本文提出了 Nexus 优化器算法,通过在预训练阶段最大化不同数据源之间的梯度相似度,使模型收敛于“任务共同极小值点”(Common Minima)。该方法在保持与 AdamW 相同的预训练 Loss 情况下,显著提升了下游任务的泛化能力,在 3B 参数模型上将 GSM8k 准确率提升了 15%。
TL;DR
在 LLM 领域,我们长期奉“预训练 Loss 越低,模型越强”为圭臬。然而,来自清华与字节跳动的最新研究 Nexus 挑战了这一直觉。它证明了:即使预训练 Loss 完全相同,收敛点的几何位置也会决定模型是“高分低能”还是“举一反三”。 通过在训练中强制任务间的梯度保持一致,Nexus 在 3B 模型上实现了推理能力的飞跃。
1. 痛点:被忽视的几何“疏离感”
目前的 LLM 预训练本质上是海量异构数据(代码、数学、网页)的“求和”过程。标准优化器(AdamW)在最小化总 Loss 时,往往会让模型落在图 (a) 所示的区域:虽然总分很高,但距离数学任务的极小值和代码任务的极小值都很远。
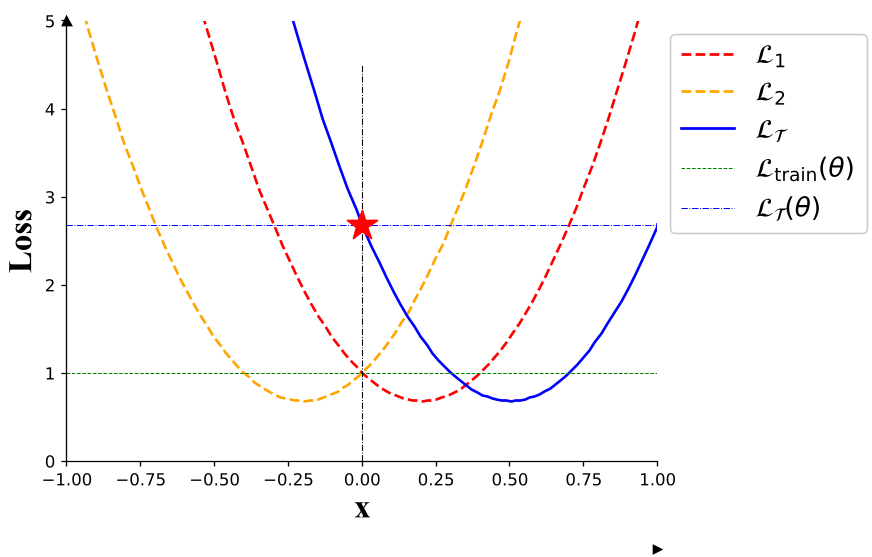 图 (a):离散的极小值(Sum of Minima);图 (b):共有的极小值(Intersection of Minima)
图 (a):离散的极小值(Sum of Minima);图 (b):共有的极小值(Intersection of Minima)
作者指出,这种几何上的“疏离”是泛化性能的杀手。如果能让模型收敛到所有任务极小值的“交集”处(图 b),模型在面对没见过的下游任务时,起跑线就会更近。
2. 核心直觉:梯度相似度即“紧凑性”
直接优化参数空间的距离(Closeness)在计算上是不可行的,因为你无法预知每个任务的绝对极小值在哪。
Nexus 提供了一个优雅的数学解法:最大化方向一致性。 若两个任务在每一步的梯度方向都高度重合,它们最终必然指向同一个目的地。
- 数学支撑:文章证明了梯度余弦相似度(Cosine Similarity)构成了参数紧凑性的有效上界。
- 二阶近似:为了优化相似度,必须计算 Hessian 矩阵,Nexus 通过“内循环”步巧妙地绕过了显式 Hessian 计算。
