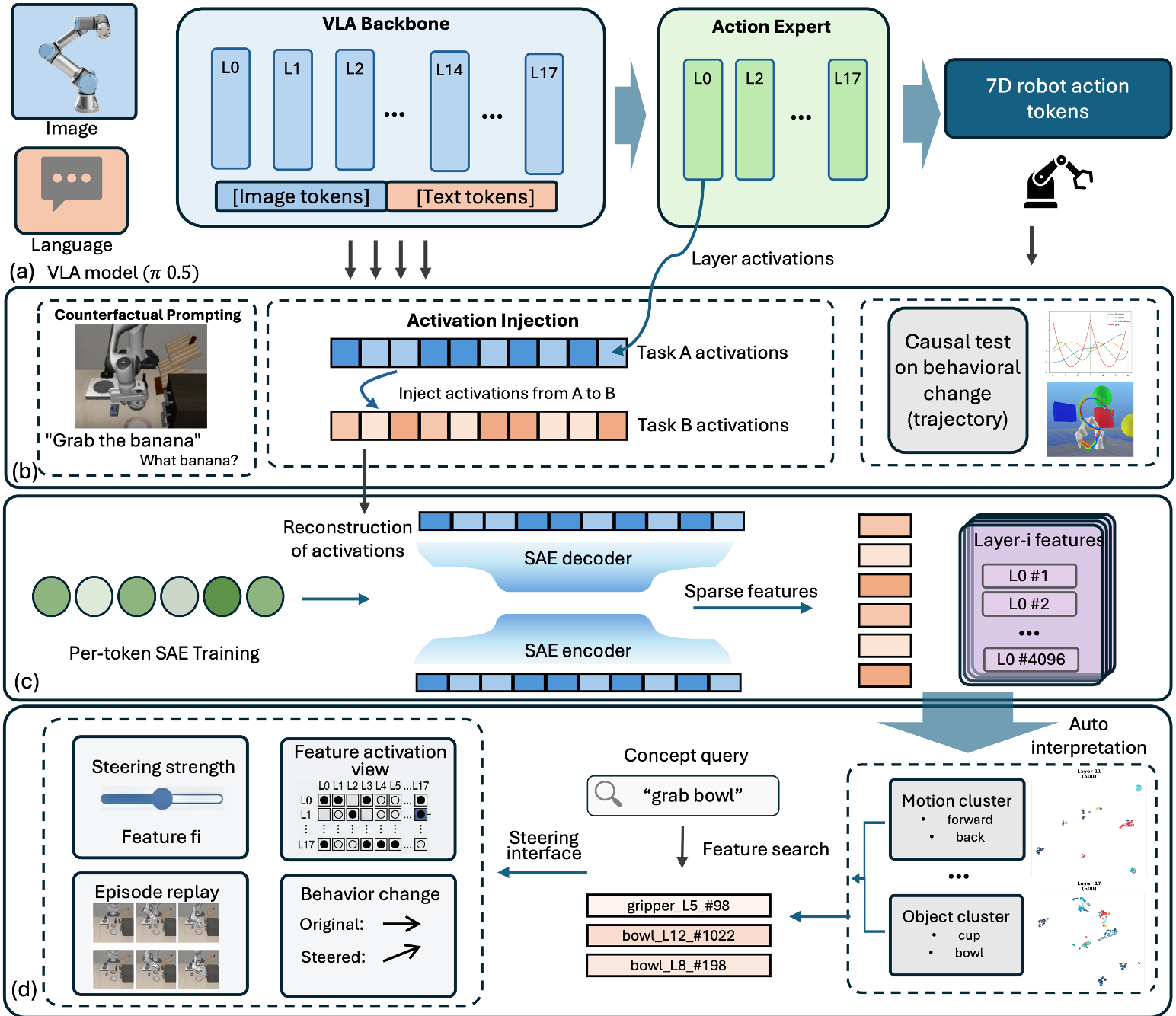
本文对六种主流 Vision-Language-Action (VLA) 模型(如 π0.5, OpenVLA, GR00T 等)进行了首次大规模机械可解释性(Mechanistic Interpretability)研究。通过 activation injection 和 sparse autoencoders (SAEs) 等技术,揭示了视觉路径在行动生成中的主导地位,并发现了模型内部存在功能特化。
TL;DR
通过对 80M 到 7B 参数规模的六种主流 VLA 模型进行 39 万次 Rollout 实验,研究人员发现:视觉路径(Visual Pathway)在决策中占据了绝对统治地位。模型往往会忽略复杂的语言指令,转而执行由视觉场景触发的空间位置动作序列。此外,通过 Sparse Autoencoders (SAEs),研究者首次识别出 82+ 种操作概念,并证实了多路径模型(如 π0.5 和 GR00T)中存在明确的“分工”机制。
背景定位:从行为观察走向白盒诊断
目前的机器人 VLA 模型大多被视为黑盒。当机器人“拿错了杯子”,开发者无从得知是因为视觉编码器没看清,还是语言模型理解错了指令。本文通过 Mechanistic Interpretability(机械可解释性) 工具,试图在神经元层面拆解这些模型的决策回路。
痛点深挖:语言指令真的起作用吗?
