本文推出了 MOSS-TTS,这是一个基于“离散音频 Token + 自回归建模 + 大规模预训练”范式的语音生成基座模型。该系统包含高性能分层离散分词器 MOSS-Audio-Tokenizer,并对比了 Delay-Pattern(侧重长文本与可控性)和 Local-Transformer(侧重音色保真与低延迟)两种架构,实现了 SOTA 级的零发语音克隆(Zero-shot Voice Cloning)与超长文本合成。
TL;DR
复旦大学与 SII-OpenMOSS 团队发布的 MOSS-TTS,标志着开源语音基座模型向“LLM 化”迈出了坚实的一步。它摒弃了复杂的流水线堆砌,通过 离散 Token + 纯 AR(自回归)建模,在百万小时级数据上训练出了具备零样本克隆(Zero-shot Cloning)、精确时长控制、拼音/音素级编辑以及小时级长音频生成的强大模型。
核心洞察:为什么要回归“极简主义”?
当前的 TTS 领域正处于技术路线的十字路口:一边是追求极致推理速度的 NAR(非自回归)或流匹配(Flow-matching)模型,另一边是追求扩展性(Scaling)的 AR 分词模型。
MOSS 团队认为,要实现真正的“语音基座”,必须解决扩展性(Scalability)问题。他们避开了使用 HuBERT 等外部“语义教师”的传统路子,而是构建了一个端到端优化的音频分词器。这种做法的直觉在于:如果 Token 足够好,语音生成就纯粹变成了 Token 预测问题,可以直接复用 LLM 成熟的 Scaling Law。
技术架构剖析
1. MOSS-Audio-Tokenizer:更强的底座
分词器采用 RVQ-GAN 框架,但其核心是纯因果 Transformer(而非 CNN)。它将 24kHz 音频压缩至极低的 12.5 fps,这意味着进行 AR 建模时,序列压力大大降低。