3. 方法论:Nexus 优化器架构
Nexus 并不是要完全取代 AdamW,而是一个“增强插件”。其核心是 Algorithm 3 所示工程适配版本:
- 双层模型:维护一个主模型和一个辅助内模型。
- 内循环探索:在每个微批次(Mini-batch)中,内模型先走一步(基于归一化 SGD),观察梯度的变化趋势。
- 梯度注入:计算内模型与主模型的位移,将其作为“伪梯度”交给外层优化器(如 AdamW)。
这种机制在几乎不增加算力成本的情况下,在更新中融入了“跨任务一致性”的正则化。
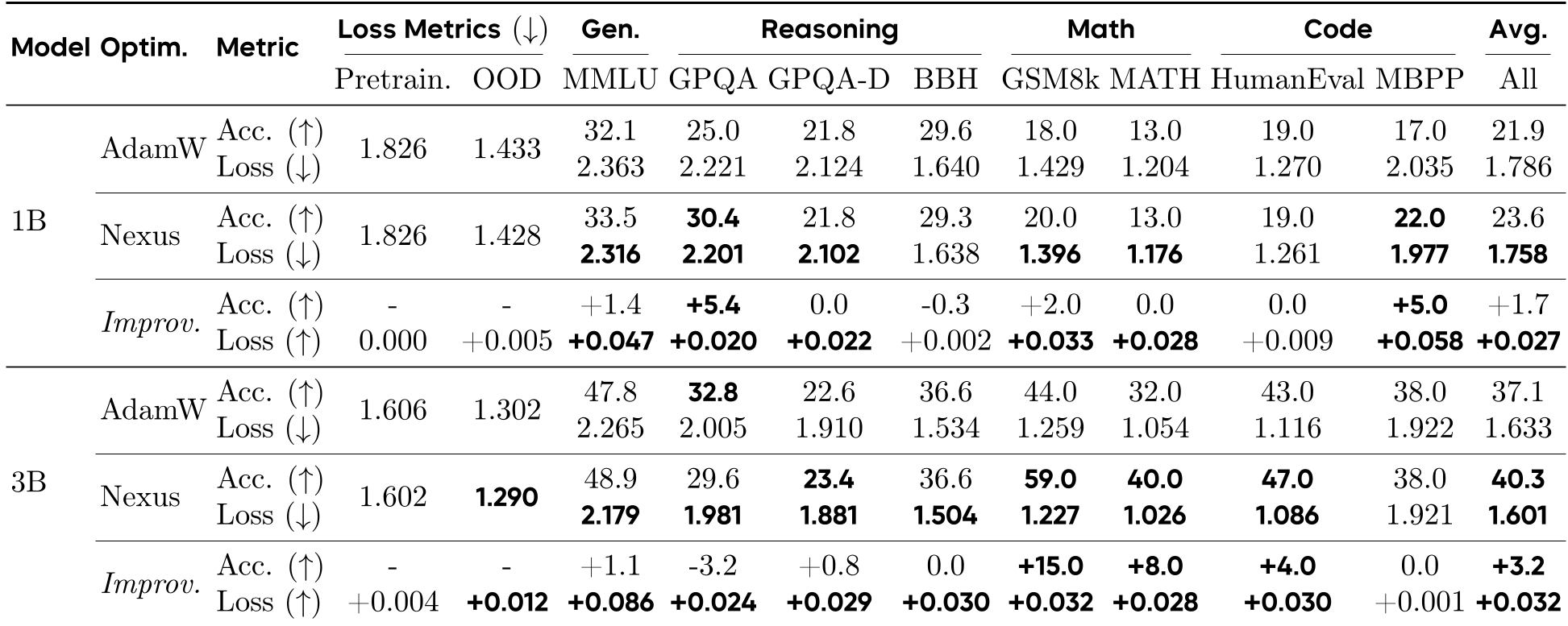
4. 实验战绩:规模越大,奇迹越多
Nexus 最令人兴奋的特性是它的 Scaling Law。随着模型参数从 130M 增加到 3B,Nexus 带来的增益不仅没有消失,反而呈现单调增长。
- 推理神力:在 3B 模型上,GSM8k 准确率从 44.0% 直接飙升至 59.0%。
- 无伤提升:查看下图 (a) 和 (b) 就会发现,Nexus 的预训练 Loss 曲线与 AdamW 几乎重合,但下游任务表现(如推理、数学)却大幅领先。
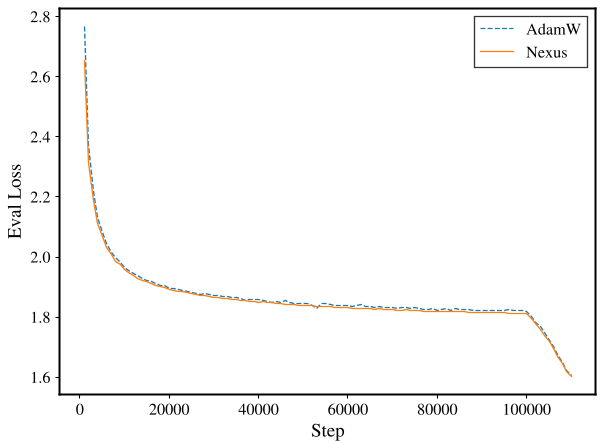 左一:几乎重合的预训练 Loss;右侧:大幅领先的下游能力指标
左一:几乎重合的预训练 Loss;右侧:大幅领先的下游能力指标
5. 深度洞察:为什么它比 Muon 更有效?
最近社区热议的 Muon 优化器通过正交化加速收敛,但作者通过可视化发现(图 7a),Muon 的泛化提升主要依赖于“更低的预训练 Loss”。而 Nexus 开启了另一条赛道:在 Loss 无法进一步下降的数据平原(Data-bound regime)上,通过调整收敛质量来挖掘能力。
6. 局限性与展望
尽管 Nexus 在 AdamW 上表现完美,它目前与 Muon 的兼容性仍存在挑战,且对于超大规模(如 70B+)模型的验证尚在进行中。
总结语:这项工作告诉我们,大模型的成功不只是“炼丹”数据的堆砌,更关乎在复杂的 Loss 迷宫中选择哪一个终点。Nexus 为我们寻找那个最具泛化能力的“共同极小值”指明了方向。