本文提出了 Dream2Act,这是一个以机器人为核心的零样本(Zero-shot)交互框架。该框架利用生成式视频模型(Seedance 2.0)直接幻化出机器人完成任务的视频,并从中提取原生运动轨迹,在 Unitree G1 人形机器人上实现了多种复杂交互任务。
TL;DR
人形机器人如何学会像人一样与环境交互?传统的做法是“模仿人”,但人类和机器人的骨架完全不同,这种“强行换壳”往往导致机器人手脚错位。Dream2Act 另辟蹊径:让 AI 直接生成一段“机器人成功完成任务”的视频,再把视频里的动作“抠”出来给机器人执行。这一架构在 Unitree G1 上实现了 37.5% 的零样本交互成功率,彻底解决了形态差异(Morphology Gap)带来的空间对齐难题。
1. 痛点:为什么“模仿人类”这么难?
在具身智能领域,Retargeting(动作重定向)是将人类动作迁移到机器人的主流手段。然而,这种“以人为中心”的范式存在致命缺陷:
- 形态差异 (Morphology Gap):人类的腿长比例跟 G1 机器人不一样,人类能坐下的位置,机器人可能够不着。
- 空间错位:微小的人类姿态估计误差在长距离移动中会迅速累积。
- 动力学违背:很多生成的人类动作在物理上对机器人是不可行的(如重心不稳)。
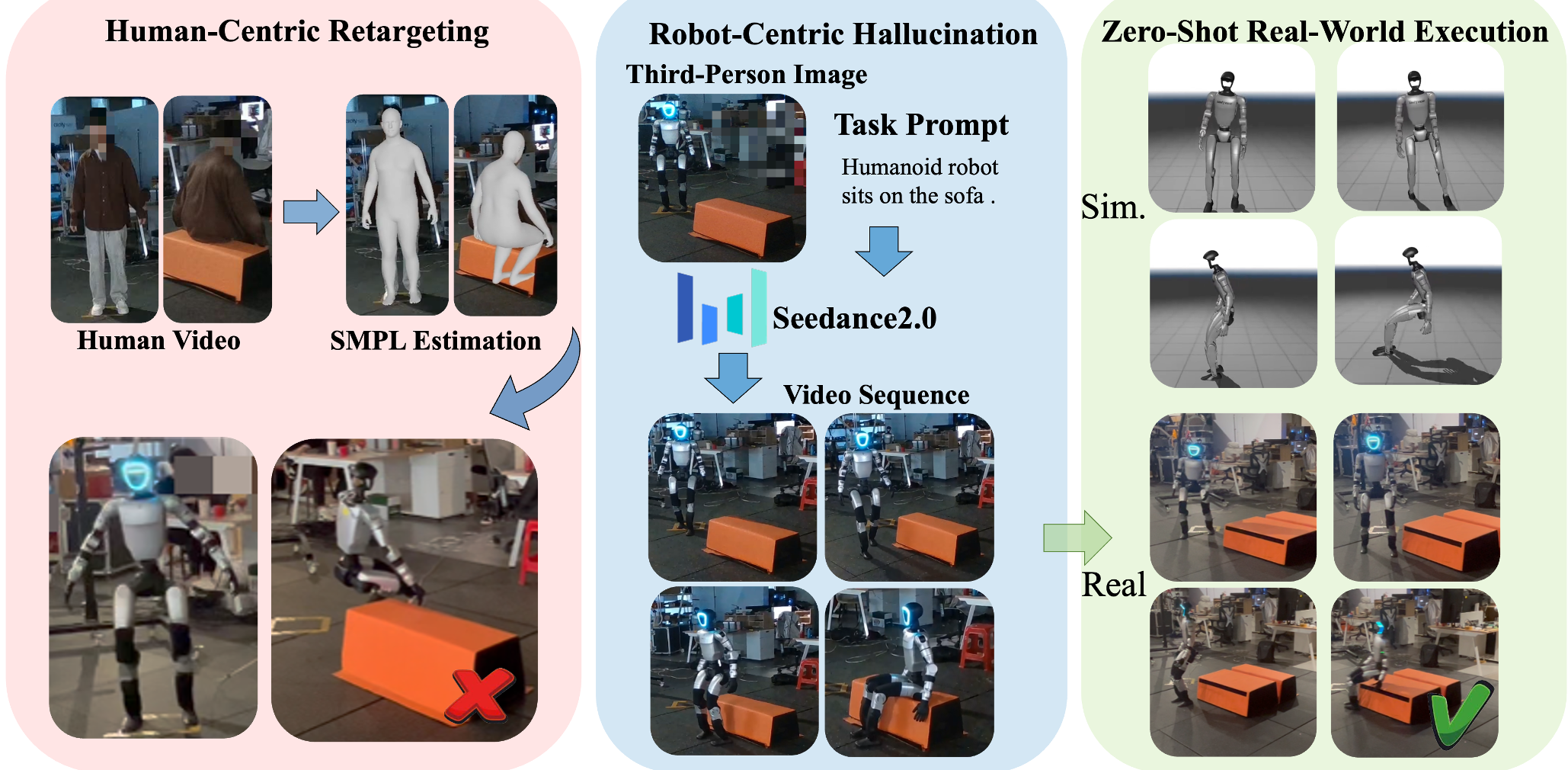 图 1:(A) 传统重定向因形态差异导致失败,(B) Dream2Act 通过原生视觉合成实现精准对齐。