- 变量比特率:支持 0.125 到 4 kbps 的动态调整。
- 统一表示:通过 ASR 辅助任务,让离散 Token 在保留听感的同时,天然携带语义信息。
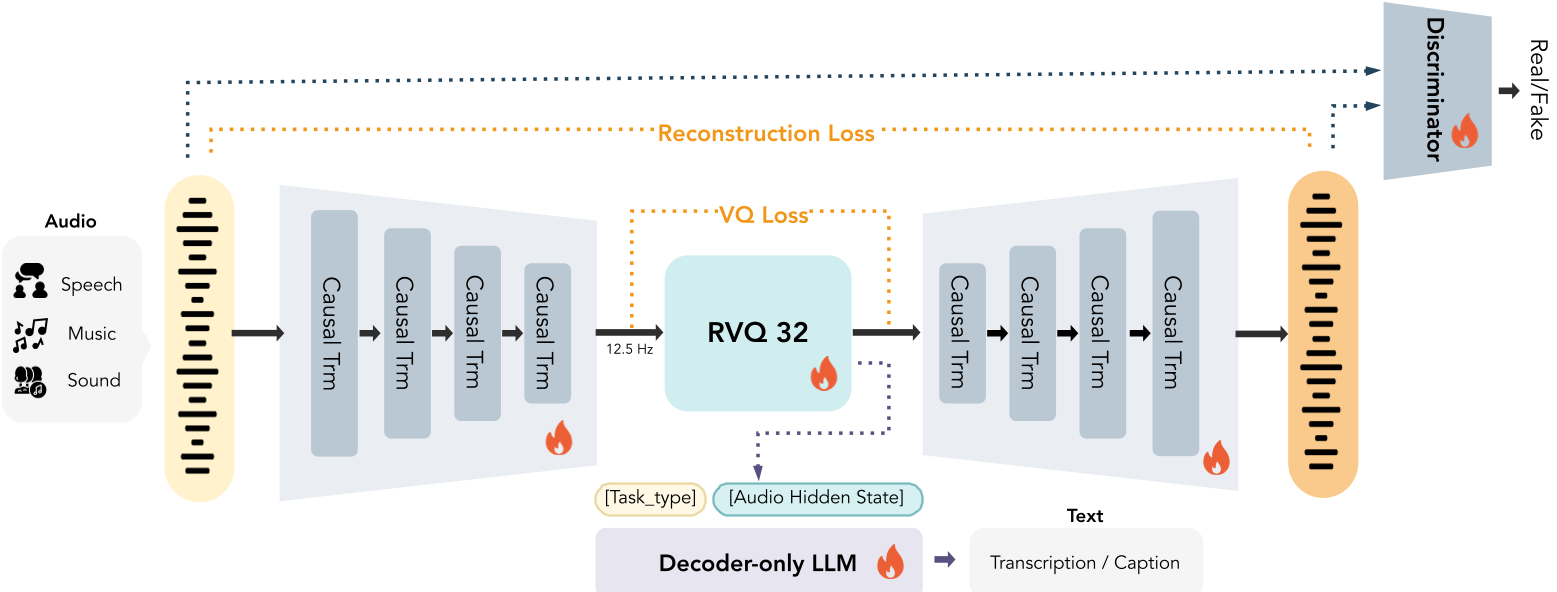 图 1:MOSS-Audio-Tokenizer 架构,展示了因果 Encoder/Decoder 与分层 RVQ
图 1:MOSS-Audio-Tokenizer 架构,展示了因果 Encoder/Decoder 与分层 RVQ
2. 双重 AR 架构:性能与效率的权衡
MOSS-TTS 并没有只提供一个模型,而是针对不同场景设计了两种架构:
- Delay-Pattern (MOSS-TTS):通过时间偏移处理 RVQ 层次,结构极简,极其适合**长文本(Long-context)**生成和高并发部署。
- Local-Transformer:在主模型产出 Latent 后,增加一个局部小 Transformer 进行帧内解码。实验证明,这种架构在音色相似度上表现更强,尤其在 1.7B 小参数下就能 PK 掉许多 7B 模型。
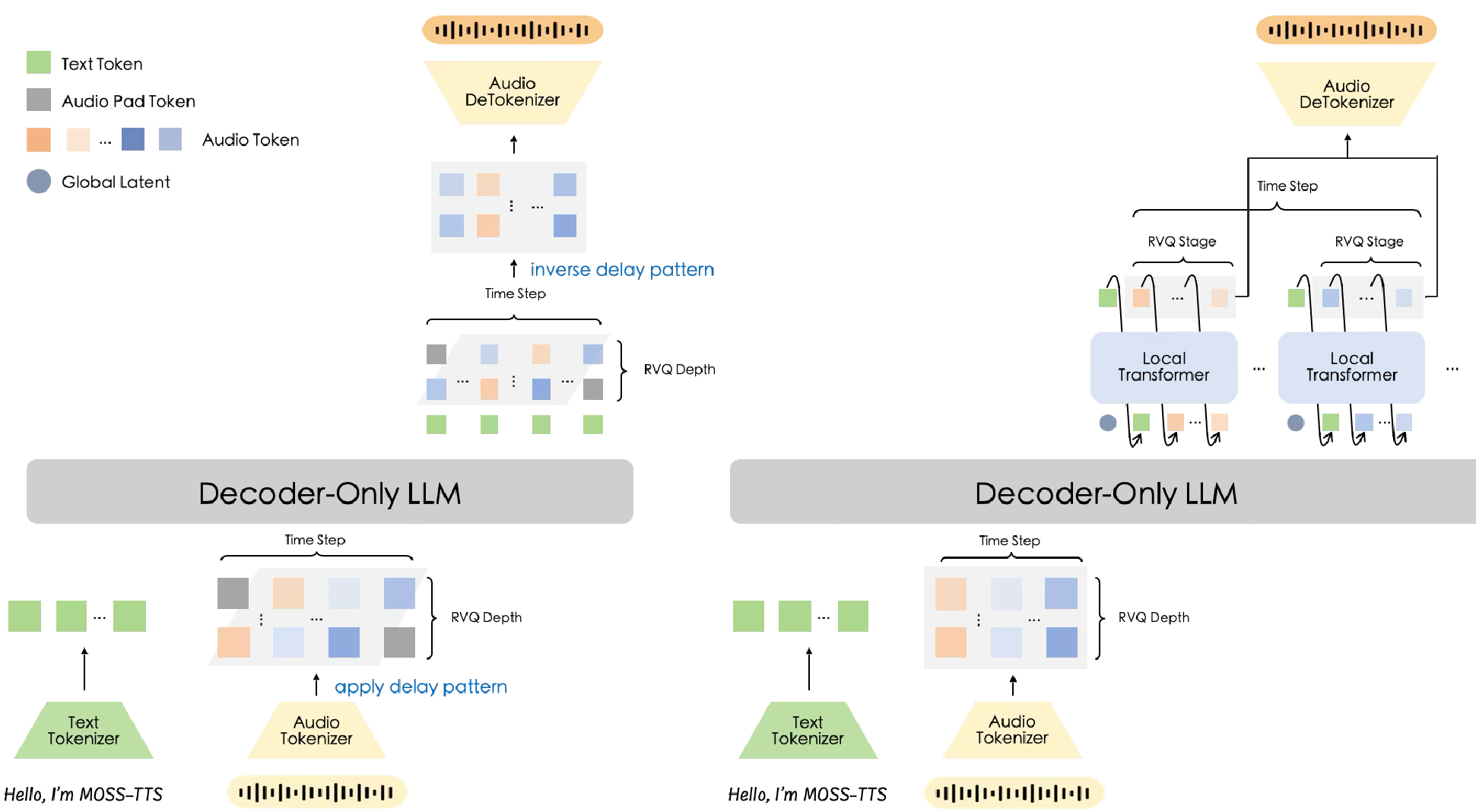 图 2:左侧为 Delay Pattern 模式,右侧为 Local Transformer 模式
图 2:左侧为 Delay Pattern 模式,右侧为 Local Transformer 模式
数据流水线:从“脏数据”到“炼丹炉”
模型能否 generalization 全看数据。MOSS 团队构建了涵盖播客、有声书、影视等百万小时级的流水线。 其关键在于 Stages 3 & 4 的联合过滤:不再只看 ASR 结果,而是通过 LLM 诊断音频与文本的语言一致性、时长比例合理性。这种“交叉验证”确保了即便是在野外(In-the-wild)抓取的数据,也能提供高质量的监督信号。
