫),而基于 HTML 代码生成的合成数据轨迹更直接、干净,信噪比更高,更适合 Agent 进行模仿学习(Imitation Learning)。
| 训练数据 | WebVoyager (WebV) | Online-Mind2Web (OM2W) | | :--- | :--- | :--- | | 仅人类数据 (28K) | 27.8 | 13.2 | | 仅合成轨迹 (106K) | 67.8 | 22.0 | | 混合策略 (MolmoWebMix) | 68.5 | 21.4 |
总结与展望 (Conclusion)
MolmoWeb 的发布标志着 视觉 Web Agent 彻底走向平民化。
它的价值在于:
- 性能降维打击:用 8B 的参数量达到了以往需要千亿级模型加持的效果。
- 全流程开源:从代码、权重到 10M 级别的感知数据全部公开,这为开发者构建垂直领域的“数字员工”提供了最佳底座。
局限性: 尽管强大,模型在处理极小文字的 OCR 以及包含超过 10 步的超长逻辑决策时仍有翻车可能。未来的突破点可能在于引入强化学习(RL),让 Agent 在不断的“试错”中学会自动纠错。
Takeaway: 别再死磕 HTML 爬虫了,视觉感知才是大模型操作电脑的正确姿势。