图 1:(A) 传统重定向因形态差异导致失败,(B) Dream2Act 通过原生视觉合成实现精准对齐。
2. 核心直觉:从“看人学”到“想自己做”
Dream2Act 的核心思想是 Robot-Centric (以机器人为中心)。既然视频生成模型(如 Seedance 2.0)已经学习了世界的物理规律,为什么不直接让它画出机器人工作的样子?
核心架构拆解
整个系统分为三个阶段:
- 交互幻化 (Interaction Hallucination):输入一张包含机器人和目标的现场照片,给定指令(如“坐在沙发上”),Seedance 2.0 生成一段机器人完成该动作的高清视频。
- 原生姿态感知 (Native Pose Perception):利用专门针对 G1 机器人训练的 ViTPose 模型提取 2D 关键点,再通过 2D-to-3D Lifting 网络还原出机器人的 3D 关节坐标。
- 运动恢复与执行:通过 URDF 约束的逆运动学(IK)算法确保动作符合机器人的物理极限,最后交给 Sonic 控制器完成全身平衡控制。
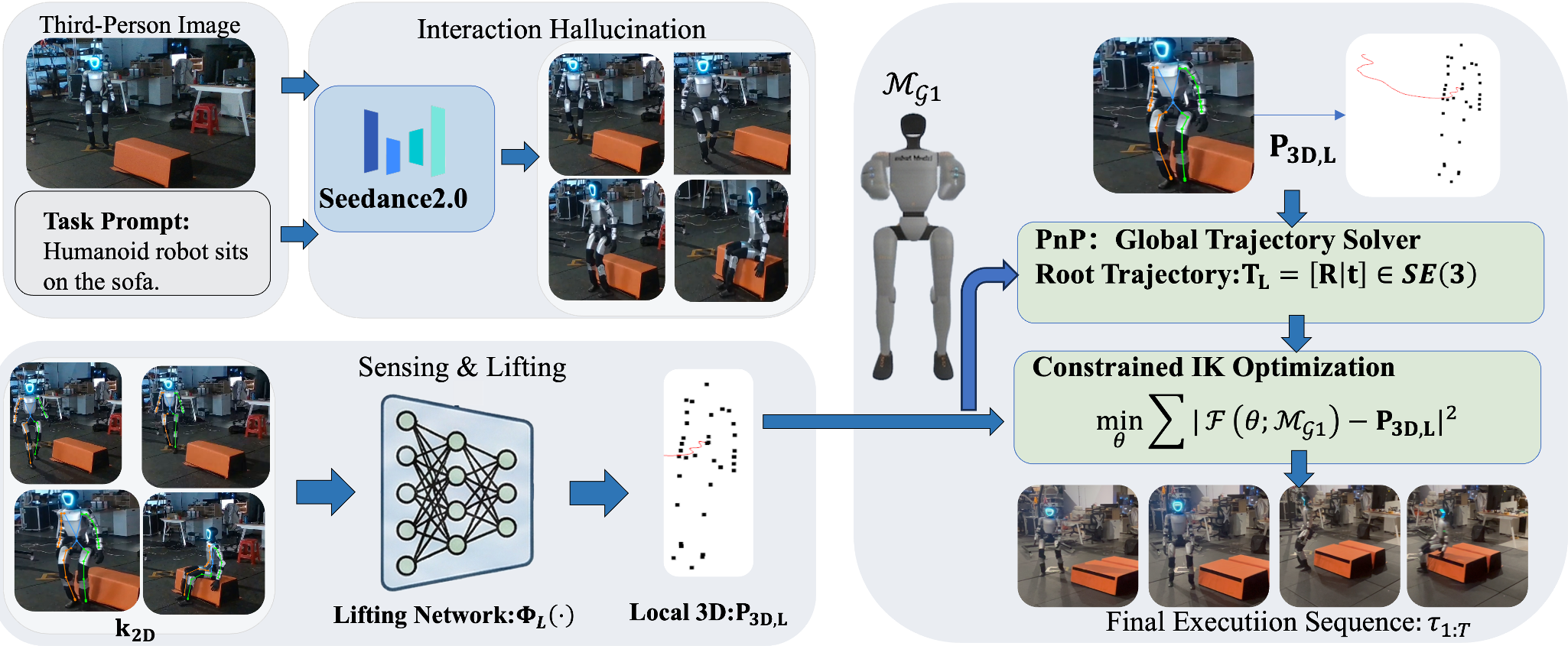 图 2:Dream2Act 系统全流程:从视频合成到 3D 提升,再到物理执行。
图 2:Dream2Act 系统全流程:从视频合成到 3D 提升,再到物理执行。
3. 实验战绩:降维打击传统基线
研究人员在 Unitree G1 机器人上测试了四个高难度任务:踢球、抱箱子、打沙袋、坐沙发。