实验战绩与深度分析
在 Seed-TTS-eval 基准测试中,MOSS-TTS 展现了惊人的 SIM(Speaker Similarity)得分:
- Continuation 模式:相比于直接 Clone,利用上下文进行“语音续写”能显著提升音色稳定性。
- 时长控制:通过在 Prompt 中注入 Token Count,模型实现了平均误差 < 0.8% 的精确度。这意味着对于广告配音等对节奏高度敏感的任务,MOSS-TTS 已经是 Ready 状态。
 表 1:MOSS-TTS 在 Seed-TTS 测评集上的表现,SIM 值在开源模型中处于领先位置
表 1:MOSS-TTS 在 Seed-TTS 测评集上的表现,SIM 值在开源模型中处于领先位置
长音频生成的极限挑战
报告特别探讨了生成长达一小时音频时的表现。结果显示,虽然字准率(CER)能维持稳定,但**音色漂移(Speaker Drift)**是当前的主要瓶颈。模型在生成半小时后,音色会逐渐偏离原始 Prompt。
总结与启示
MOSS-TTS 的成功验证了:只要 Tokenizer 够强,数据规模够火,自回归就是王道。
该工作的局限性在于:英语环境下的长时一致性仍弱于中文;多语种(如日韩)的 Zero-shot 效果仍有提升空间。未来,如何通过强化学习(RL)或更长的 Context Window 来锁定音色,将是语音生成领域下一个决战点。
关键词:MOSS-TTS, Audio LLM, Zero-shot Voice Cloning, RVQ, Speech Foundation Model