研究者的核心动机在于验证模型是否真的在“听命行事”。他们发现,在很多任务中,即使把语言指令清空(Null Prompts),模型依然能通过视觉场景识别出意图。这暗示了当前 VLA 模型存在严重的“视觉-运动先验(Visual-motor priors)”偏好,而非真正的指令遵循。
核心方法论:SAEs 与激活注入
1. 跨架构的对比实验
作者研究了包含 π0.5, OpenVLA-OFT, X-VLA, SmolVLA, GR00T 和 ACT 在内的六类代表性架构,涵盖了 Flow matching、连续回归和 CVAE 等主流生成范式。
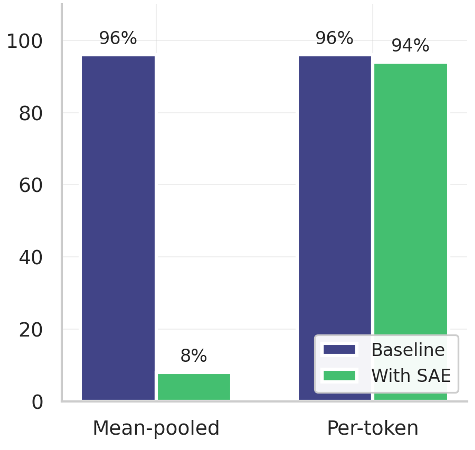
2. 逐 Token (Per-Token) SAE 处理
研究发现,VLA 的激活处理与 LLM 有本质不同。如果在 SAE 处理时直接使用均值池化(Mean-pooling),会摧毁模型的时间结构,导致任务成功率从 96% 暴跌至 8%。逐位置(Per-token)处理是保持机器人动作保真度的关键。
核心发现:三条重磅结论
结论一:视觉路径的“霸权”
实验表明,将成功的激活(Activation)注入到错误的指令甚至空指令中,机器人几乎能 100% 恢复基准表现。这证明了运动程序是绑定在视觉坐标上的,而非语言语义上的。
结论二:功能特化(Pathway Specialization)
在 π0.5 和 GR00T 等多路径架构中,模型表现出了惊人的分工:
- 专家路径 (Expert Pathway):编码“如何做(How)”,即具体的运动参数。
- VLM 路径:编码“做什么(What)”,即目标的语义信息。
专家路径注入导致的机器人位移量是 VLM 路径的 2 倍以上,这种特化为后续的运行时故障诊断奠定了基础。
结论三:空间绑定的脆弱性
跨任务注入(Cross-task Injection)显示,如果把任务 A 的激活强行注入任务 B,机器人会试图移动到任务 A 目标所在的坐标点,即使那个点现在什么也没有。这种“刻舟求剑”的行为揭示了当前模型缺乏对物体间关系的抽象建模。
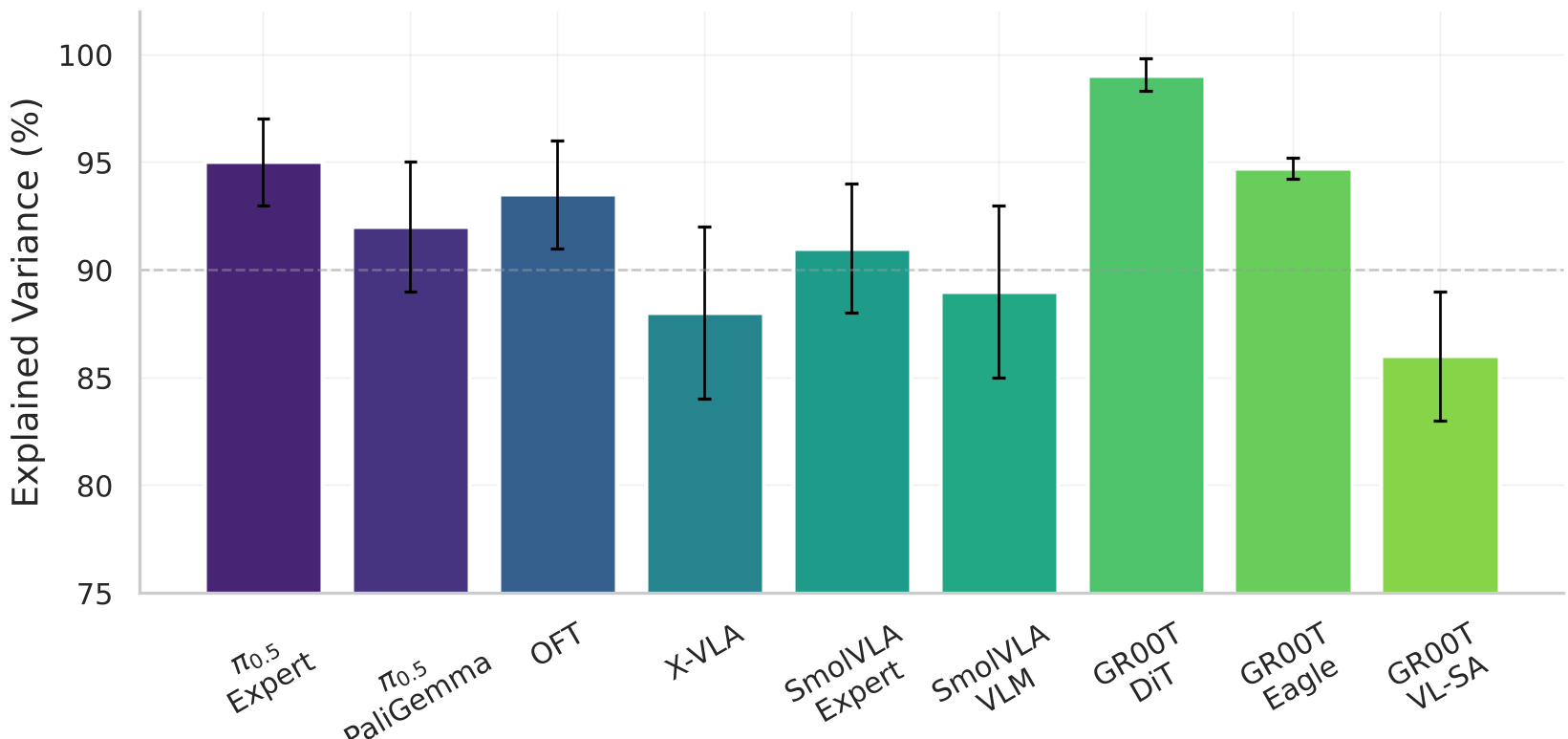
实验结果对比
在 LIBERO 各种基准测试中,研究者通过消融实验(Ablation Study)证实了单一关键特征(Kill-switch features)的存在——只需抹除一个 SAE 特征,模型成功率即可能降至零。
深度总结与展望
这篇文章不仅是 VLA 领域的一次大规模“核磁共振”,更提出了一个警示:当前的 VLA 模型在表征上很丰富,但在行为上非常脆弱。
Takeaway:
- 开发者:可以通过监控特定路径的神经元活跃度来提前预警机器人的失控。
- 研究者:未来的对齐方法不应仅停留在输出端,应该关注如何打破模型对“空间坐标”的死记硬背,转向真正的关系抽象。
作者同步开源了 Action Atlas,读者可以交互式地探索六大模型中的 82+ 种操作概念。