关键实验发现:
- 空间对齐精度:在涉及 2 米以上移动的踢球任务中,传统方法误差高达 0.82m(离球太远踢不到),而 Dream2Act 保持在 0.1m 左右。
- 成功率:传统重定向在这些“空间敏感型”任务中全军覆没(0%),而 Dream2Act 表现稳健,尤其在坐沙发任务中达到了 70% 的惊人成功率。
 图 3:不同任务下的定性对比,可以看到 Dream2Act(下行)在接触精度和稳定性上完胜。
图 3:不同任务下的定性对比,可以看到 Dream2Act(下行)在接触精度和稳定性上完胜。
4. 深度洞察:数据驱动的“Sim-to-Real”
为了让机器人能从视频里看清自己的动作,作者构建了一个混合数据集:
- 仿真数据:在 Isaac Lab 中渲染了 500 多万帧 G1 机器人的动作。
- 真实数据:引入 Human-in-the-Loop (HITL) 标注,修正了光影和材质的领域偏差(Domain Shift)。 这种做法使得其姿态估计精度(AP 值)在真实场景下显著优于直接使用通用的开源模型。
5. 局限与未来
尽管表现惊艳,Dream2Act 目前仍面临 推理延迟 的挑战——扩散模型生成视频需要时间,这使得它目前更像是一个“离线规划器”而非实时控制器。
总结 (Takeaway): Dream2Act 证明了通过强大的大视觉模型,我们可以跳过繁琐的动作采集和数据标注,直接用“想象力”驱动硬件。这为人形机器人进入非结构化人类环境提供了一条极具潜力的技术路径。